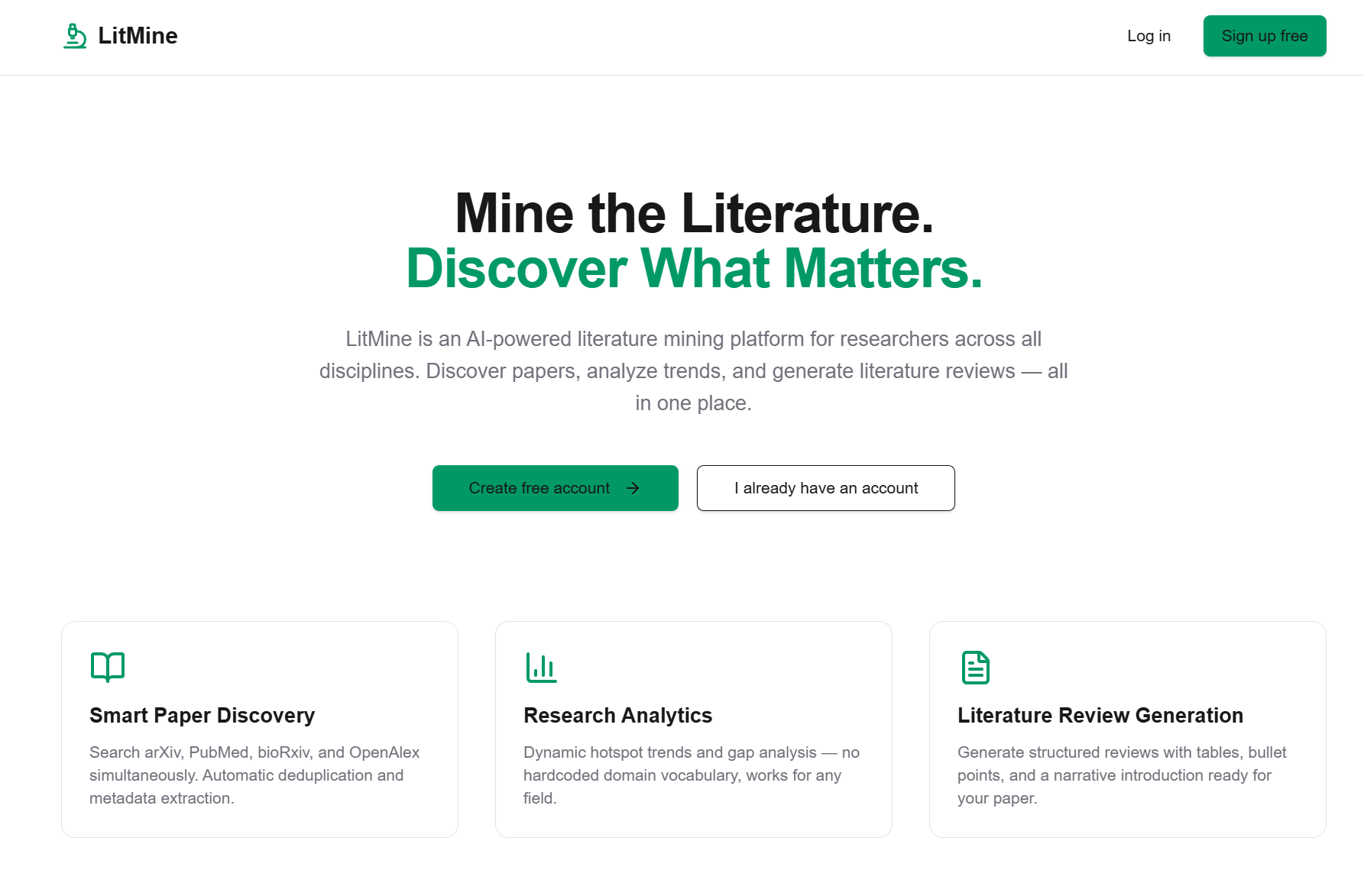

AI-powered literature mining and research analytics platform for researchers across all disciplines.
