Week 1 : Neural Network Basic
Binary classification := 2개의 class에 대해서 주어진 input이 어떤 class에 속하는지를 결정하는 것
아래의 그림이 input으로 주어지고 2개의 class(고양이, 강아지)가 주어졌다고 생각하자.

이 때 결과값이 강아지 라고 결정된다면, 이것은 Binary classification model이다.
물론 결과값이 고양이 라고 결정되더라도, Binary classification model이다.(틀린 model이겠지만)
Logistic regression := 여러개의 class에 대해서 주어진 input이 각 class에 속할 확률을 결정하는 것
마찬가지로 아래 그림이 input 으로 주어지고 2개의 class(고양이, 강아지)가 주어졌다고 생각하자.
이 때 결과값이 **[고양이일 확률, 강아지일 확률] = [0.9, 0.1]**로 도출된다면, 이것은 Logistic regression model이다.
여기에서 가장 큰 확률을 가진 class를 return 하도록 코딩을 하면 binary classification과 동일한 결과를 얻을 수 있다.
즉 binary classfication은 deterministic 하고, logistic regression은 probabilistic 한 문제를 다루는 것임을 알 수 있다.
직관과는 다르게도 probabilistic 한 문제가 훨씬 풀기 쉽고 다양한 접근법이 있다.(많은 분야에서 그렇다)
사실 우리가 원하는 것은 classification인 경우가 많지만 regression만 하면 classification은 자동으로 따라오므로 딥러닝은 regression을 주로 다룬다.
사실 wiki에다가 쭉 정리해보고 싶었는데.... 수식이 진짜 오바다..... LaTex로 전부 적으려니깐 토나와서 그냥 pdf 통째 이미지로 올려버린당ㅎㅎ
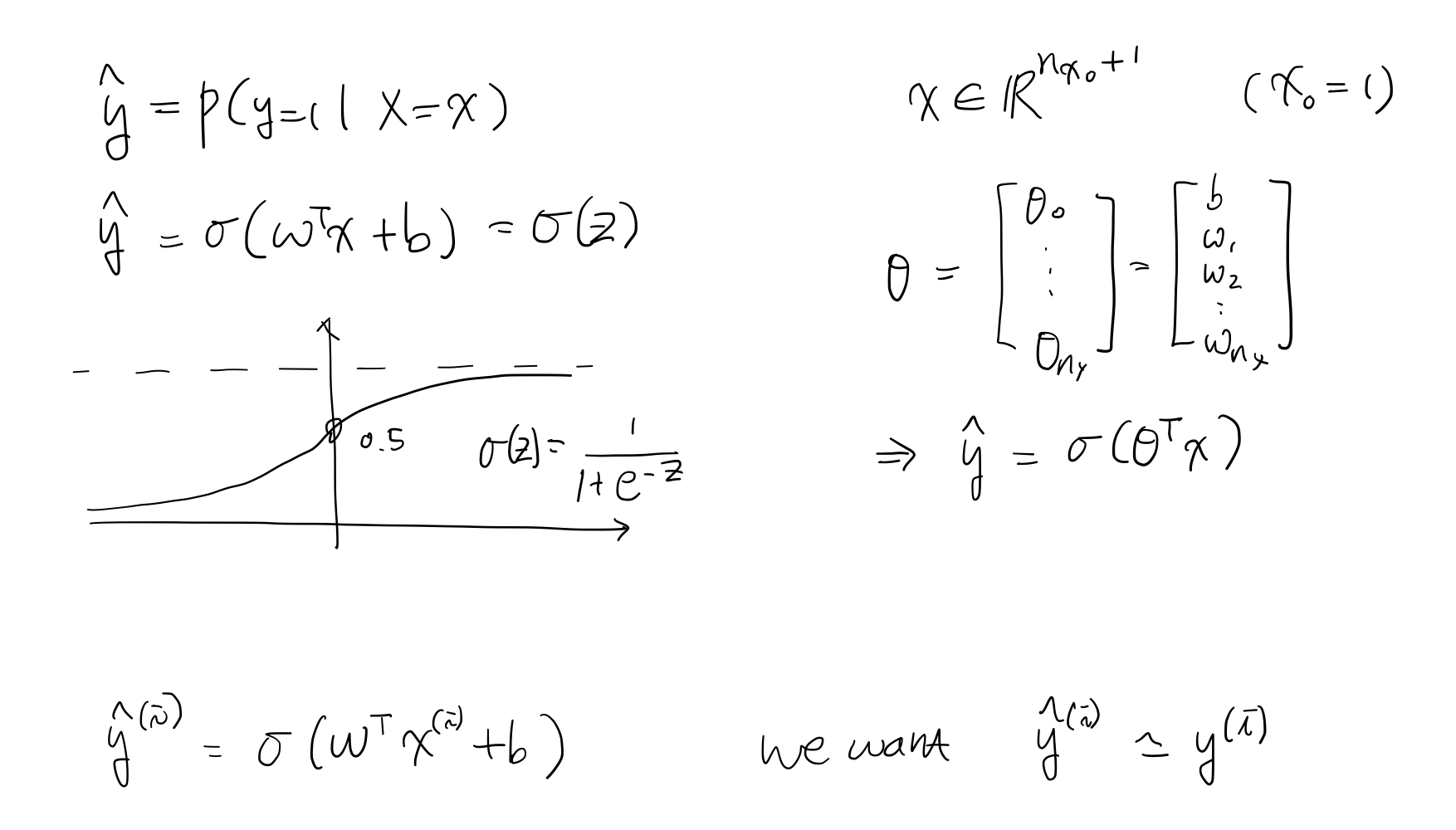
그려진 함수는 Sigmoid 함수라고 하는데, activation function이라고도 불린다.
