CUDA-accelerated C++ implementations of robotics algorithms, based on PythonRobotics and CppRobotics.
Each algorithm leverages GPU parallelism for significant speedup over CPU-only implementations.
GPU enables orders-of-magnitude more particles/samples, resulting in visually better results. All comparisons below use the same algorithm on CPU and GPU — the only difference is sample/particle count enabled by GPU parallelism:
| Particle Filter: CPU 100 vs CUDA 10,000 particles | Expansion Reset MCL: 10,000 particles, kidnap recovery (Standard MCL fails, Expansion Reset recovers) |
 |
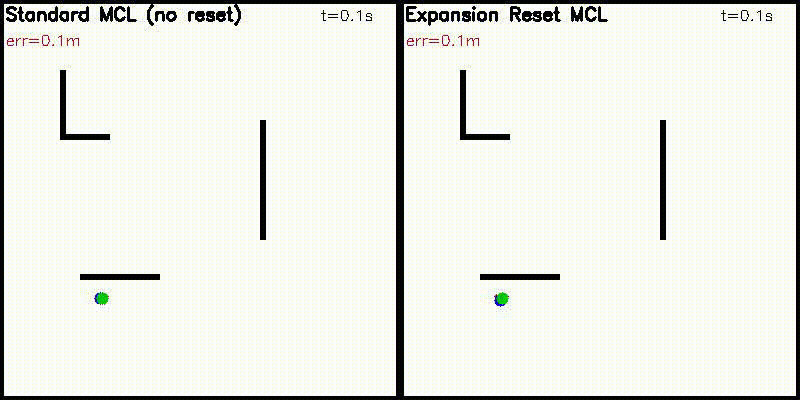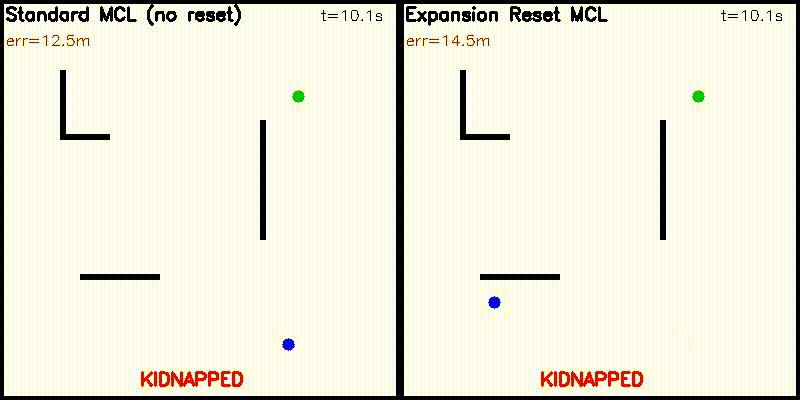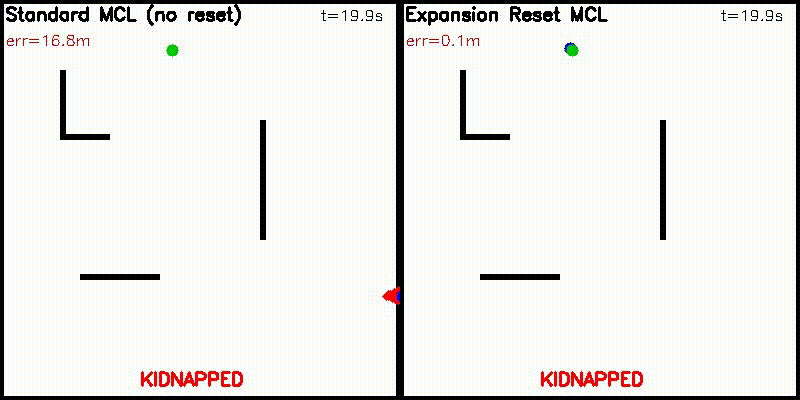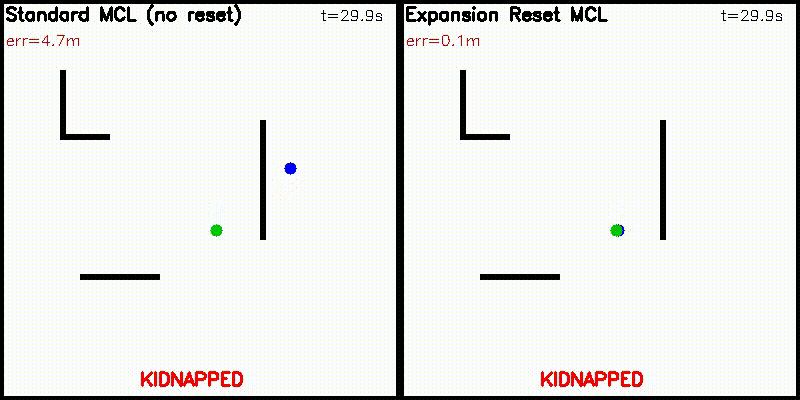 |
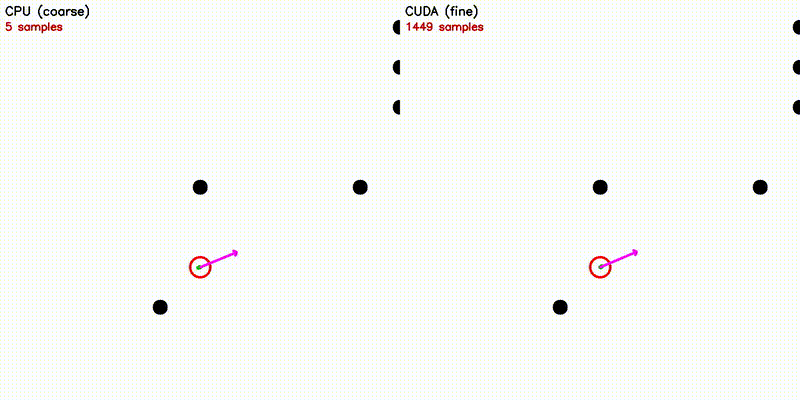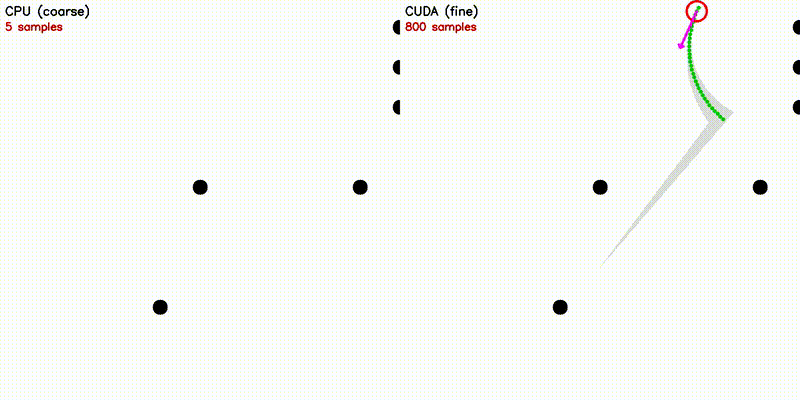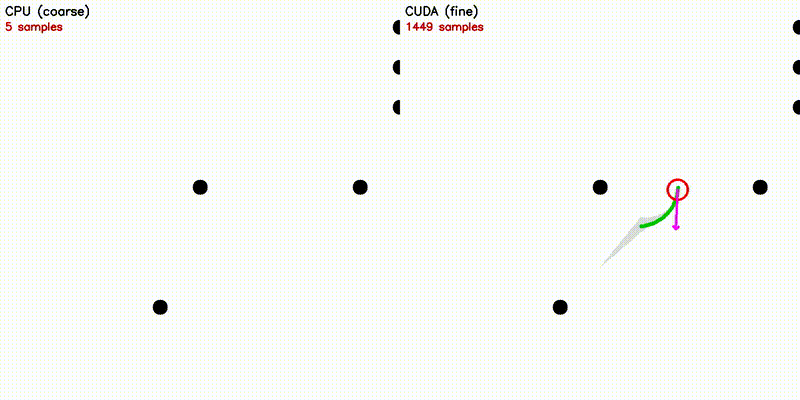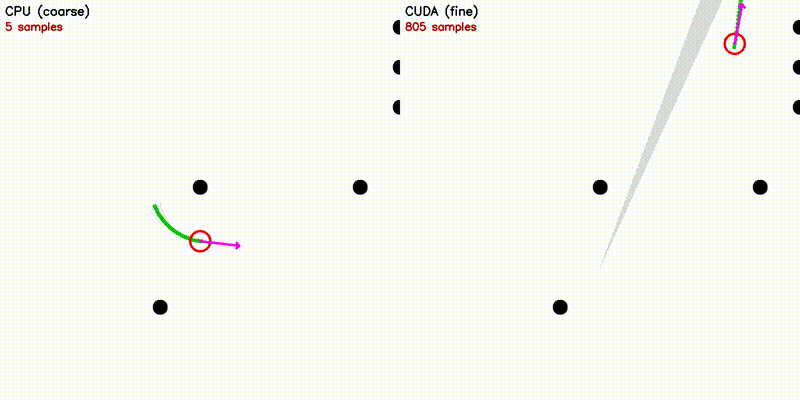
