选题方向:经典自动化测试方向
18SE,张卓楠
20秋NJUSE自动化测试经典自动化测试大作业项目
测试选择是一项常见的回归测试优化手段。而程序分析作为认识程序的常用技术,被广泛应用于测试选择技术的自动化 。根据程序分析的手段不同,测试选择可以分为静态选择和动态选择两种。本项目要求同学实现一个静态测试选择工具,能够根据代码变更自动选取出受变更影响的测试( Impacted Tests)。完整的静态测试选择流程大致可以分为三个主要阶段:
- 变更检测阶段:以某项指标(文件的检验和或依赖关系)为基准,判定哪些生产代码产生了变更。一般来说,基准发生变化的生产代码就是产生变更的部分
- 静态分析阶段:使用静态分析工具构建生产代码与测试代码之间的联系,得到代码依赖图;
- 测试选择阶段:根据代码关系图和变更信息,筛选出受变更的测试。
为降低难度,第一阶段(变更检测)无需实现【给出了changeInfo.txt】,只需要实现一个能满足2、3阶段需求的简易测试选择工具即可
- JAVA语言、Maven构建
- 静态程序分析全部采用WALA框架(<=1.5.5),关于WALA介绍见后
- 实现类和方法两种粒度的依赖分析,实现方法介绍见后
- 生成可以运行的jar包:testSelection.jar
- 类级:
java -jar testSelection.jar -c <project_target> <change_info> - 方法级:
java -jar testSelection.jar -m <project_target> <change_info> - 指令参数说明
- <project_target>:String,待测项目的target文件夹路径,程序读取该文件夹下所有.class文件并添加到AnalysisScope中
- <change_info>:String,记录变更信息的文本文件记录,每行一个方法签名,表示发生变更的代码
- 类级:
本项目提供两组输入数据,每组数据包含5个符合maven结构的待测项目,每个待测项目内含1个变更文件(change_info.txt)其中:
- 第一组数据:学生可见,用于调试项目、保证项目功能的正确性;
- 第二组数据:学生不可见,用于评分。
- 变更文件内含变更信息,每行一个方法签名,表示发生变更的生产代码;
实现的工具应该能够将测试选取结果记录到文本文件中,并输出到 jar包所在的目录下(即“ “./”)。 输出文件每行一个方法签名,表示一个受测试影响的方法。指令一和指令二的输出应该分别命名为 selection-class.txt 和 selection-method.txt
- 代码依赖图10%,代码60%;jar包运行情况30%
- 提交github链接,检查时候fork
- 目录结构
- Demo目录:testSelection.jar
- Report目录:针对第一组数据生成10个代码依赖图(PDF),每个项目对应类级/方法级代码依赖各一个
- 命名格式为
class-项目名.pdf和method-项目名.pdf - 可以项目生成dot文件,通过graphviz转化为pdf文件,不要求自动化实现
- 命名格式为
- Project目录:存放项目代码,逻辑+注释
参考:https://github.com/wala/WALA
主要配置文件有以下三个:wala_config.zip
- wala.properties
- wala属性文件,记录了运行wala所需要的一些环境配置
- 需要将
java_runtime_dir改为自己的java jdk路径
- scope.txt