저걸 쓰는 이유는
- 어떤 값을 넣던지, 0~1 사이의 값을 반환해 주기 때문이고
- 값이 클 수록 확률이 높게 나오는 단조증가 함수이기 때문이다.
우리가 학습시킬 parameter는 w, b 이고 나머지는 전부 주어지는 값들이다.
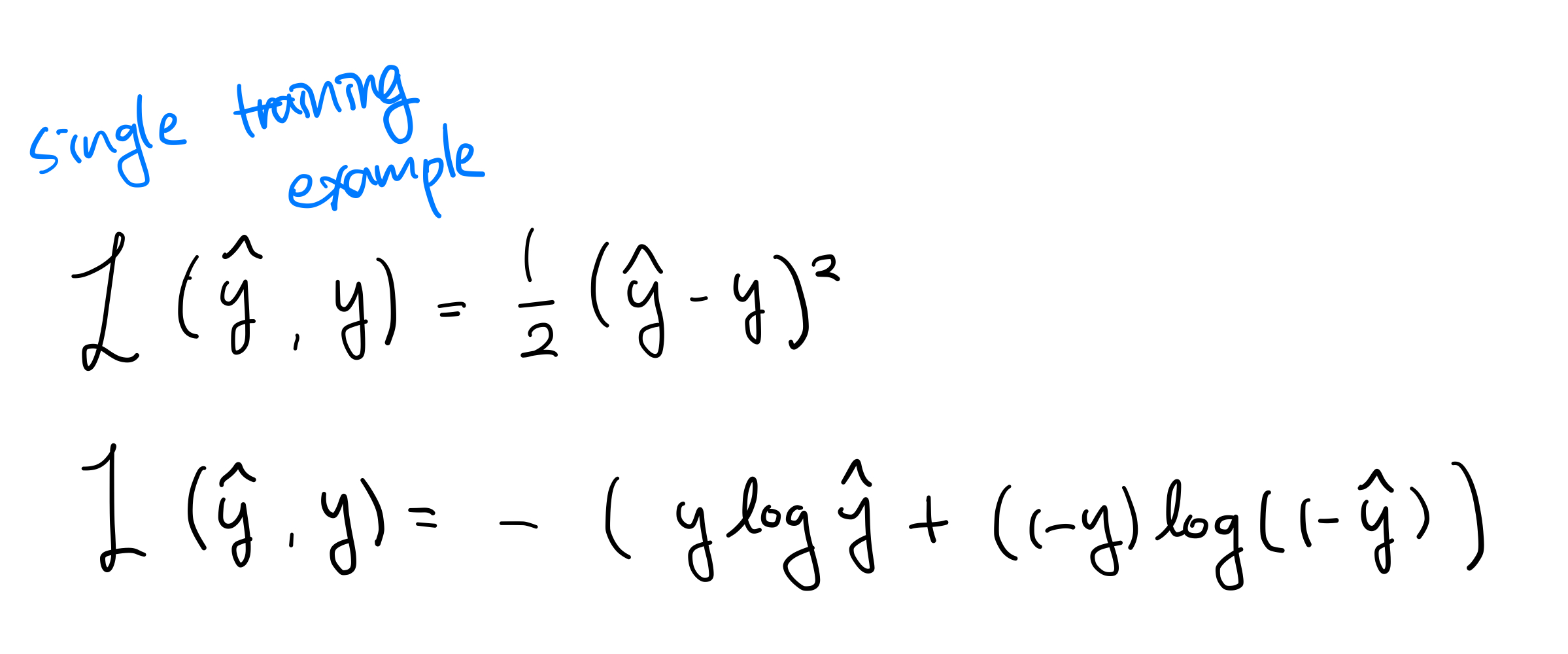
두가지 대표적인 Loss function을 나타내었다.