| Multi-Robot: CPU 5 vs CUDA 500 robots | DWA: CPU 50 vs CUDA 50,000 samples |
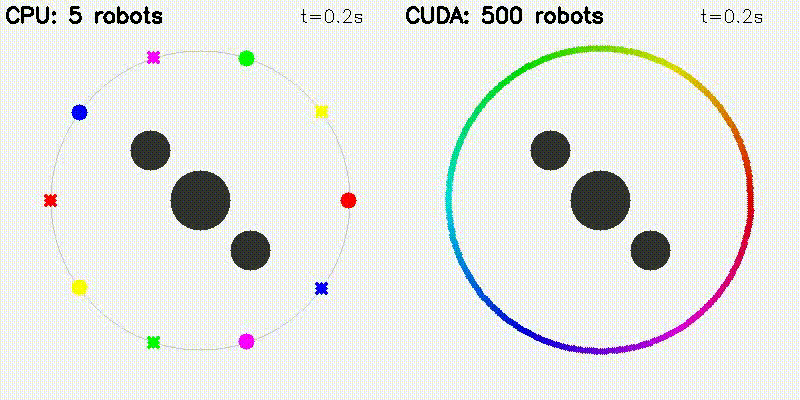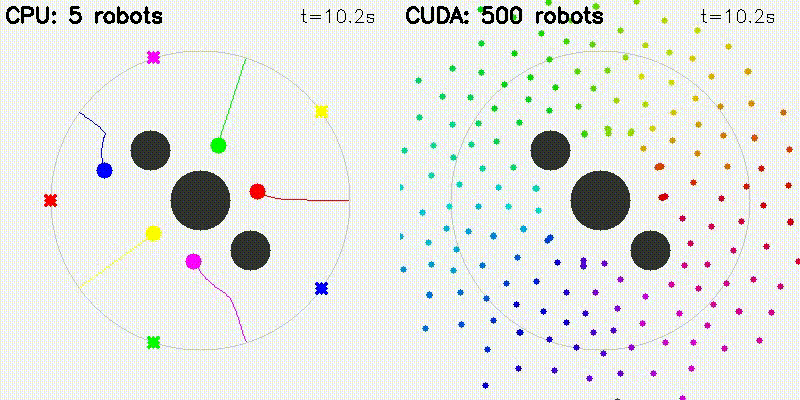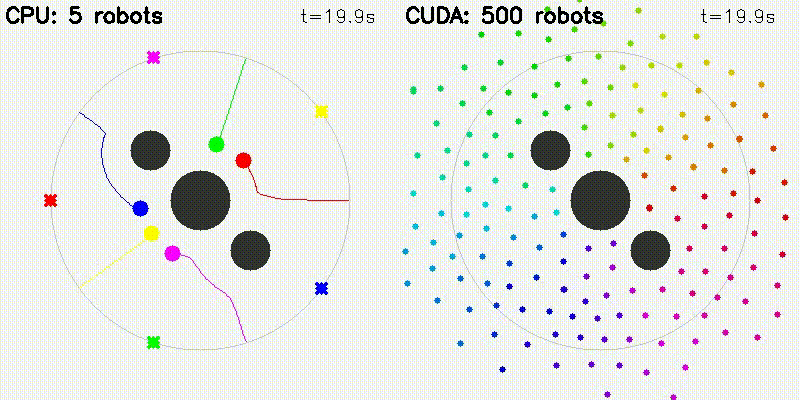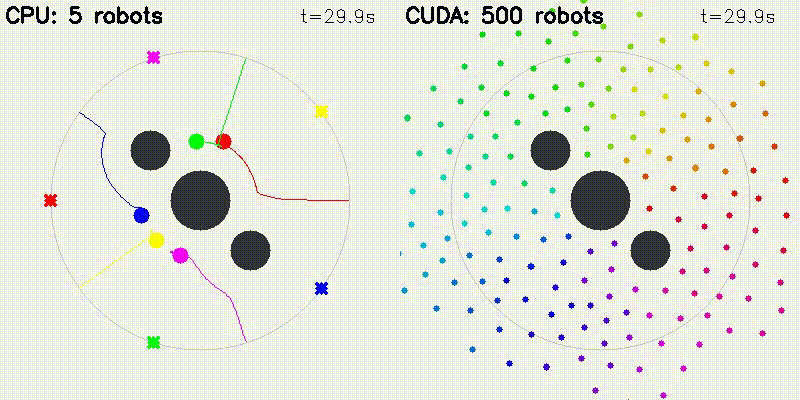 |
 |
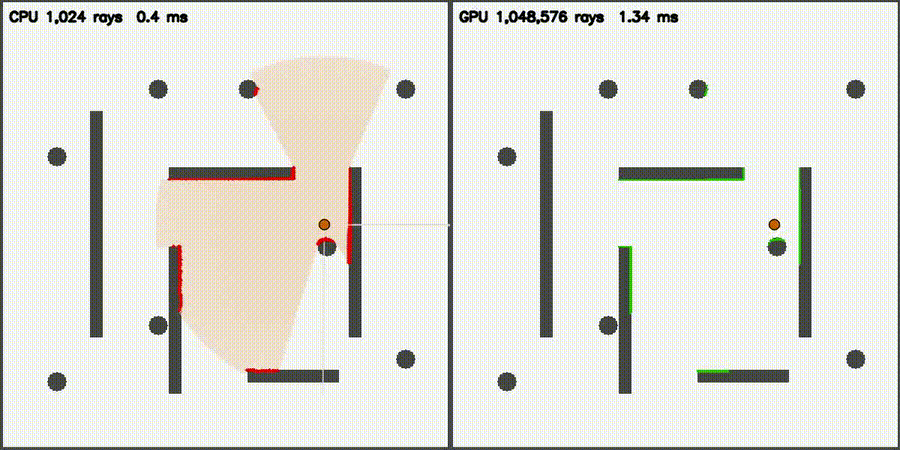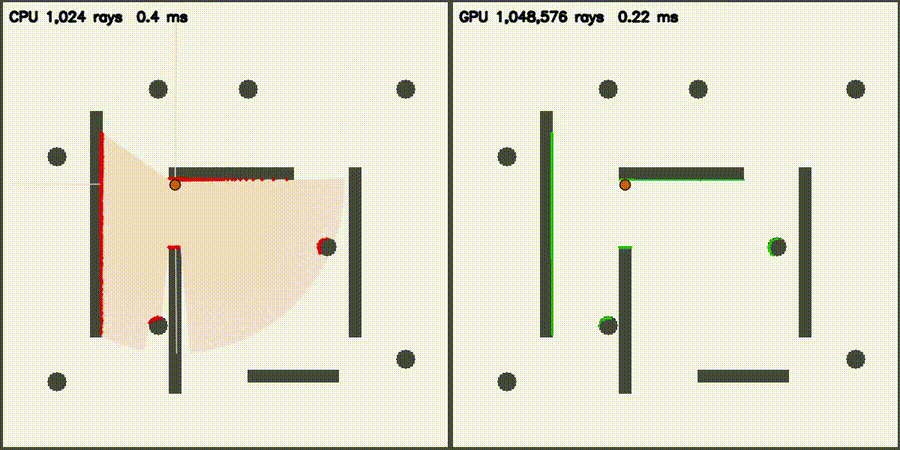