- 域配置文件,与静态分析的范围AnalysisScope 有关。WALA提供了读取配置文件和直接添加类文件进入分析域两种构建分析域的手段, scope.txt 就和第一种方式相关,详细教程见:http://wala.sourceforge.net/wiki/index.php/UserGuide:AnalysisScope
- WALA的开发团队虽然声称能够支持源代码的程序分析,但实际应用中基本上都是使用字节码文件(.class)作为静态分析的材料,这和Java语言本身的特性有关。本项目要求同学们以字节码为分析材料
- 推荐结合两种方式构建分析域,文档的后面会进一步说明
- exclusions.txt
- 排除配置文件,与静态分析的范围AnalysisScope 有关。改文件记录了一些静态分析中不关心的类。文件每行一条记录,支持正则表达式,表示在本次静态分析中排除在外的类
- ⚠ 注意: 静态分析的计算复杂度较高,通过exclusion.txt 可以有效地缩减分析域、提高分析效率。但排除过多的类可能会丢失一些分析必须的类,导致抛出异常。因此推荐同学使用makeWithRoot 的方式构建类层次对象,文档的后面会进一步说明使用Maven项目构建,三个配置文件放在/src/main/resources下
注意,适用于版本<=1.5.4
推荐同时使用两种方式综合构建AnalysisScope 对象,涉及到两个方法两个步骤:
AnalysisScopeReader.readJavaScope(scopePath, new File(exPath), classLoader);
保持配置样例中scope.txt 的内容不变,该方法能够返回一个只包含Java原生类的分析域,并排除一些不常用的原生类(如:sun.awt.* )
scope.addClassFileToScope(ClassLoaderReference.Application, clazz);
scope 是一个AnalysisScope 对象, clazz 是一个我们想要加入分析域的类文件对象。这行代码能够将我们想要分析的类动态地加入到分析域中。
类层次生成方法由工厂类ClassHierarchyFactory 提供,以分析域对象为构建原料,这里推荐使用makeWithRoot 方法构建类层次对象:
ClassHierarchy cha = ClassHierarchyFactory.makeWithRoot(scope);
在缺失了某些分析所需的类时, makeWithRoot 方法会尽可能地为依赖这些缺失类的方法添加“Root”,即认为java.lang.Object 为这些类的父类。
进入点和我们分析的兴趣的有关,以分析域和类层次对象为构建原料。WALA内置了若干种进入点集合,如:
- 针对主程序生成进入点:
Util.makeMainEntryPoints - 针对所有Application类(非原生类)生成进入点:
new AllApplicationEntrypoints(scope,cha)
此外,还支持自定义进入点,可以通过实现自己的进入点子类实现。为了降低实现难度,这里推荐大家使用AllApplicationEntrypoints 构建进入点。
本项目要求完成两种粒度的依赖分析(同时这也是实现两种粒度的测试选择的基础),而依赖分析通常和构建调用图有关,这里推荐两种构建调用图的方法:
- CHACallGraph :使用类层次分析(Class Hierarchy Analysis)算法构建调用图。该方法构建的调用图精度较低,但是速度较快,构建例子如下:
