![]()
Own the loop, not the framework.
A framework-free agent runtime you can read, run, and leave — a small library you
import and call, plus a visual studio that ejects to plain Python with zero dependency on us.

![]()


Why stateless? • Features • Quickstart • Studio • How it works • Eject • Configuration • Development
Most agent frameworks own your main(), hide control flow behind metaclasses and DAG executors, and obscure the actual prompts. bare-agent is the opposite: a small library — the agent loop, a tool registry, a 3-axis budget, and a LiteLLM gateway, ~600 readable lines — that you import and call. You own the loop. Every prompt is in plain sight. You can always eject to plain Python and run it with zero bare_agent dependency.
On top of the library sits an optional visual studio: wire agents into a chain on a canvas, attach tools, Run and watch tokens stream live, then eject the whole flow to a self-contained agent.py. Local-first — it runs at zero cost on Ollama; OpenAI, Anthropic, and Gemini are optional drop-ins through the same loop.
Built on Python 3.12 · LiteLLM · FastAPI · Next.js 16 — with no agent framework (no LangChain/LangGraph).
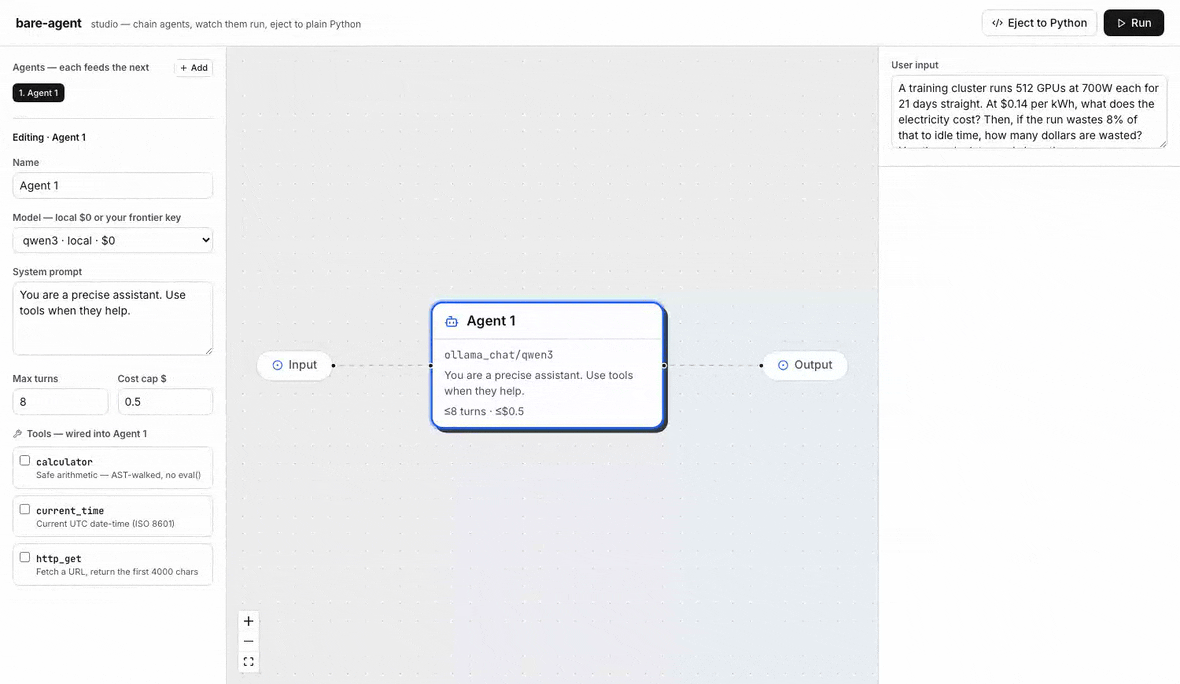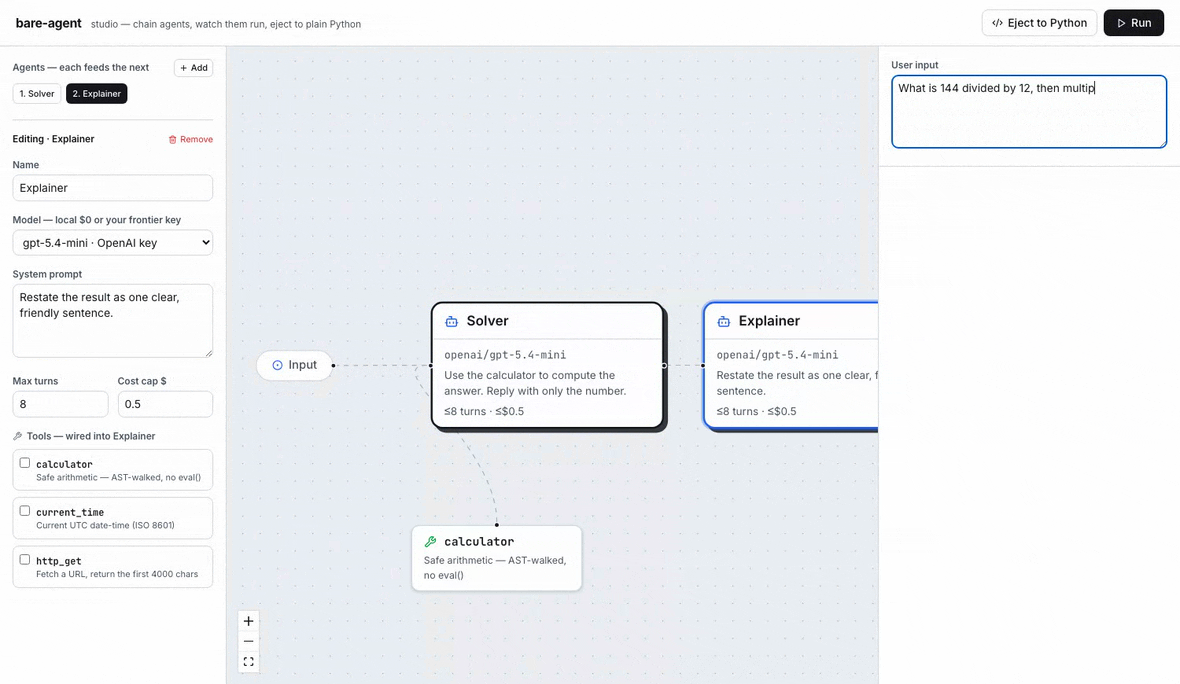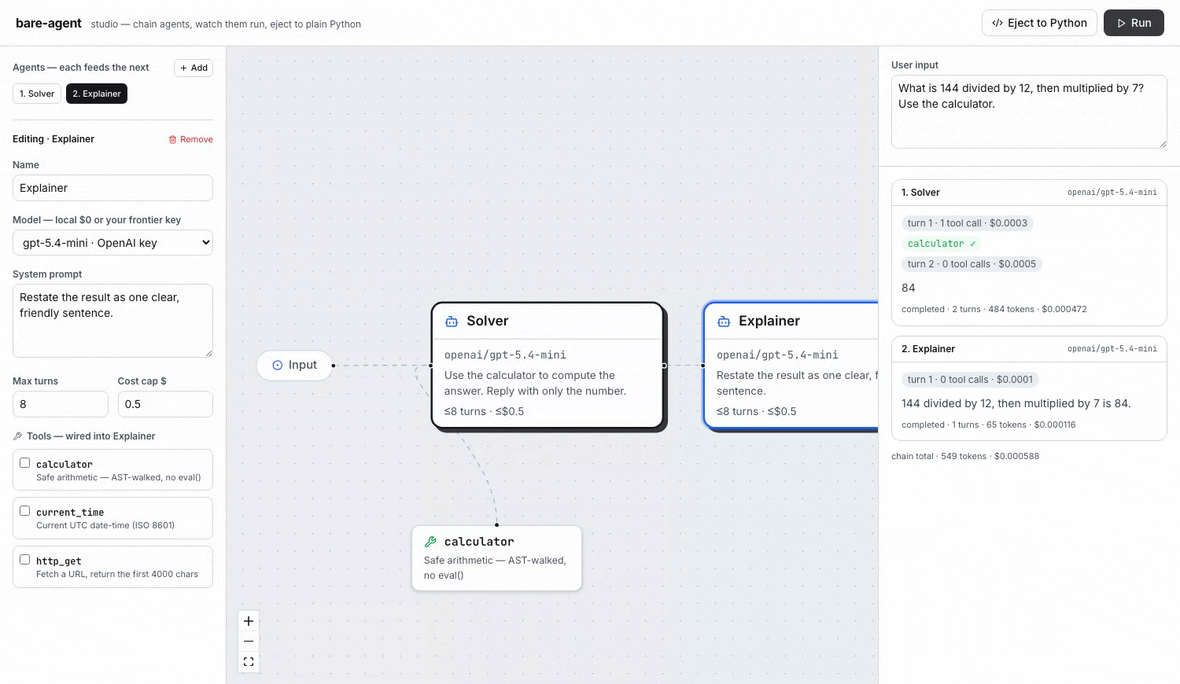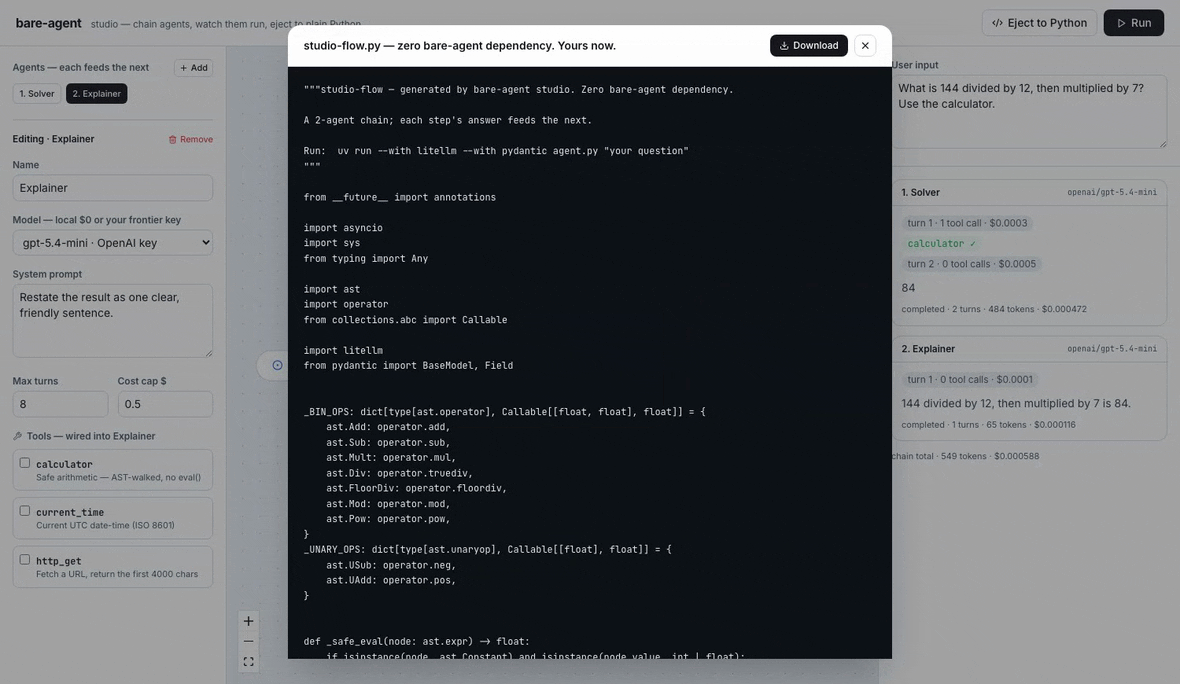
The studio, end to end: chain a Solver and an Explainer, attach the calculator, Run and watch each agent stream its turns, tool calls, and tokens live — with real per-call cost attribution (here on gpt-5.4-mini, ~$0.0006 for the whole chain) — then Eject to Python, a self-contained agent.py with zero bare_agent dependency. The same loop runs local-first on Ollama at $0.
The agent loop is a stateless reducer over an explicit messages: list[dict]. This is the most important design decision in the library, and it was made deliberately. Here is what it costs (nothing) and what it pays (three things):
The cost: you pass the messages list explicitly. There is no magic session object accumulating state behind the scenes.
