{kind=link}
{kind=link}
{kind=link}
{kind=link}
Machine translation systems make many assumptions, missing a couple words that they could have translated - if only they were a little bit more lenient.
This is a soft dictionary lookup solution that can post-process machine translation output to translate some of the words that were not translated. This works by splitting OOVs (out-of-vocabulary words, unknown words) into multiple parts and then performing a fuzzy lookup in the dictionary for all these parts, yielding english compounds, scoring them according to some handcrafted features and outputing the best option, as shown in these pictures from explanatory slides:

Fun bonus: a glosser using this "guessing" architecture.
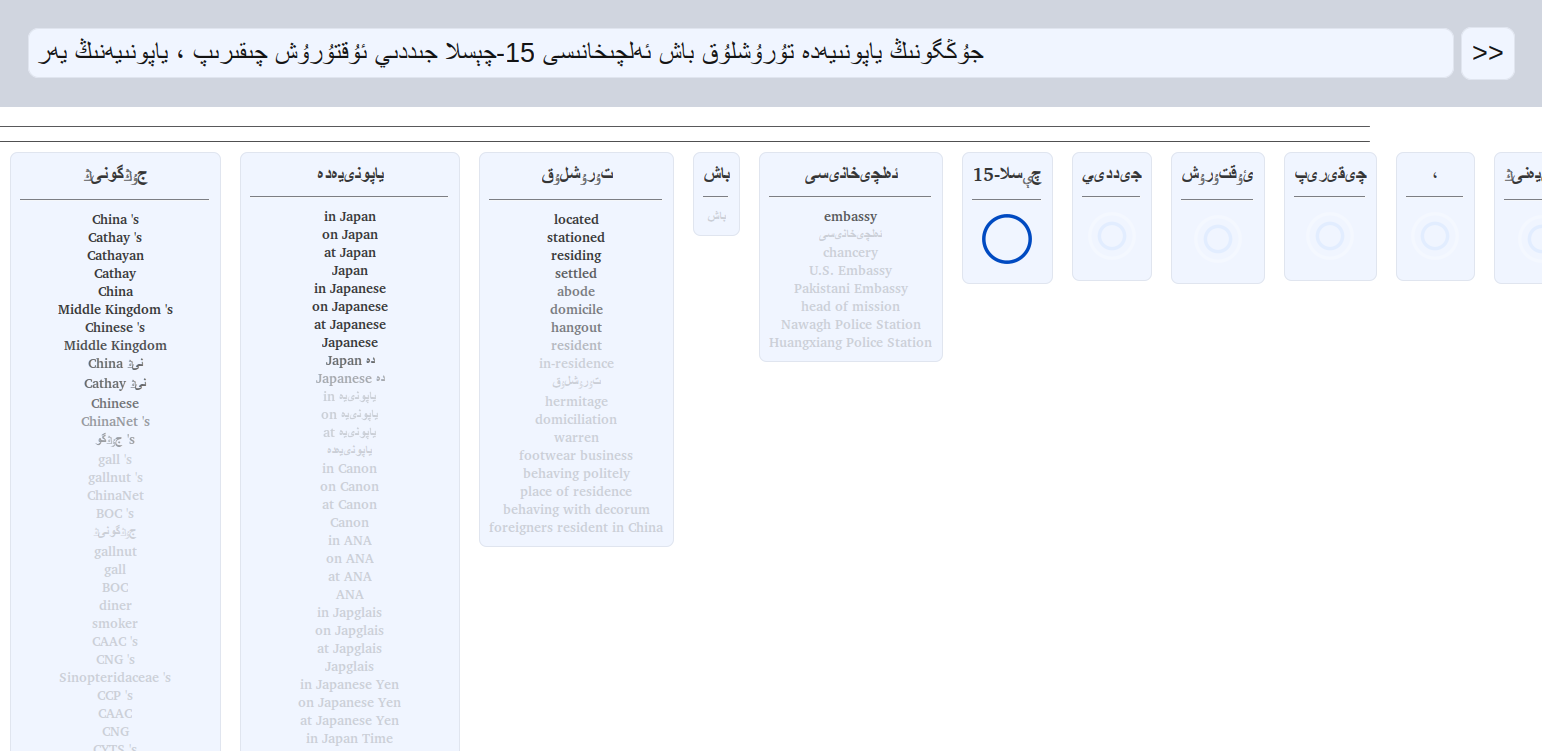
- Python 3, must be executable/in path as
python3 - morfessor 2.0, must be executable/in path as
morfessor - the AGILE tokenizer has to be cloned into
tools/agile_tokenizer
Your "static data" directory must contain the following files with these exact names (you can specify $LEX yourself):
| description | filename |
|---|---|
lexicon (3-col TSV: source [ignored] target) |
${LEX} |
| leidos-unigrams (i.e. output of `sort | uniq -c |
| Ulf's grammar (uig-specific, sorry) | grammar.uig-v04.txt |
| Ulf's pertainym list | english.pertainyms.txt |
| binary Morfessor model | binary-baseline-model |
| ELISA packages (used for ELISA package output) | package/elisa.*-eng.${set}.y?r?.*.xml.gz |
bleu.plfor BLEU calculation (will be safely skipped, if not on HPC)packagesbmt.sh(will be safely skipped, if not on HPC)CALL_{SYSTEM,SET,SETPART}are set to useqsub -q isiinrun.system.sh(replace by e.g.bashif not on HPC, seerun.singlefile.sh)
bash run.system.sh SBMTSYSTEMPATH SETS STATICDATAPATH LEXICONNAME REFERENCES, e.g.:
/home/nlg-05/sjm_445/pyguess/run.system.sh \
/home/nlg-02/pust/elisa-trial/isi-sbmt-v5-uzb \
"dev test syscomb domain domain2 eval" \
/home/nlg-05/sjm_445/uyghur/on_top_of/__staticdata \
guessing_input_lexicon.v14 \
/home/nlg-05/sjm_445/uyghur/elisa.il3.package.y1r2.v1
Run in the directory where you want to store all resulting data. The script will create a folder with the system name (isi-sbmt-v5-uzb in this case) and store all results (finished ELISA packages and guess-dictionaries for each set) in a outputdata subfolder.
