- Author : Shehani Wetthasinghe
- Last modified: 01/04/2023
 Source : https://www.kaggle.com/datasets/fedesoriano/stroke-prediction-dataset
Source : https://www.kaggle.com/datasets/fedesoriano/stroke-prediction-dataset
To predict the chance of having a stroke based on common risk factors using machine learning techniques.
According to CDC;
“A stroke, sometimes called a brain attack, occurs when something blocks blood supply to part of the brain or when a blood vessel in the brain bursts. In either case, parts of the brain become damaged or die. A stroke can cause lasting brain damage, long-term disability, or even death.”
| Feature | Description |
|---|---|
| Gender | Male / Female / Other |
| Age | Age of the patient in years |
| Hypertension | Yes(1) / No(0) |
| Heart Disease | Yes(1) / No(0) |
| Ever Married | Yes / No |
| Work Type | Children / Never worked / Government job / Private job / Self employed |
| Residence Type | Rural / Urban |
| Average Glucose Level | Average Glucose Level in Blood (mg/dL) |
| BMI | Body Mass Index (kgm -2 ) |
| Smoking Status | TFormerly smoked/Never smoked/Smokes |
| Stroke (Target) | Yes(1) / No(0) |
In the original dataset;
- contains 5110 rows and 11 columns
- 11 columns = 10 input features + 1 target variable
- From the total number of patients;
- ~95% detected as negative for brain stroke (normal)
- ~5% detected as positive for brain stroke (stroke)
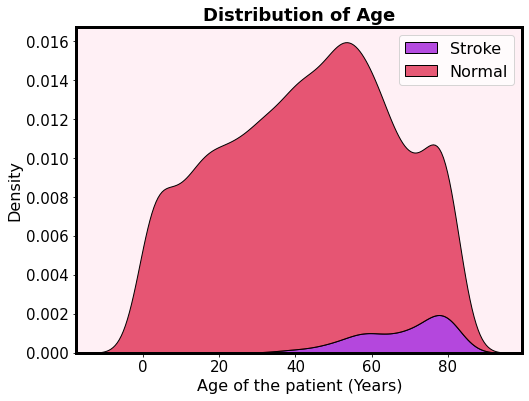
- Patients who got positive for brain stroke is approximately above 30 years old
- The risk of having a stroke is increasing with age