What you get for free:
Feed a canned messages list and a fake CompletionClient — assert on the result. Every one of the 29 tests runs hermetically: no Ollama daemon, no Redis, no LLM API key required. The test suite is a CI gate, not a flaky integration smoke.
# How the test suite works — no real LLM
agent = AgentLoop(
registry=registry,
llm=FakeCompletionClient(responses=["The answer is 42."]),
budget=Budget(max_turns=3),
system_prompt="You are a test agent.",
)
result = await agent.run("What is 6 × 7?")
assert result.answer == "The answer is 42."
assert result.stop_reason == "completed"The messages list is a plain Python list of dicts — JSON-serializable by construction. Checkpoint it to Postgres (or a file) after each turn. If the process crashes, deserialize and resume from the last checkpointed step. No workflow engine required. This is the same pattern that Argus uses for DBOS durable execution.
"Eject to plain Python" works because the list is the program — there was never a framework underneath to lift out. The compiled agent.py is not a snapshot of framework state; it is a literal transcription of the loop, with tool sources inlined verbatim. You can read it, diff it, and run it after you stop using bare-agent entirely. That is the point.
What this means in practice: no metaclass magic, no hidden DAG executor, no god-object to subclass, no state trapped in a session. Extensibility is composition — AgentLoop(llm=..., approver=..., registry=...) — not inheritance.
| Capability | Detail |
|---|---|
| Framework-free agent loop | A hand-written tool-use loop over LiteLLM with a 3-axis budget (turns / tokens / wall-clock) + hard cost cap, a retry/fallback ladder, and a self-registering, permission-gated tool registry. |
| Local-first, $0 — or BYO frontier key | Every call goes through LiteLLM, so the model id picks the provider. ollama_chat/qwen3 runs free and offline; anthropic/…, openai/…, gemini/… are drop-ins. No lock-in. |
| Multi-agent chains | Wire agents agent→agent; the runtime topologically orders them and feeds each answer into the next. Inline runs, queued runs, and ejected code all execute the same chain. |
| Visual studio | A React Flow canvas (Next.js 16 / React 19) to build chains, attach tools, and watch turns / tool calls / tokens stream live over SSE — one readable section per agent. |
| Eject to plain Python | Compile any graph to a standalone agent.py (litellm + pydantic only) — tool sources inlined, zero bare_agent import. Machine-checked to compile. |
| HITL / permissions | An Approver gates tool calls allow / ask / deny; successful tool output is wrapped <untrusted_tool_output> for prompt-injection containment. |
| Horizontal scale | An optional Redis-list job queue + worker pool; Kubernetes + KEDA scale workers 0→N→0 on queue depth — the same infrastructure pattern as Argus's searcher fan-out. |
| Composition, not configuration | Seams are Python Protocols — swap the LLM, the approver, or the event sink by passing a different object. No god-object to subclass. |
Each is independently usable — not a god-object:
| # | Primitive | File |
|---|---|---|
| ① | Tool registry — @registry.tool() → JSON-schema → permission-gated dispatch |
registry.py |
| ② | Prompt assembly — the explicit, serializable messages: list[dict] |
loop.py |
| ③ | Agent loop — AsyncExitStack + 3-axis budget + termination + cycle-stop |
loop.py |
| ④ | Retry / fallback over LiteLLM (local Ollama or any frontier model) | llm.py |
| ⑤ | State / memory — checkpoint the messages list (durability for free) |
loop.py |
| ⑥ | HITL / permissions — allow / ask / deny, an Approver on ask |
registry.py |
| ⑦ | Observability — structlog + an optional EventSink (SSE-ready) |
events.py |
| ⑧ | Eval gate — golden replay (roadmap) | — |
pip install bare-agent # or: uv add bare-agentA complete agent in ~30 lines — the docstring becomes the LLM's tool description:
import asyncio
from pydantic import BaseModel, Field
from bare_agent import AgentLoop, Budget, LLMClient, ToolRegistry, get_settings
registry = ToolRegistry()
class AddArgs(BaseModel):
a: int = Field(description="first addend")
b: int = Field(description="second addend")
@registry.tool()
async def add(args: AddArgs) -> int:
"""Add two integers and return their sum."""