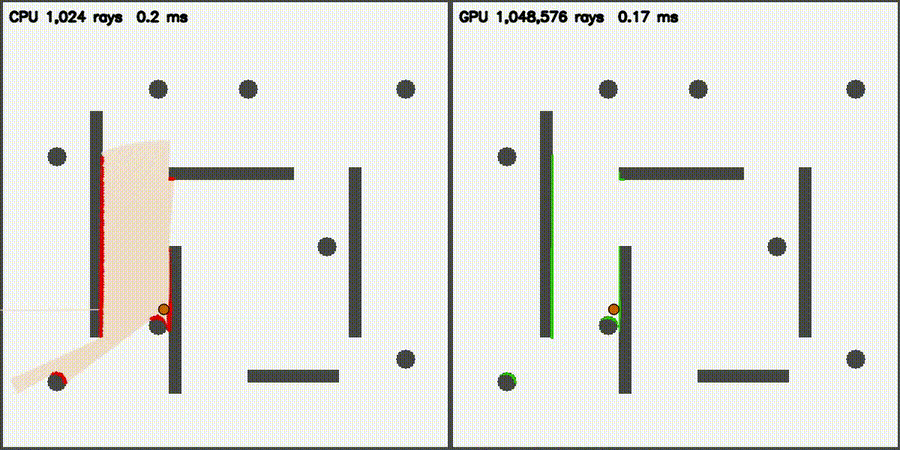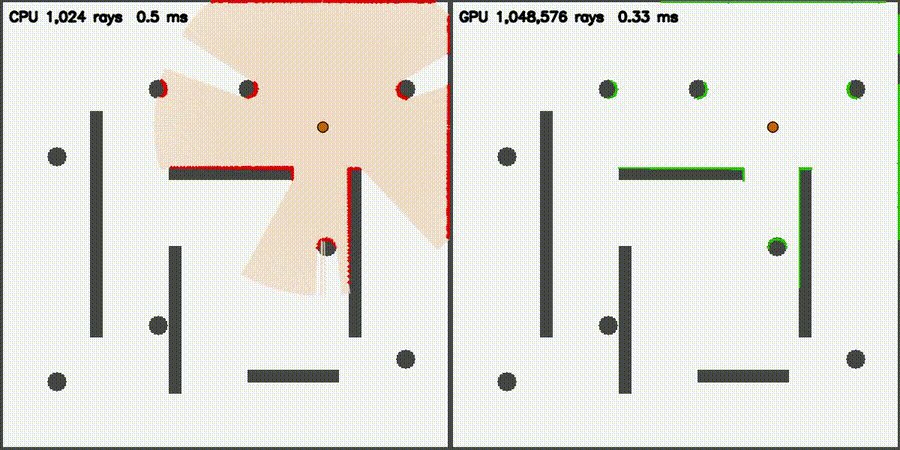
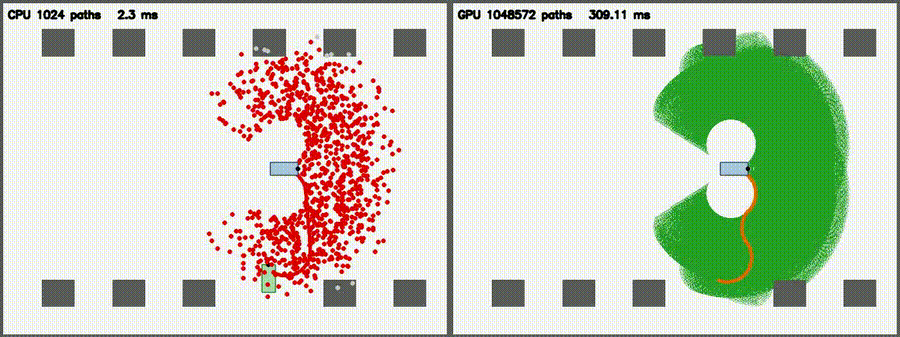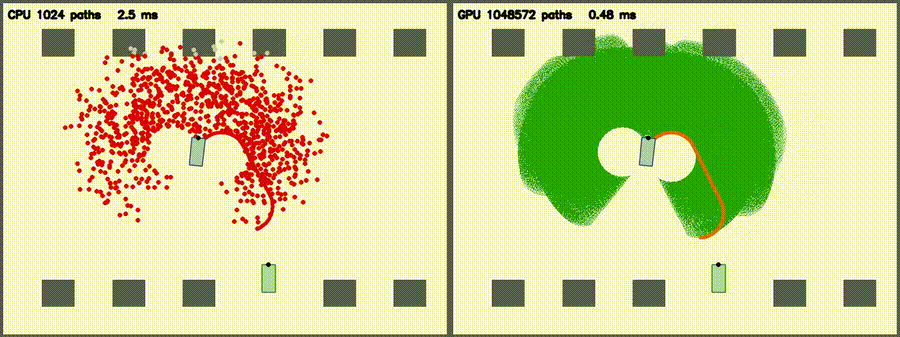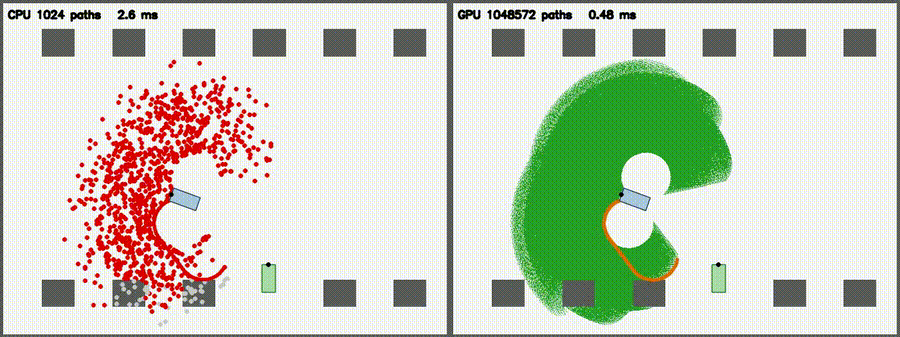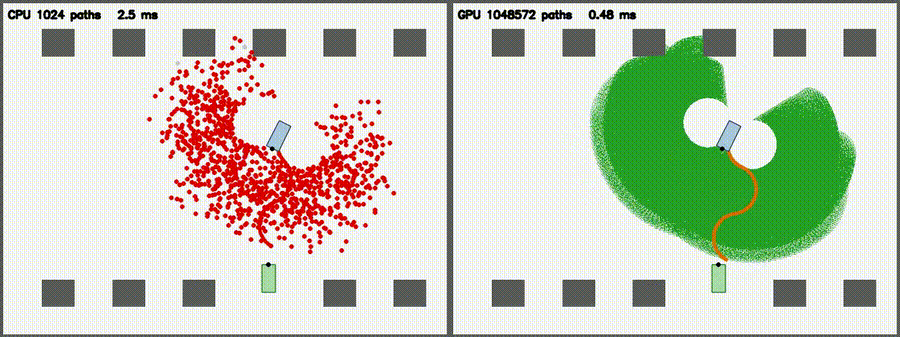
| Lidar Simulator: CPU 1,024 vs CUDA 1,048,576 rays / scan | Reeds-Shepp Fan: CPU 1,024 vs CUDA 1,048,572 candidate paths |