첫 번째는 MSE(Mean Square Error), 두 번째는 Cross-Entropy이다.
Loss라는 것은 말 그대로 예측값과 참 값 차이의 error를 의미한다. Cross-entropy가 훨씬 계산하기 편하고, 더 학습이 잘 된다.(거의 무조건이다)
이외에도 많은 Loss function들이 있다.
이들의 가장 큰 공통점은 Convex function(아래로 볼록 함수) 라는 것이다. 나중에 나오니 기억해 두자.
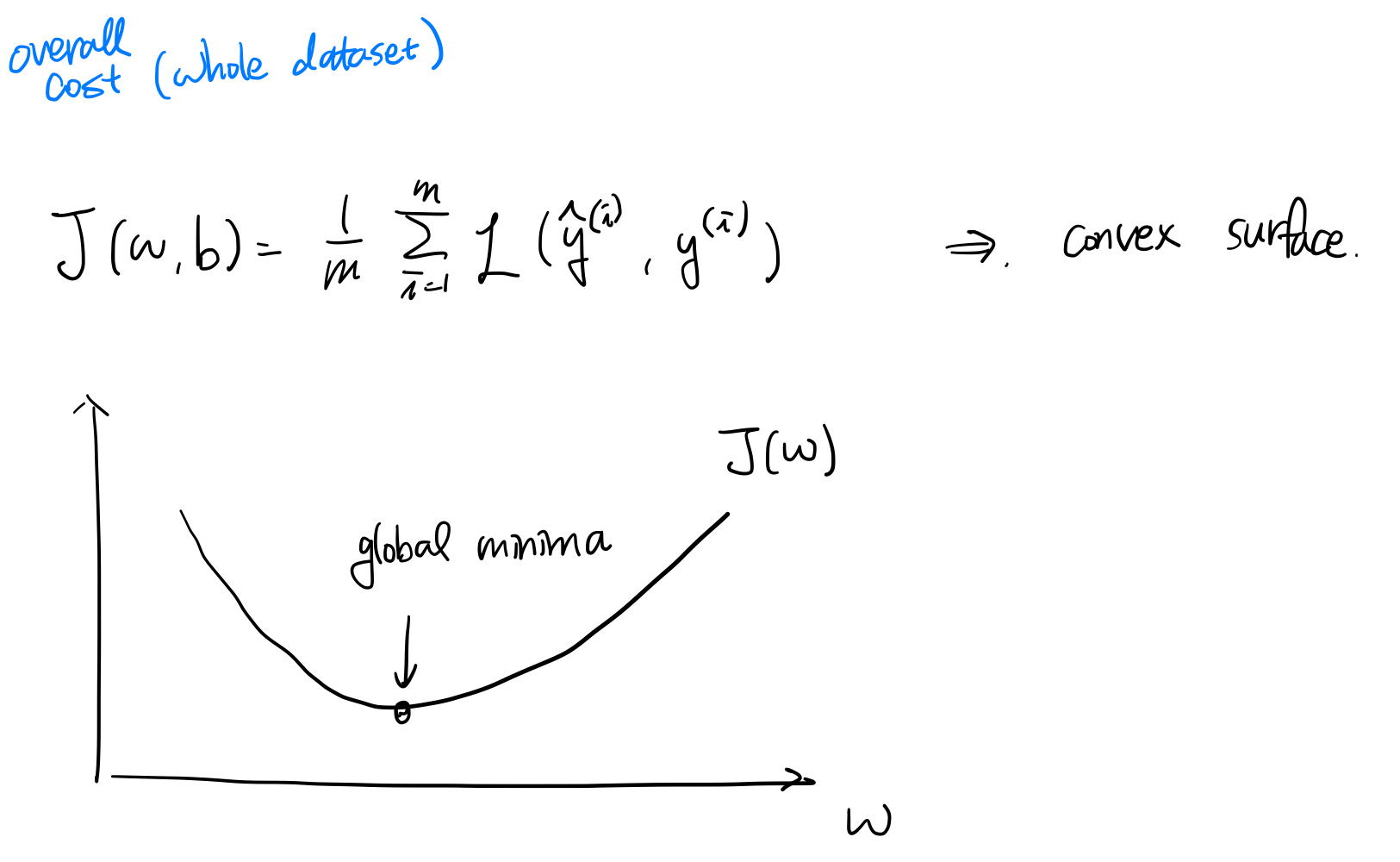
Cost function은 데이터 묶음에 대해서 Loss를 전부 더해 놓은 것이다. 뒤에 나올 vectorization과도 연결되는 내용이다.