The references directory is expected to hold all elisa-...set...xml.gz files from the package. If it does not yet contain the xtracted versions of all files, these will be created, so make sure you're allowed to write there!
bash run.singlefile.sh INFILE STATICDATAPATH LEXICONNAME REFERENCES, e.g.:
/home/nlg-05/sjm_445/pyguess/run.system.sh \
some.oovs.txt \
/home/nlg-05/sjm_445/uyghur/on_top_of/__staticdata \
guessing_input_lexicon.v14
/home/nlg-05/sjm_445/uyghur/elisa.il3.package.y1r2.v1
Run anywhere. Will create $INFILE.guessed.1best.hyp and $INFILE.guessed.nbest.json (in the same folder as $INFILE).
Behind the scenes the script will make a "set" out of the file, create a folder in the $TMPDIR match the whole set and then continue guessing the set just like run.system.sh, so if you have expensive matching to do, consider wrapping the call in a qsub-script yourself.
run.{singlefile,system}.sh source run.functions.sh. This is where preprocessing, matching, guessing and postprocessing calls are defined. The python programs are controlled using a JSON config file pyguess.config. This file is generated by all the shell scripts on each invocation using the given parameters.
For each set individually:
tools/extract_tokens.pyextracts an OOV list from the SBMT output (obtained by runningnbest2jsoninrun.system.sh).- All pipes (
|) in that list are replaced with slashes to avoid clashes with morfessor-flatcat... which is not yet included, but better be prepared. - Morfessor segments that input.
guess_phrases.pygenerates a bunch of phrase parts.
For all these phraseparts together:
- Pipe all phraseparts (types) into
guess_matching.py, this generates one bigallmatchesdictionary
For each set individually:
thirdeye.pycalculates 1best and nbest translations for the OOV list using the (now shared)allmatchesdictionary
For each set individually:
tools/rejoin_oovs.pyre-inserts the 1best translations of the OOVs into the SBMT output- This file is detokenized, BLEU scores are calculated and it is packaged into a nice ELISA package.
- Many things are probably super inefficient.
- My parallelism (create lots of scripts and jobs) works, but...
- Storing all matches in one big
allmatchesfile per system is a giant race condition disaster waiting to happen. Therun.singlefile.shscript circumvents that problem by not sharing anything and doing all calculations in a temporary directory.