 |
 |
All CPU vs CUDA speed comparisons + algorithm-axis demos (click to expand)
| 500 Robots Collision Avoidance | Particle Filter |
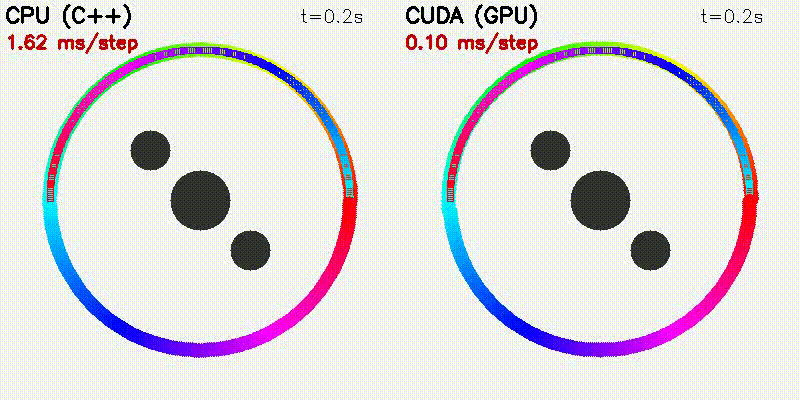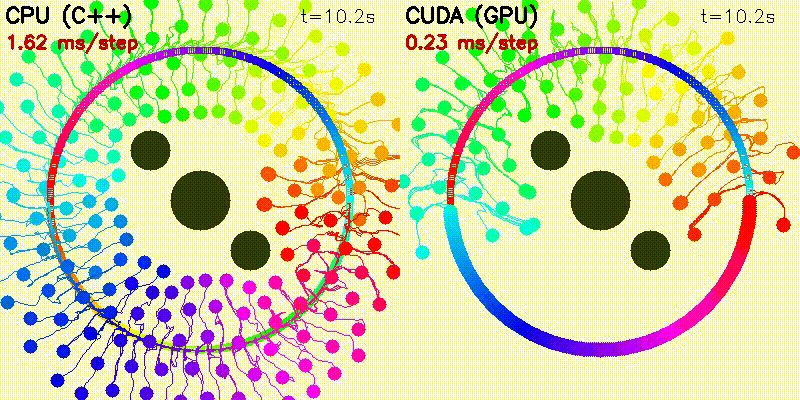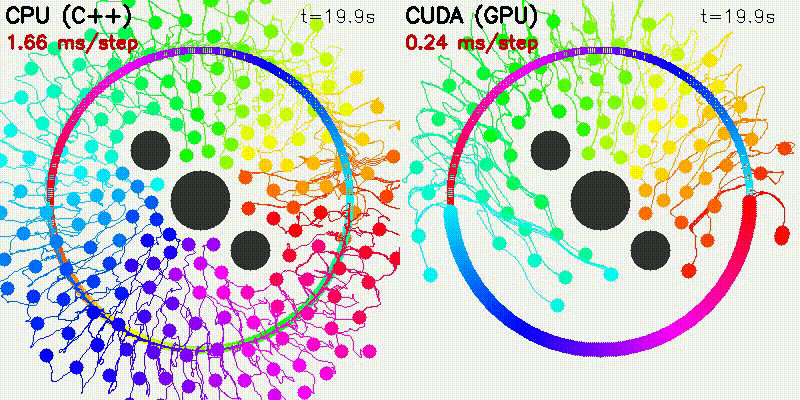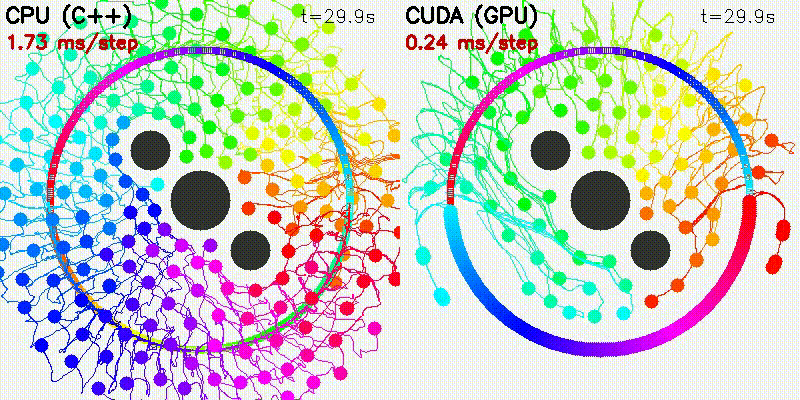 |