According to the CDC, patients can be categorized as;
- BMI is less than 18.5: Underweight range
- BMI is 18.5 to 24.9: Healthy Weight range
- BMI is 25.0 to 29.9: Overweight range
- BMI is 30.0 or higher: Obese range

- There is a risk of having a stroke if the BMI beyond the overweight range
- But there is also a chance of having a stroke even your BMI falls in healthy weight range
According to CDC the average glucose in blood can be catergorized into;
- Diabetes: above 126 mg/dL
- Prediabetes: 100 – 125 mg/dL
- Normal: Below 99 mg/dL
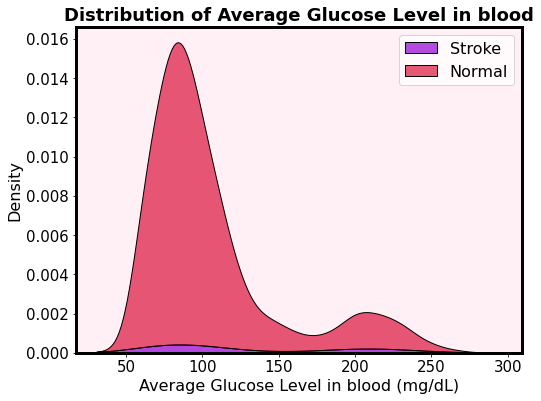
According the above plot, the risk of having a stroke is not much dependent on the average glucose level in blood
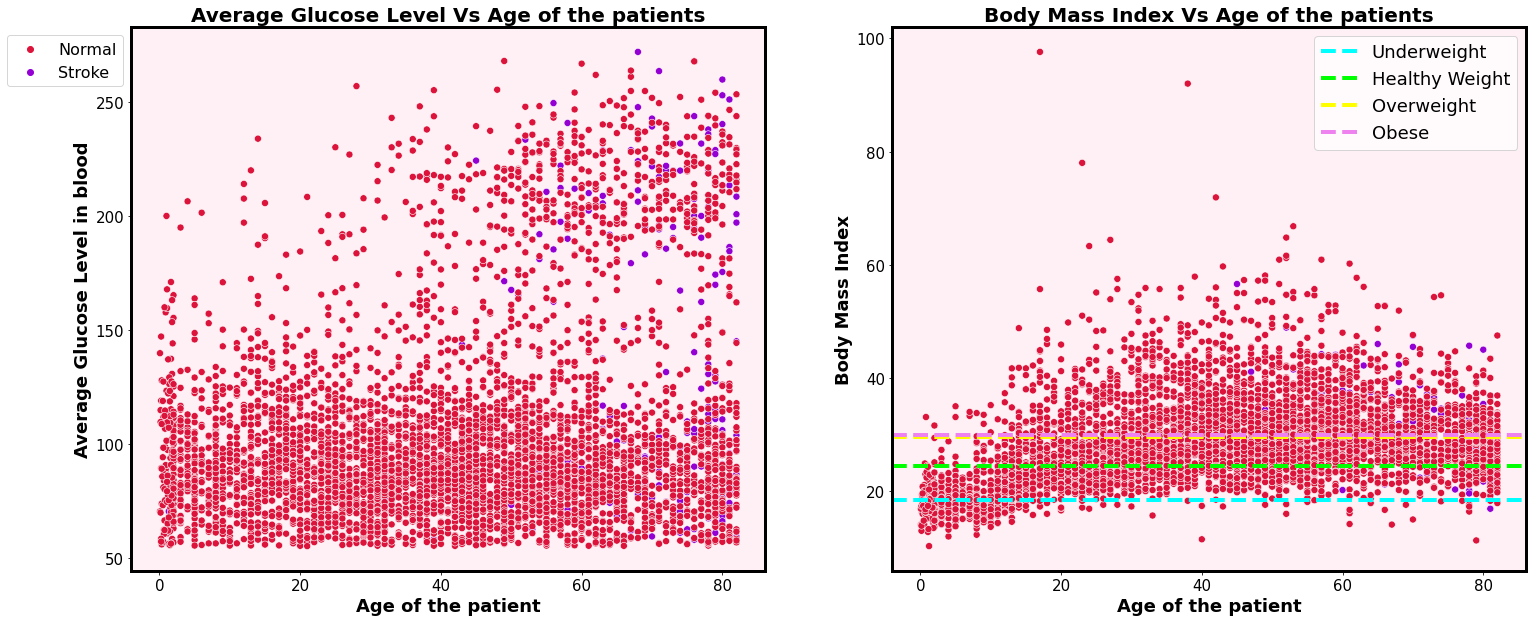
- There is a high risk on the people above ~45 years who suffering from diabetes to have a brain stroke
- There is a higher risk on the people above ~45 years who suffering from overweight to have a brain stroke
Here, I used classification ML models such as;
- Logistic Regression
- K-Nearest Neighbor
- Random Forest
- XG Boost
- Reduce the number of features using PCA
- Synthetically generated new data to balance the dataset using SMOTE
- Optimize the default parameters of the models
NOTE: In this problem, the number of false negatives required to minimize to reduce the risk on the patient. Therefore, the recall score is the most important metric.
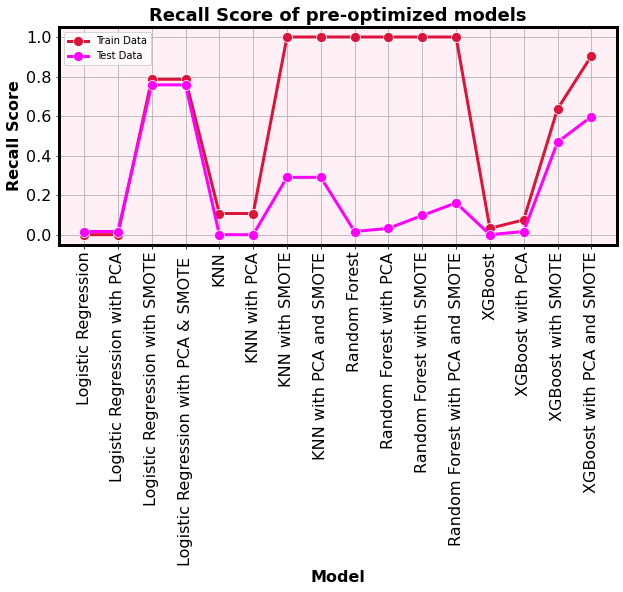
- For all tested models, the best recall score obtained when they are incorporated with both PCA and SMOTE.