딥러닝은 기본적으로 GPU 연산이 주를 이루기 때문에 데이터를 최대한 묶어 놓는 것이 중요하다.
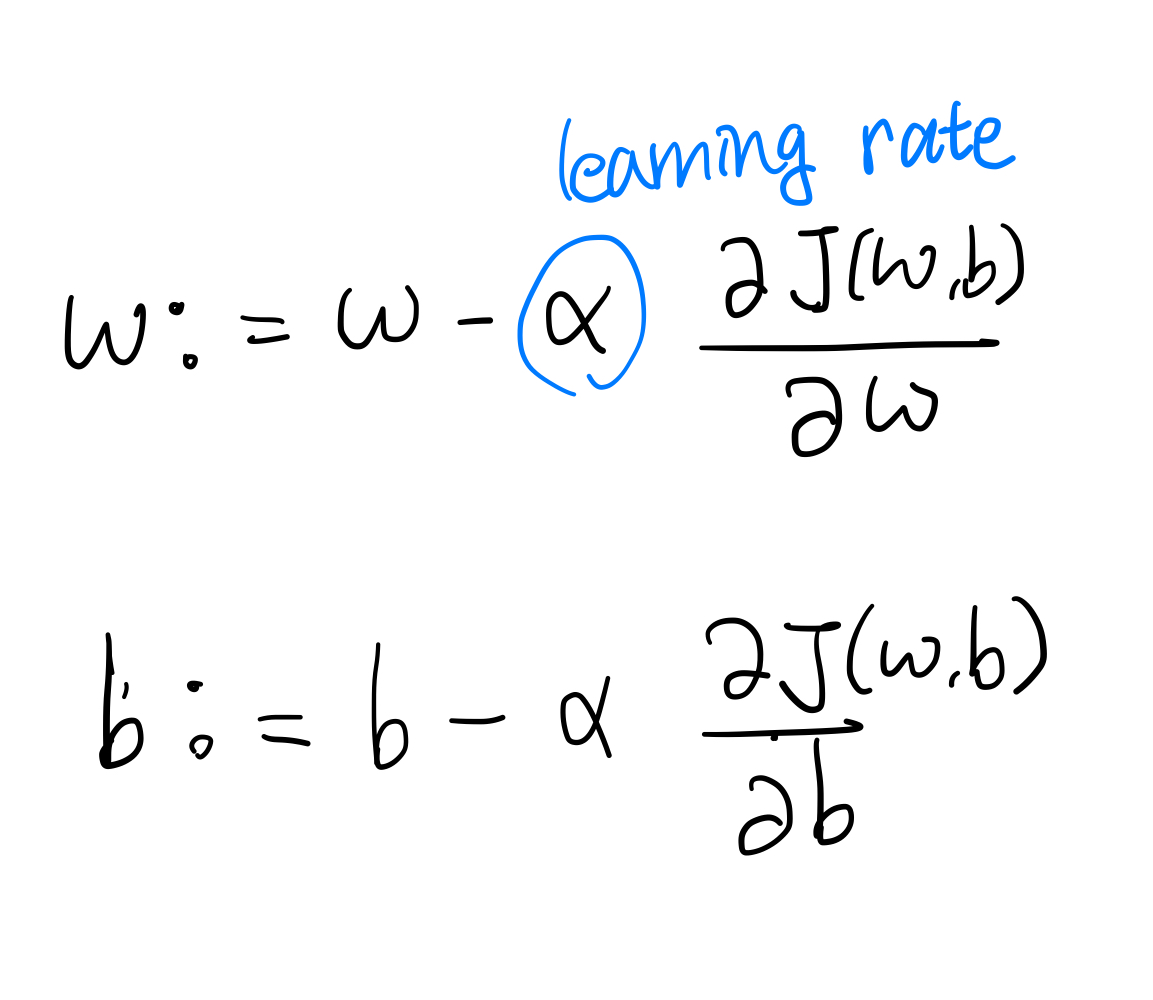
우리는 Cost function이 최소가 되도록 하는 parameter w,b를 찾고자 한다.
이 때 사용하는 방법이 Gradient Discent Method이다.