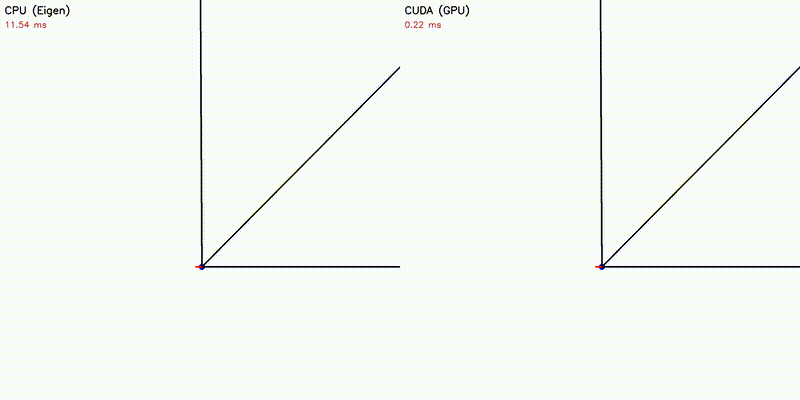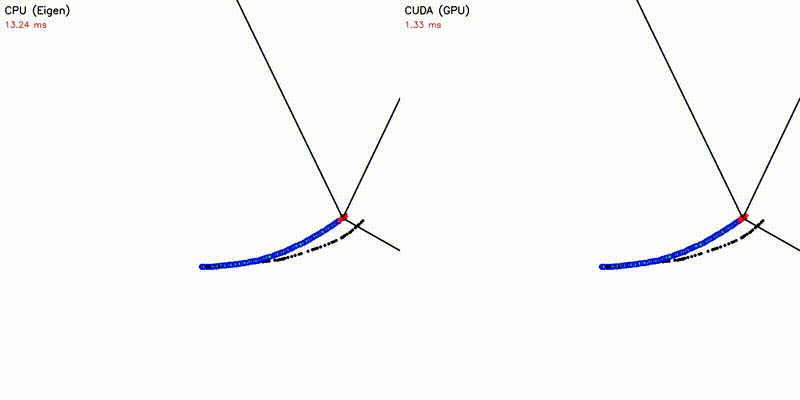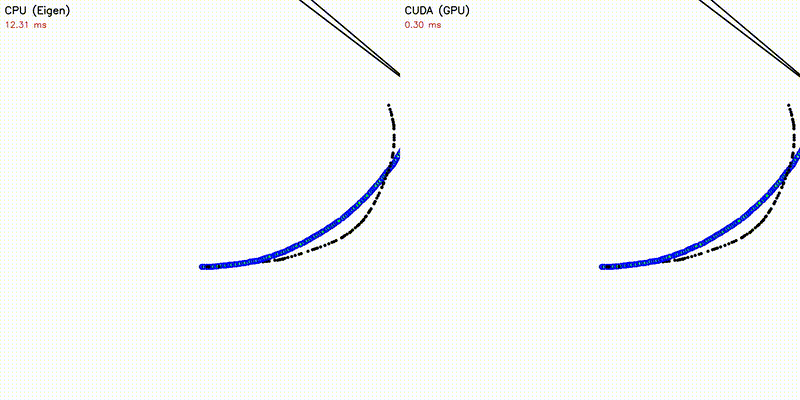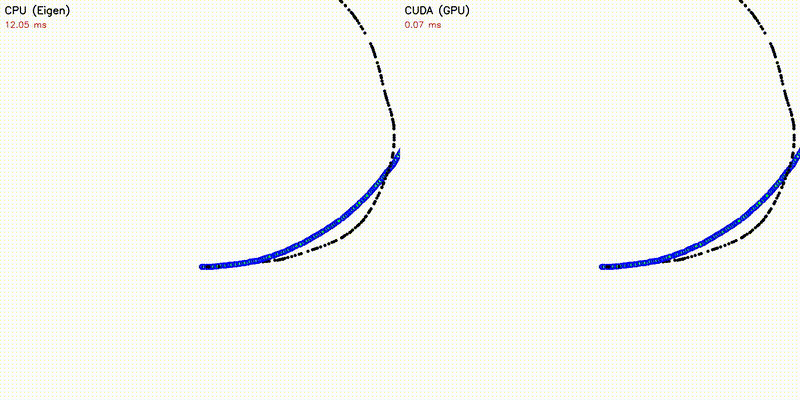 |
| Dynamic Window Approach | Frenet Optimal Trajectory |
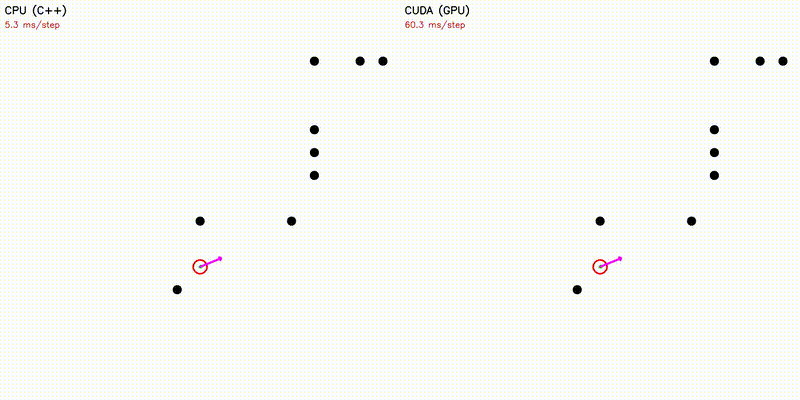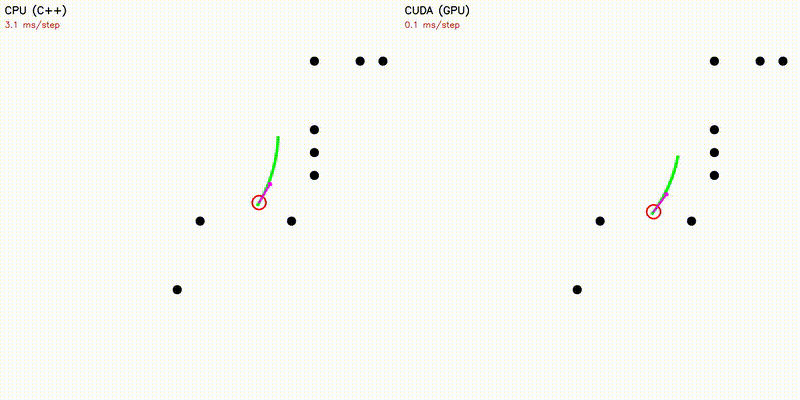