- Therefore, I optimized the paramaters of those models to enhance the performence further.
| Model | Precision_train | Recall_train | F1 Score_train | Accuracy_train | ROC AUC Score_train | Precision_test | Recall_test | F1 Score_test | Accuracy_test | ROC AUC Score_test |
|---|---|---|---|---|---|---|---|---|---|---|
| Logistic Regression | 0.139 | 0.786 | 0.236 | 0.751 | 0.846 | 0.128 | 0.758 | 0.22 | 0.739 | 0.84 |
| Optimized Logistic Regression | 0.138 | 0.797 | 0.236 | 0.748 | 0.846 | 0.131 | 0.806 | 0.225 | 0.73 | 0.841 |
| KNN | 0.3 | 1.0 | 0.462 | 0.886 | 0.997 | 0.076 | 0.29 | 0.12 | 0.793 | 0.635 |
| Optimized KNN | 0.336 | 1.0 | 0.503 | 0.903 | 0.997 | 0.075 | 0.242 | 0.115 | 0.818 | 0.614 |
| Random Forest | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.089 | 0.161 | 0.115 | 0.879 | 0.749 |
| Optimized Random Forest | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.074 | 0.081 | 0.077 | 0.906 | 0.755 |
| XGBoost | 0.209 | 0.904 | 0.339 | 0.828 | 0.94 | 0.128 | 0.597 | 0.211 | 0.783 | 0.779 |
| Optimized XGBoost | 0.22 | 0.882 | 0.353 | 0.842 | 0.932 | 0.135 | 0.613 | 0.222 | 0.791 | 0.788 |
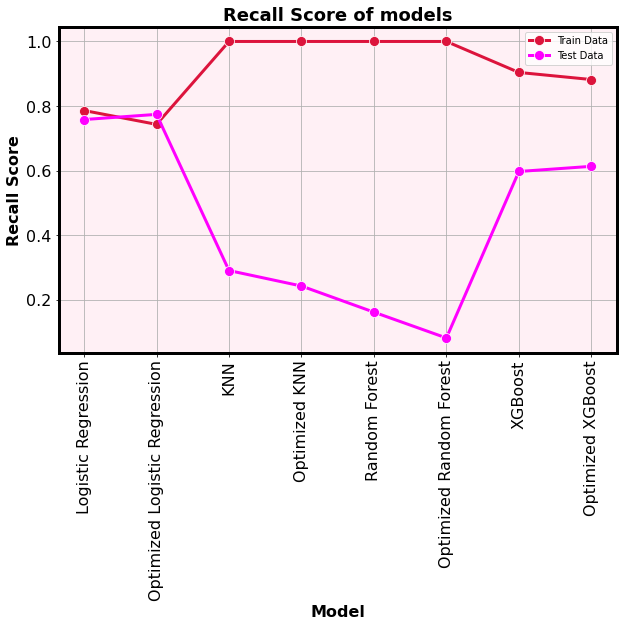
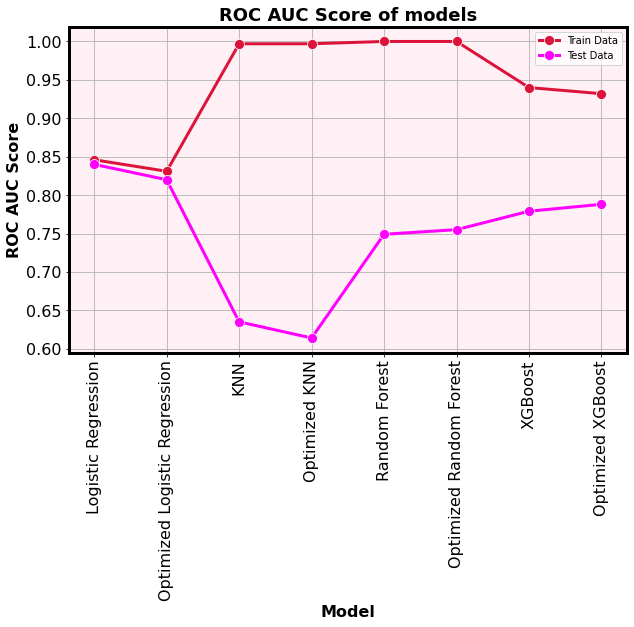
- Out of the 4 models, the optimized logistic regression model can be selected as best model according to the recall score and ROC score.
- Especially in this project, we are trying to maximize recall score to minimize the risk on patietns.
- The logistic regression models are the ones identified as the minimal overfitting models because their training scores are approximately similar with testing scores.
- The optimized logitic regression model not only gained the highest testing recall score, it also performed very well on testing data over training data according to the recall score.
- Therefore, optimized logistic regression model is the best model to predict the risk of stoke of patients.
- As per the findings of this project, the optimized Logistic Regression Model can be used as an early detection of brain stroke and direct to the treatments
- This model is developed to minimize the inaccurate predictions which may increase the severeness of the brain strokes
- The risk of have a brain stroke is increasing with age, BMI and average glucose level in blood
- Therefore, it is recommended to keep track on your glucose level in blood and BMI when you are getting older.