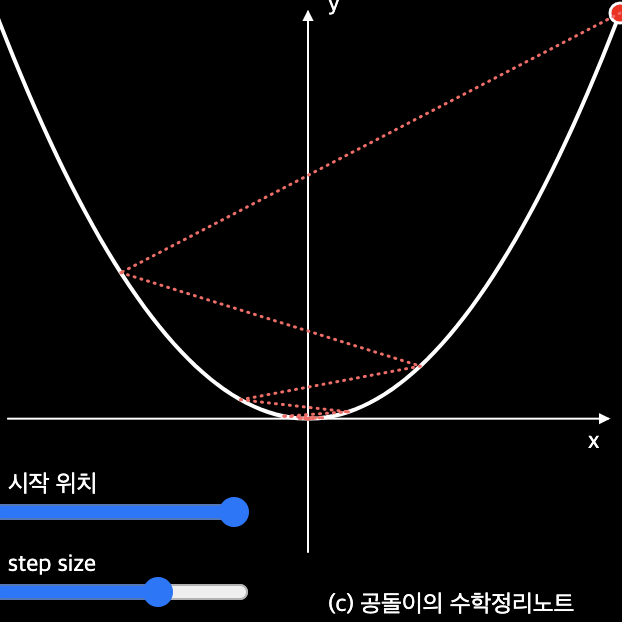
이 그림을 보면 좀 더 이해가 빨리 된다.
그냥 기울기의 반대 방향으로 계속 가다보면 최소점에 도달한다는 이야기이다.
Loss function은 기본적으로 convex 이므로 global optimum이든, local optimum이든 극소점에 도달하기는 한다.
현재는 더 다양한 방법들이 많지만 기본적으로는 대부분 GDM을 기반으로 한다.
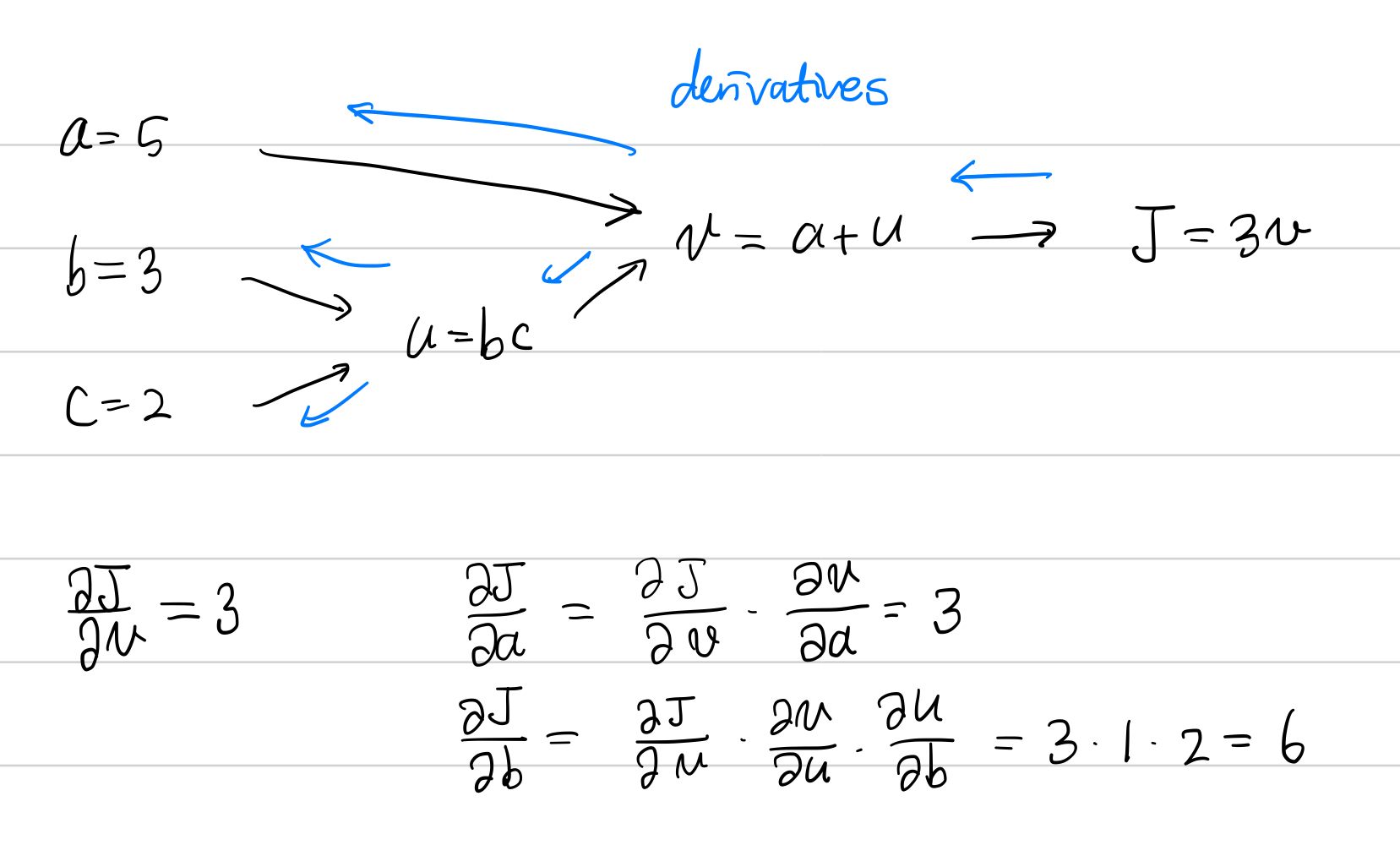
딥러닝에서 가장 중요한 것은 Gradient를 계산하는 것이다.