LitMine is an AI-powered platform that helps researchers complete literature surveys faster. It does not rely on any preset domain vocabulary — whether you work in synthetic biology, materials science, or social sciences, LitMine extracts keywords from your paper corpus automatically, identifies research hotspots, finds gaps, and generates structured literature reviews.
The traditional literature survey workflow — searching PubMed / Google Scholar paper by paper → manually organizing notes → judging hotspots and gaps yourself → writing the review — is compressed by LitMine into minutes.
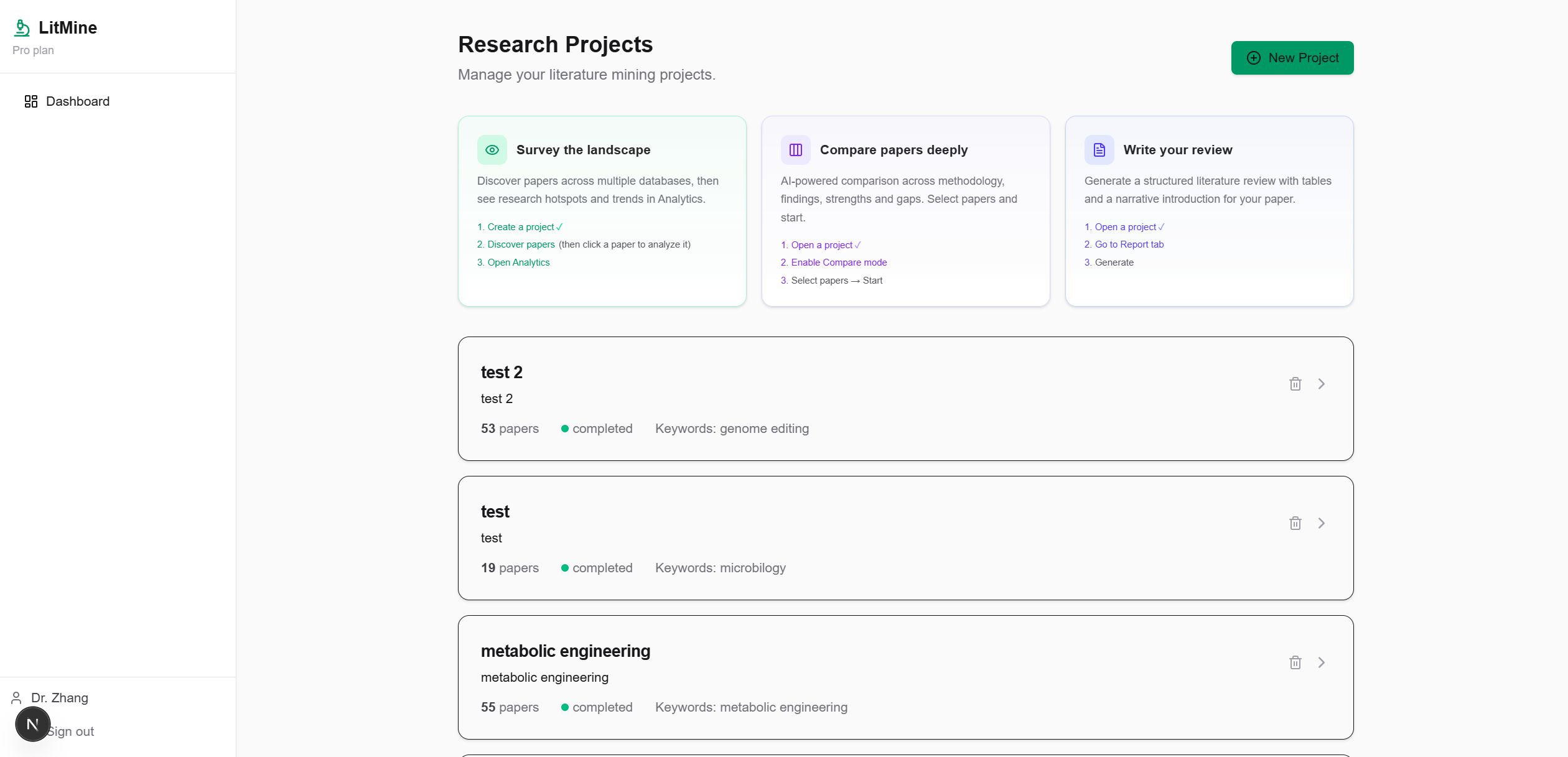
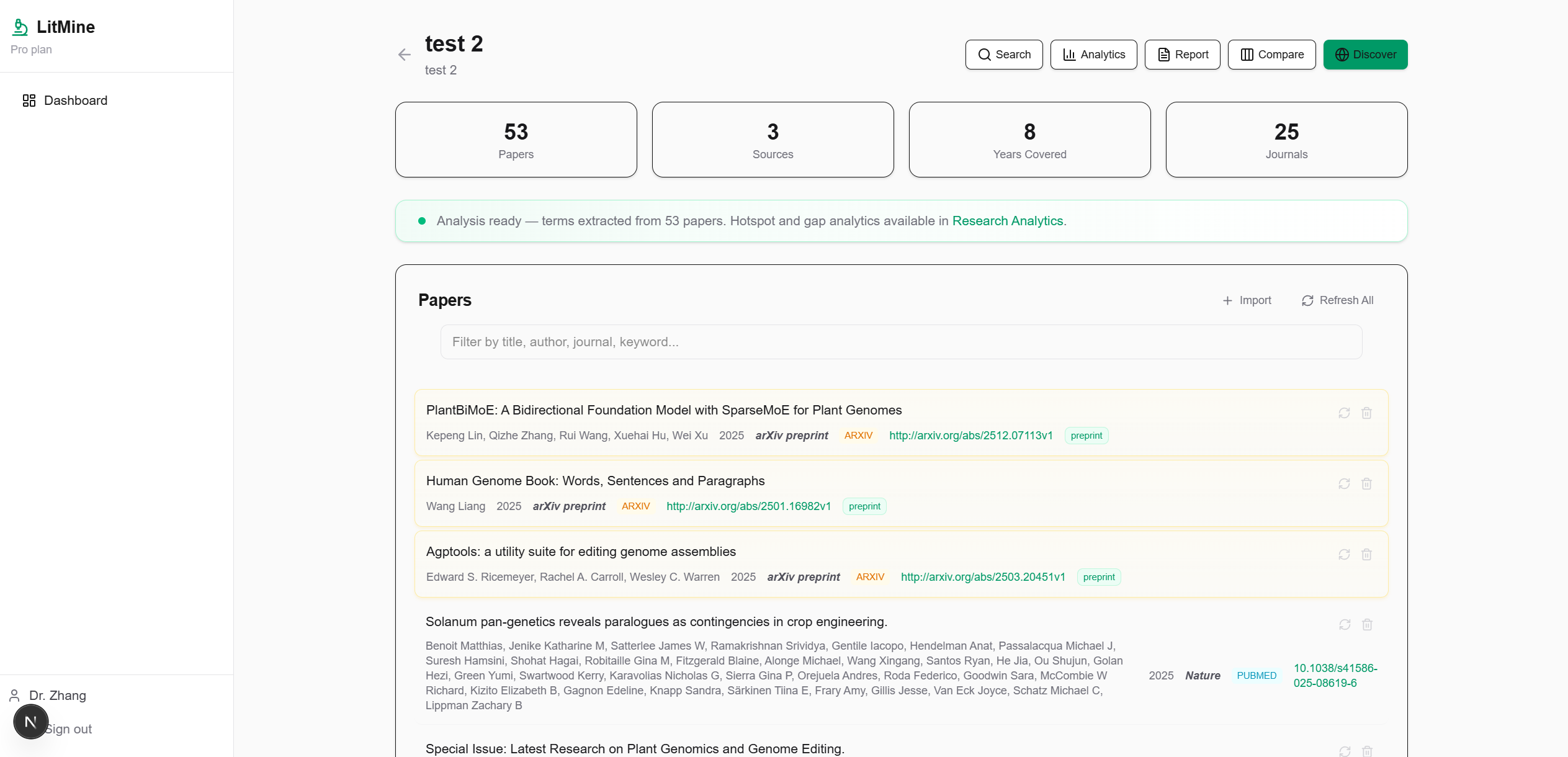
- Paper Discovery — Search across arXiv, PubMed, bioRxiv, and OpenAlex simultaneously with automatic deduplication and metadata backfill
- Paper Import — Upload PDFs (auto-parsed via GROBID for title, authors, abstract, DOI), paste DOI links, or import BibTeX/RIS files
- Multi-language Translation — Translate paper titles and abstracts into Chinese, Japanese, Korean, Spanish, or Italian. Results cached to database — no repeated API calls