CHACallGraph chaCG = new CHACallGraph(cha);
chaCG.init(new AllApplicationEntrypoints(scope, cha));- 使用0-CFA算法,通过上下文无关的方式构建调用图。相比于第一种方法构建的调用图,该方法构建的调用图精度更高,但同时速度更慢。构建例子如下:
ClassHierarchy cha = ClassHierarchyFactory.makeWithRoot(scope);
AllApplicationEntrypoints entrypoints = new AllApplicationEntrypoints(scope,cha);
AnalysisOptions option = new AnalysisOptions(scope, entrypoints);
SSAPropagationCallGraphBuilder builder = Util.makeZeroCFABuilder(
Language.JAVA, option, new AnalysisCacheImpl(), cha, scope);此外,WALA还支持有很多种其他调用图构建算法,如RTA、1-CFA等。同学们也可以查阅资料学习后自行实现。
生成数据使用的测试选择代码采用0-CFA算法进行调用图构建( Util.makeZeroCFABuilder ),也可以使用CHA算法构建调用图( new CHACallGraph )
每个项目文件夹下都有一个data/ 目录,里面存放了样例数据。除CMD 外,其他5个项目给出的数据包括:
- **change_info.txt **,变更信息文件。每行一条记录,格式为<类的内部表示> <方法签名> ,模拟发生变更的生产代码,作为测试选择的输入之一。本文档将在相关知识部分详细介绍类的内 部表示形式和方法签名;
- selection-class.txt 和selection-method ,两种不同粒度的测试选择结果。每行一条记录,格式为<类的内部表示> <方法签名> ,表示一个被选中的测试方法,表示程序的输出。同学们可以参考这两个文件调试程序。注意:由于程序的内部实现细节不同可能会导致输出有所差别,同学们应该保证测试选择的结果和代码依赖图能够对应上;【不一定跟文件对的上,但一定和代码依赖图对的上】
- 提示:每一条用于表示某个方法<类的内部表示> <方法签名> 的记录都是通过WALA得出,同学们可以参考以下步骤以获取到类似的信息
/* 省略构建分析域(AnalysisScope)对象scope的过程 */
// 1.生成类层次关系对象
ClassHierarchy cha = ClassHierarchyFactory.makeWithRoot(scope);
// 2.生成进入点
Iterable<Entrypoint> eps = new AllApplicationEntrypoints(scope, cha);
// 3.利用CHA算法构建调用图
CHACallGraph cg = new CHACallGraph(cha);
cg.init(eps);
// 4.遍历cg中所有的节点
for(CGNode node: cg) {
// node中包含了很多信息,包括类加载器、方法信息等,这里只筛选出需要的信息
if(node.getMethod() instanceof ShrikeBTMethod) {
// node.getMethod()返回一个比较泛化的IMethod实例,不能获取到我们想要的信息