return args.a + args.b
async def main() -> None:
settings = get_settings() # local Ollama by default; set BARE_AGENT_MODEL for frontier
agent = AgentLoop(
registry=registry,
llm=LLMClient.from_settings(settings),
budget=Budget.from_settings(settings),
system_prompt="You are a precise assistant. Use tools for arithmetic.",
)
result = await agent.run("What is 17 + 25, then add 100 to that?")
print(result.answer) # -> "142"
print(result.stop_reason, result.turns, f"${result.cost_usd}") # -> completed 3 $0.0
asyncio.run(main())Run it locally for free:
ollama pull qwen3 # one-time
make demo # or: uv run python examples/quickstart.pymake web # FastAPI on :8000 + Next.js studio on :3000 → http://localhost:3000/studioOpen http://localhost:3000/studio: Add agents and wire them into a chain, attach catalog tools, pick a model (local qwen3 at $0 or your frontier key), and Run — each agent streams its turns, tool calls, and tokens live over SSE in its own section. The backend is standalone: make api runs the control plane alone, and the library works with no UI at all.
user input
│
▼
┌──────────────┐ answer feeds ┌──────────────┐
│ Agent 1 │ ───────────────► │ Agent 2 │ ──────────► final answer
│ + tools │ the next │ + tools │
└──────────────┘ └──────────────┘
each agent = ONE hand-written loop:
explicit messages list · 3-axis budget + cost cap · permission-gated tool dispatch
run it: inline over SSE · or queue → worker pool → KEDA scales 0→N→0
keep it: Eject ──► agent.py (litellm + pydantic only — ZERO bare_agent dependency)
Any flow — single agent or a chain — compiles to a standalone script that imports only litellm and pydantic. Tool sources are inlined verbatim; there is no bare_agent import:
uv run --with litellm --with pydantic agent.py "your question"In the studio, Eject to Python shows the generated code and downloads it. The generated file is machine-checked to compile. You can read it, diff it, vendor it, and run it after you stop using bare-agent entirely.
Settings are read by Pydantic Settings from the environment (BARE_AGENT_ prefix) or .env.
| Variable | Default | Purpose |
|---|---|---|
BARE_AGENT_MODEL |
ollama_chat/qwen3 |
LiteLLM model id. Local Ollama by default; anthropic/…, openai/…, gemini/… for hosted. |
BARE_AGENT_OLLAMA_BASE_URL |
http://localhost:11434 |
Ollama server, passed as api_base for ollama_chat/ models. |
BARE_AGENT_FALLBACK_MODELS |
[] |
Ordered fallback model ids (JSON list) for the retry ladder. |
BARE_AGENT_MAX_TURNS / …_TOKENS / …_WALLCLOCK_S / …_COST_USD |
8 / 120000 / 180 / 0.50 |
The 3-axis budget + hard cost cap; the loop stops on the first to trip. |
BARE_AGENT_USE_QUEUE |
false |
Route runs through the Redis queue + worker pool (KEDA-autoscalable) instead of inline. |
BARE_AGENT_REDIS_URL |
redis://localhost:6379/0 |
Redis DSN for the run queue + event pub/sub (queue mode). |
For a hosted model, set BARE_AGENT_MODEL=anthropic/… and export that provider's key (ANTHROPIC_API_KEY, OPENAI_API_KEY, GEMINI_API_KEY).
make ci # lock-check + format-check + lint (ruff) + compile + typecheck (ty) + tests (pytest)
make test # the 29-test suite — hermetic (LLM and Redis are faked; no daemon needed)
make web # backend + studio together for local hacking
make up / down # the Docker stack (api + studio; Ollama stays on the host)
make queue-up # the Docker stack WITH the KEDA-shaped worker plane (+ redis + worker)
make help # all targetsKubernetes manifests live in k8s/ — an inline deploy (api + studio) and the KEDA worker plane (redis + worker). The studio has its own toolchain (apps/studio/AGENTS.md); the canonical agent rules for the whole repo are in AGENTS.md.
MIT © 2026 Subrata Mondal — see LICENSE. Built as the clean, reusable extraction of Argus's agent runtime.