- AI Deep Analysis — Seven-dimension analysis: summary, core contribution, methodology, key results, key takeaways, limitations, and deep insights
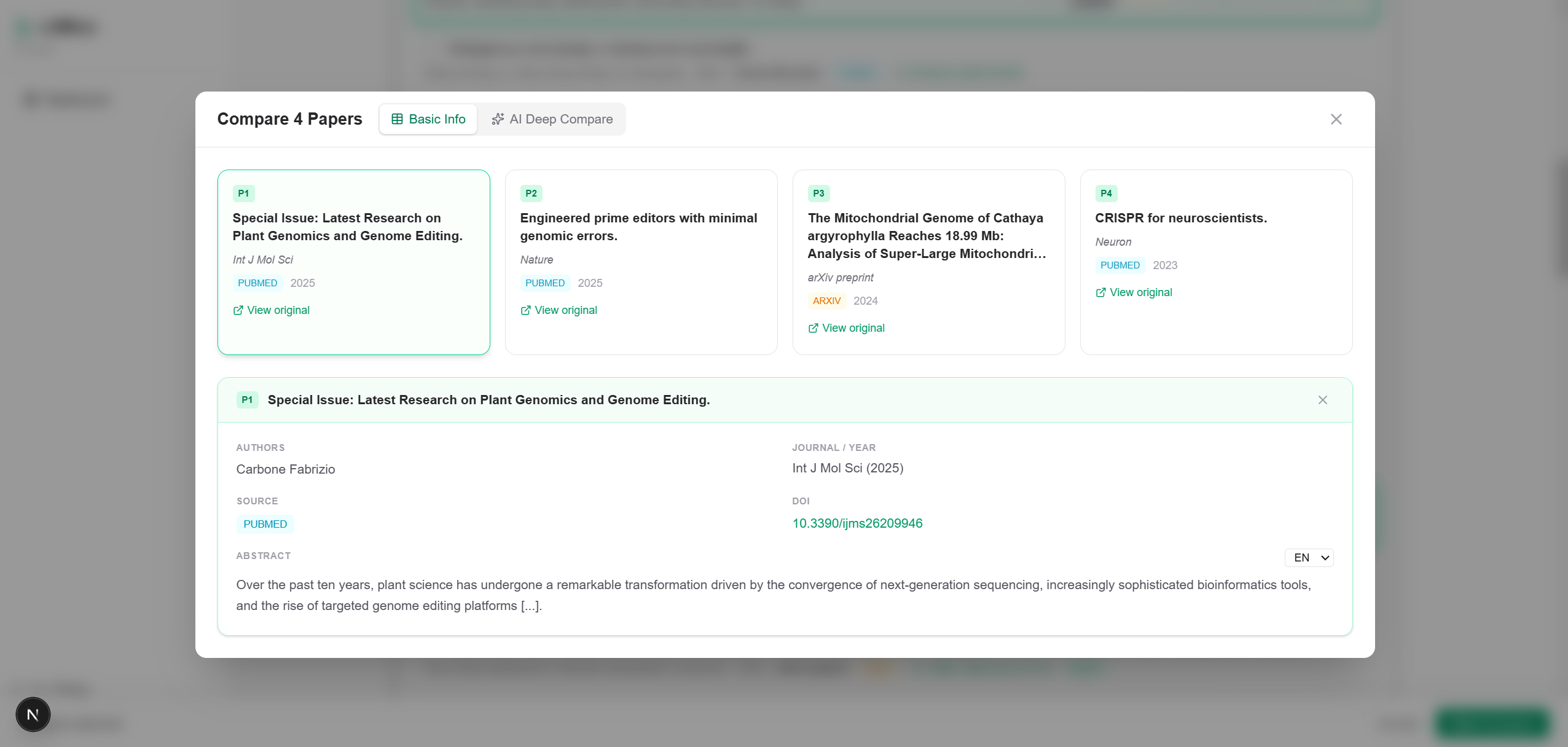
- Paper Comparison — Select multiple papers and let AI compare methodology, findings, strengths, limitations, and research gaps
- Chat with Paper — Ask questions about any paper and get contextual answers
- Research Hotspots & Gaps — Dynamic TF-IDF term extraction + trend slope sorting. Works for any research direction — no hardcoded vocabulary
- Literature Review Generation — 5-section structured report with three-line academic tables and a narrative introduction section ready for your paper
- Full-platform Multi-language — Translation, analysis, comparison, and reports all support six languages (EN/ZH/JA/KO/ES/IT)
- 3-container Deployment — PostgreSQL + Redis + GROBID,
docker compose up -dto start

- Docker Desktop
- Node.js 18+
- Python 3.11+
- An LLM API key (DeepSeek, OpenAI, Gemini, Anthropic, OpenRouter, Qwen, or Kimi — see LLM Settings in-app)
docker compose up -dStarts PostgreSQL (with pgvector extension), Redis, and GROBID.
cd apps/api