// 一般地,本项目中所有和业务逻辑相关的方法都是ShrikeBTMethod对象
ShrikeBTMethod method = (ShrikeBTMethod) node.getMethod();
// 使用Primordial类加载器加载的类都属于Java原生类,我们一般不关心。
if("Application".equals(method.getDeclaringClass().getClassLoader().toString())) {
// 获取声明该方法的类的内部表示
String classInnerName = method.getDeclaringClass().getName().toString;
// 获取方法签名
String signature = method.getSignature();
System.out.println(classInnerName + " " + signature);
}
else{
System.out.println(String.format("'%s'不是一个ShrikeBTMethod:%s",
node.getMethod(),node.getMethod().getClass());
}
}
}除常规的输入输出文件外, 0-CMD/data/ 还包含四个依赖图文件,即class-CMD-cfa.dot 、class-CMD-cfa.pdf 、method-CMD-cfa.dot 和method-CMD-cfa.pdf ,分别对应两种粒度。可以参照依赖图文件格式生成自己的依赖图文件,并在配置好graphviz 环境变量后参考下面命令行生成PDF格式的依赖图:
dot -T pdf -o <文件名>.pdf <文件名>.dot所有项目均具有Maven项目结构,这里建议同学们使用字节码( .class )作为程序分析的原料。每个项目编译出的字节码文件在target/ 目录下,其中:生产代码在target/classes/ 下,测试代码在target/test-classes 下。字节码文件缺失的同学在pom.xml 所在目录下,使用以下命令重新生成target 目录:
mvn clean test介绍JAVA字节码的相关知识,参考:https://asm.ow2.io/ 更多知识请参阅JVM规格说明:https://docs.oracle.com/javase/specs/jvms/se8/html/
java程序需要先编译成字节码文件( .java → .class ),然后才能在Java虚拟机上运行。.class和.java 表示一个类型的方法有所不同,一般使用类型描述符(Type Descriptor)表示一个类。在这里我们将.class 文件中类型的表示方式称作内部表示。
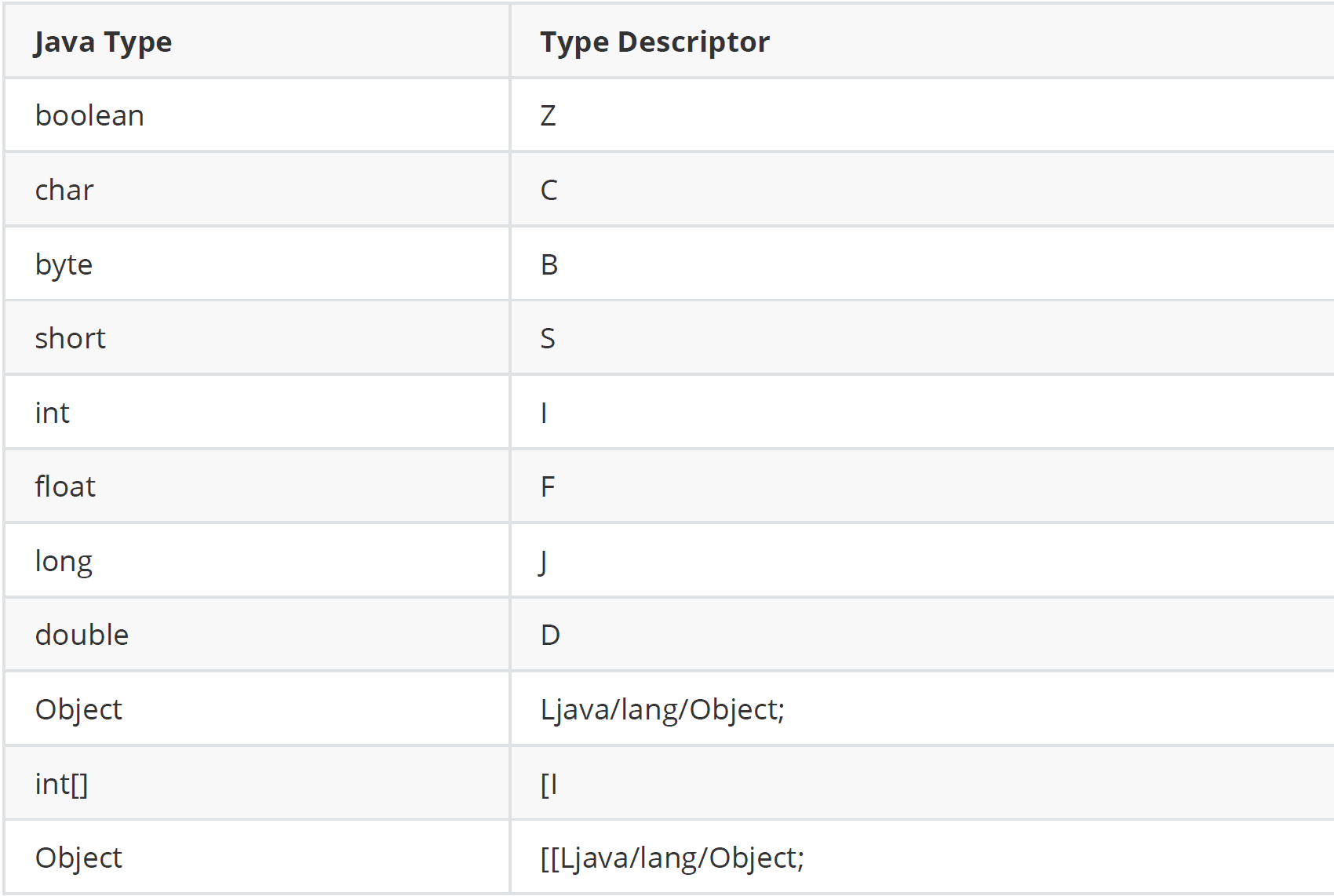
- 基本类型的类型描述符都是单个字符
- 类类型的类型描述符是以“L”开头,“;”结尾的字符串
- 数组类型的描述符以“[”开头
由于允许递归嵌套(例如List<List> ),泛型的语法十分复杂,文档中仅展示了部分语法。本项目使用到的方法签名均由WALA生成。由于分析的代码比较简单,大多不涉及泛型。方法签名的基本表示形式可以归纳为: <声明类>.<方法签名>对泛型的详细规定可以在JVM规格说明中找到。










参考:https://blog.csdn.net/briblue/article/details/54973413
动态加载.class文件到JVM中,主要是一种加载机制