위와 같은 Graph 형태의 알고리즘은 딥러닝뿐만 아니라 회로, 선형대수, 확률 등에서 다양하게 사용된다.
이러한 Graph 형태의 computing 과정에서 gradient를 계산하는 방법들이고, 대부분 Chain rule을 통해 간단하게 구해진다.
pytorch나 tensorflow 등에서는 이러한 계산 과정을 알아서 다 해줘서 사실 몰라도 된다.

Logistic regression model 도 Graph 형태의 알고리즘이다. 사칙연산 대신 함수만 사용되었을 뿐.
Gradient를 계산하는 방법들이다. 직접 해보는 것을 추천한다!!!
그치만 마찬가지로 pytorch나 tensorflow 등에서는 이러한 계산 과정을 알아서 다 해줘서 사실 몰라도 된다.

위에서 계산한 derivatives를 python code로 나타낸 것이다.
간단하쥬?? 근데 m개의 데이터 묶음을 사용하기 때문에 Gradient를 합해서 한방에 흘려주는 방식이다.
GPU에서는 비효율적인 방법이므로, vectorization을 사용한다.

GPU 행렬 연산을 용이하게 만드는 것으로, 수학적으로 어려움은 없다.
GPU 특성상 for loop을 멀티쓰레드로 빠르게 계산 할 수 있기 때문에 vectorization은 필수다.
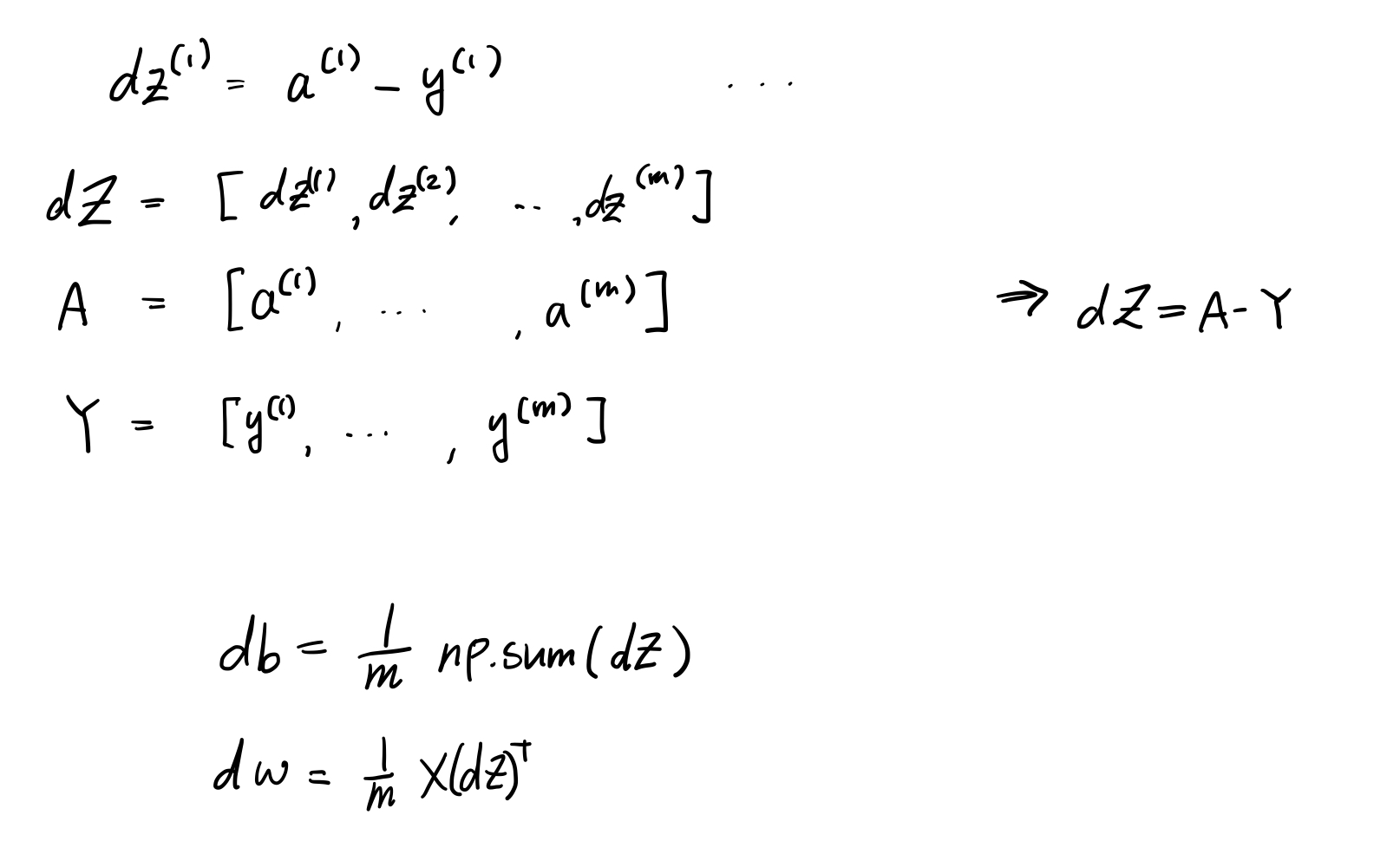
마찬가지로 그냥 묶어준 것이다.
행렬의 차원만 잘 맞춰주면 문제 없다.
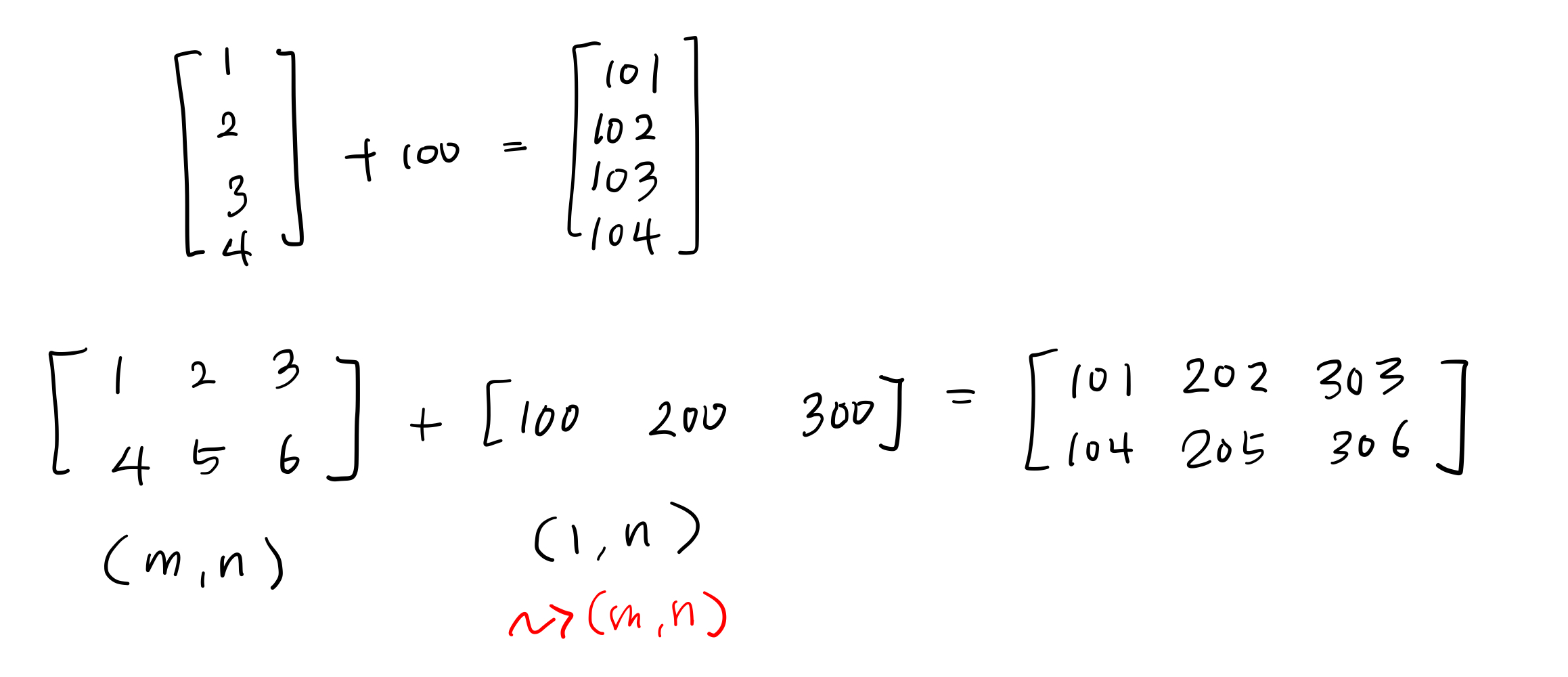
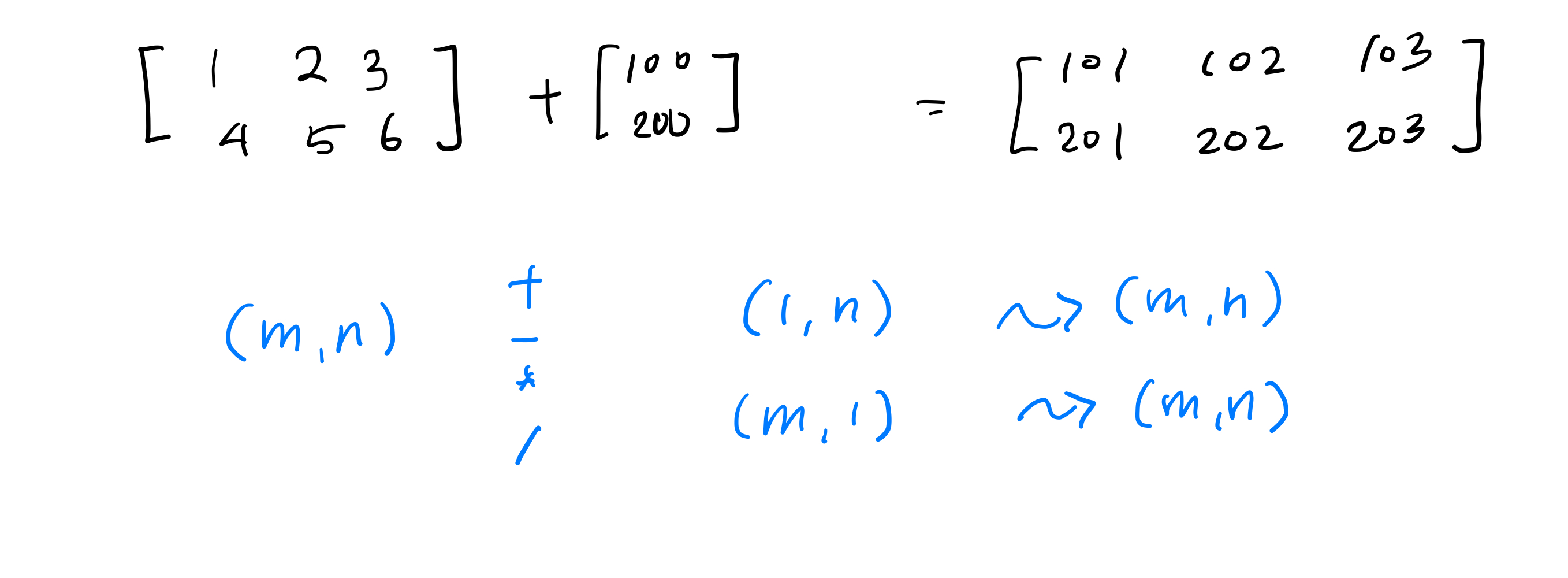
python에서 굉장히 중요한 기능 중 하나이다.
또한 굉장히 사람을 헷갈리게 만드는 기능이다.
numpy array에만 해당되는 것이니, 일반 리스트에도 적용된다고 생각하지 말자.
(m,n) 행렬과 연산을 시도하는 (m,1) 또는 (1,n) 행렬을 자동복사(Broadcast)하여 (m,n)으로 만들어준다.

이건 그냥 팁이다.
np.random.rand(5)는 개념적으로는 vector이다.
vector는 일반적으로는 column vector를 의미하는데, 1차원 vector를 정의했다가는 transpose도 안되고, 그냥 1차원 배열처럼 되어버린다.
꼭 딥러닝 구조에서 사용 되는 최대 차원으로 정의를 해주자!
(예를 들어 중간에 3차원 행렬이 사용된다면, 처음 input도 vector라 할지라도 (n,1,1)로 정의해야 한다.