cp .env.template .env # edit .env — (optional) set a server-default LLM API key
pip install -e .
alembic upgrade head
uvicorn app.main:app --host 0.0.0.0 --port 8000 --reloadcd apps/web
npm install
npx next dev --port 3000Visit http://localhost:3000 → register an account → create your first project → Discover papers.
litmine/
├── apps/
│ ├── api/ # FastAPI backend (Python 3.11+)
│ └── web/ # Next.js frontend (TypeScript)
├── docker-compose.yml
├── README.md
├── README_CN.md
├── ROADMAP.md
└── scripts/
| Layer | Technology |
|---|---|
| Backend | FastAPI + SQLAlchemy + asyncpg |
| Frontend | Next.js 16 (App Router) + TypeScript + Tailwind CSS |
| Database | PostgreSQL 16 + pgvector (semantic search) |
| Cache | Redis |
| PDF Parsing | GROBID 0.8.1 (TEI XML extraction) |
| LLM | DeepSeek (chat + translation + entity extraction) |
| Infra | 3 Docker containers: PostgreSQL, Redis, GROBID |
| Decision | Rationale |
|---|---|
| No Neo4j | Hotspot + Gap charts only; PostgreSQL GROUP BY is faster and lighter |
| No message queue | Single-user context — report generation runs inline; fewer moving parts |
| No object storage | PDFs stored on local filesystem; no external service dependency |
| Dynamic vocabulary | TF-IDF from user's paper corpus; cross-disciplinary seed words for cold start |
| LLM server-side proxy + multi-provider | 7 providers supported (DeepSeek, OpenAI, Gemini, Anthropic, OpenRouter, Qwen, Kimi). User API keys stored locally in browser, all calls routed through backend proxy |
# Backend
cd apps/api && uvicorn app.main:app --reload
# Frontend
cd apps/web && npx next devSee ROADMAP.md for the complete product roadmap and current status.
If LitMine helps your research, consider buying the author a coffee!


WeChat Alipay
- Email: zming19861028@126.com / zming19861028@hotmail.com
- WeChat: zminlibra
- GitHub: zminlibra
LitMine is built on the shoulders of many great open-source projects:
- GROBID — PDF to structured TEI XML extraction
- FastAPI — Python web framework
- Next.js — React framework
- Tailwind CSS — Utility-first CSS
- PostgreSQL + pgvector — Database & vector search
- Recharts — Charting library
- DeepSeek — LLM API
- All early-stage testers and colleagues who provided critical feedback during Phase 1–4
MIT © 2025–2026