- **Bootstrap ClassLoader **最顶层的类加载器,主要加载核心类库
- Extention ClassLoader 扩展类的类加载器
- Appclass Loader 也称为SystemAppClass,加载当前应用的classpath中的所有类
- BootstrapClassLoader、ExtClassLoader、AppClassLoader实际是查阅相应的环境属性
sun.boot.class.path、java.ext.dirs和java.class.path来加载资源文件的
- 每个类都有一个父加载器
- AppClassLoader的父加载器是ExtClassLoader
- ExtClassLoader的parent是null
- Bootstrap CLassLoader可以作为ExtClassLoader的父加载器
- ClassLoader.getParent()有两种情况
- 由外部类创建ClassLoader时直接指定一个ClassLoader为parent。
- 由
getSystemClassLoader()方法生成,也就是在sun.misc.Laucher通过getClassLoader()获取,也就是AppClassLoader。直白的说,一个ClassLoader创建时如果没有指定parent,那么它的parent默认就是AppClassLoader。
JVM初始化sun.misc.Launcher并创建Extension ClassLoader和AppClassLoader实例。并将ExtClassLoader设置为AppClassLoader的父加载器。Bootstrap没有父加载器,但是它却可以作用一个ClassLoader的父加载器。比如ExtClassLoader。这也可以解释之前通过ExtClassLoader的getParent方法获取为Null的现象。
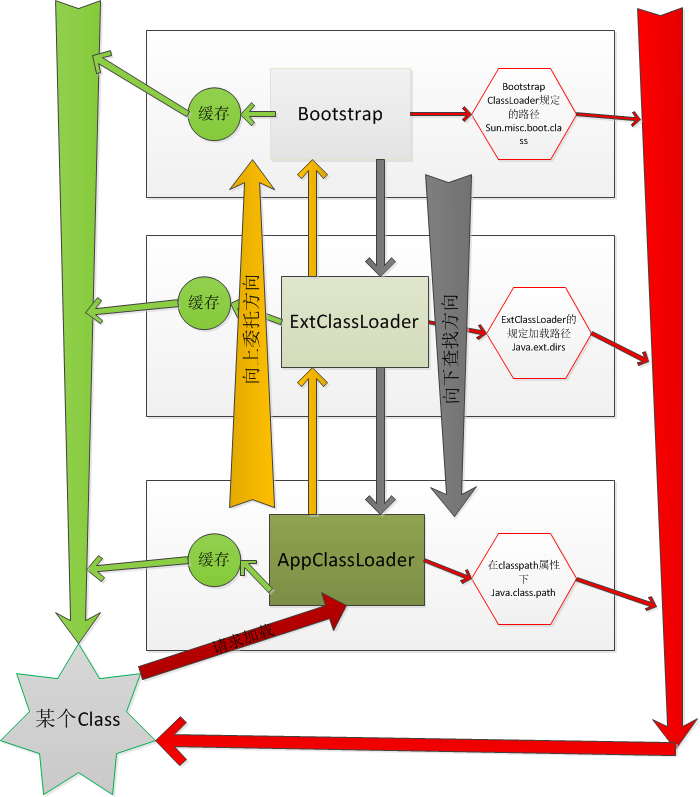
- 一个AppClassLoader查找资源时,先看看缓存是否有,缓存有从缓存中获取,否则委托给父加载器。
- 递归,重复第1部的操作。
- 如果ExtClassLoader也没有加载过,则由Bootstrap ClassLoader出面,它首先查找缓存,如果没有找到的话,就去找自己的规定的路径下,也就是
sun.mic.boot.class下面的路径。找到就返回,没有找到,让子加载器自己去找。 - Bootstrap ClassLoader如果没有查找成功,则ExtClassLoader自己在
java.ext.dirs路径中去查找,查找成功就返回,查找不成功,再向下让子加载器找。 - ExtClassLoader查找不成功,AppClassLoader就自己查找,在
java.class.path路径下查找。找到就返回。如果没有找到就让子类找,如果没有子类会怎么样?抛出各种异常。
委托是从下向上,然后具体查找过程却是自上至下
通过指定的全限定类名加载class
通过实现自定义ClassLoader可以实现到指定路径加载class文件,暂时未涉及到就没有细看,可以到参考资料中查看,写的蛮好的!
- ClassLoader用来加载class文件的。
- 系统内置的ClassLoader通过双亲委托来加载指定路径下的class和资源。
- *可以自定义ClassLoader一般覆盖findClass()方法。
- *ContextClassLoader与线程相关,可以获取和设置,可以绕过双亲委托的机制。