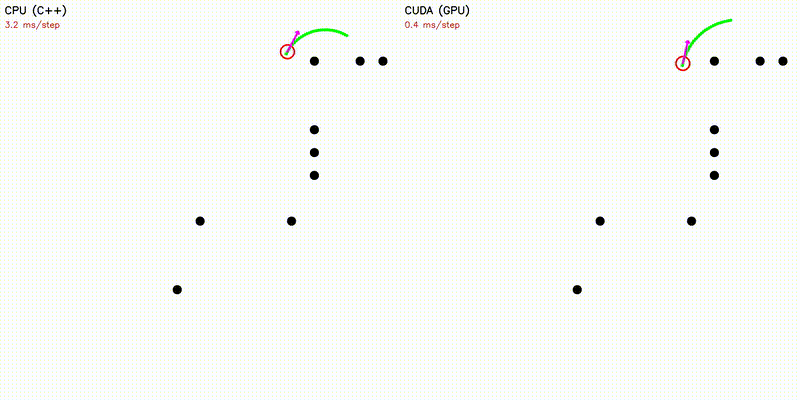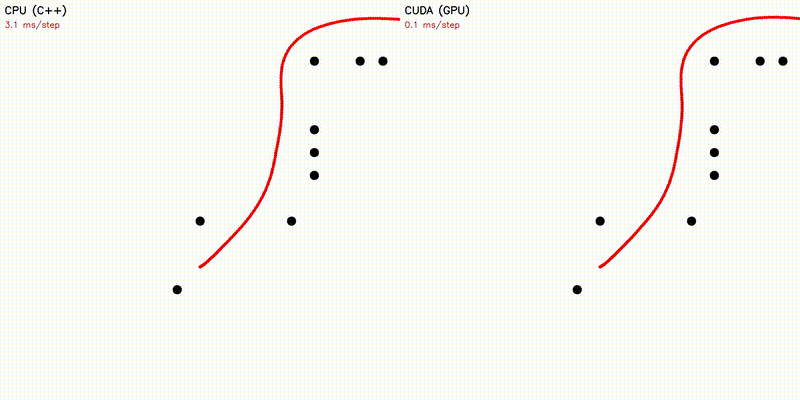 |
 |
| RRT | RRT* |
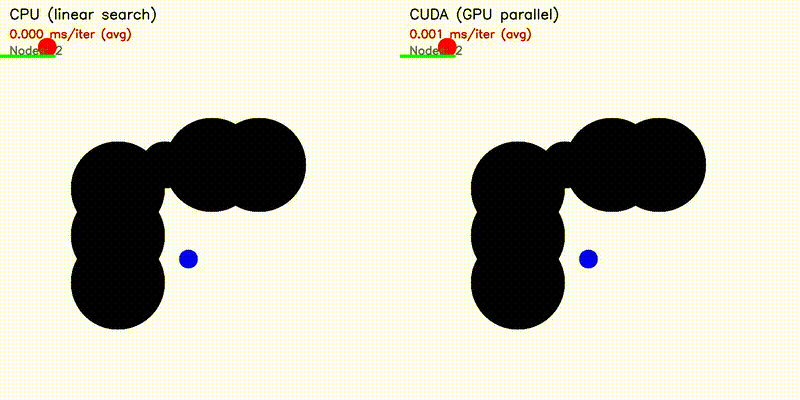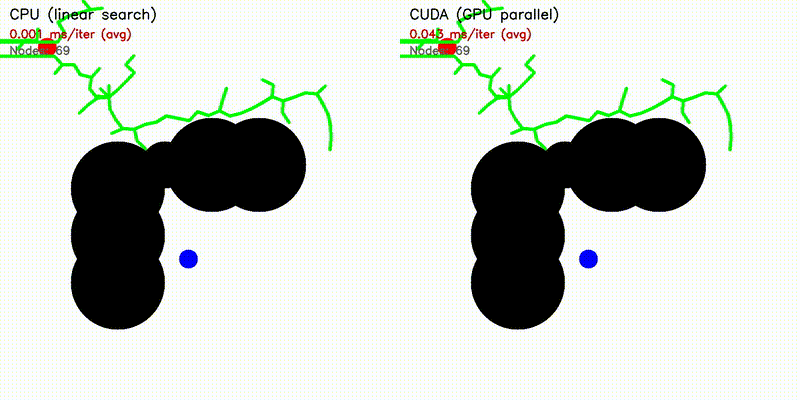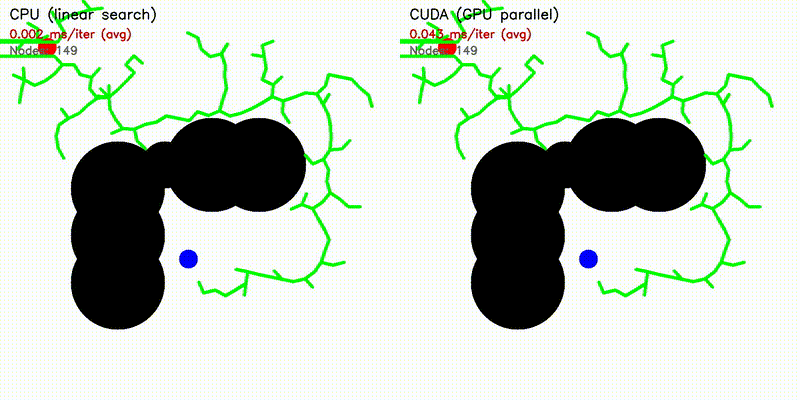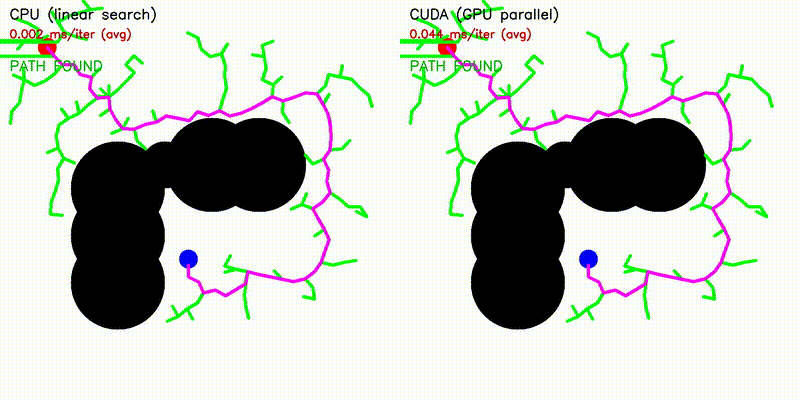 |
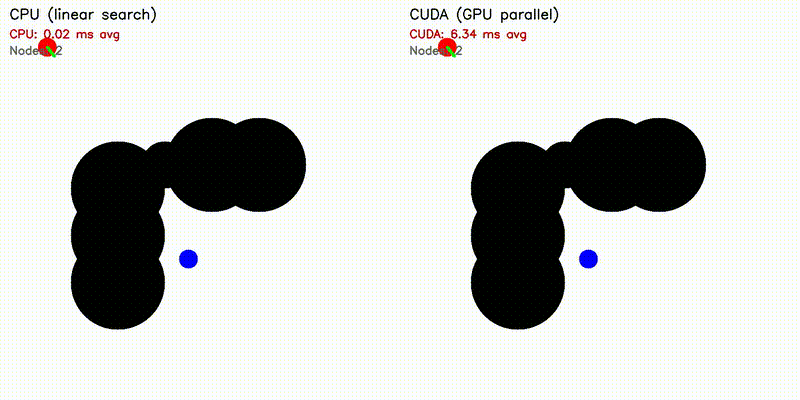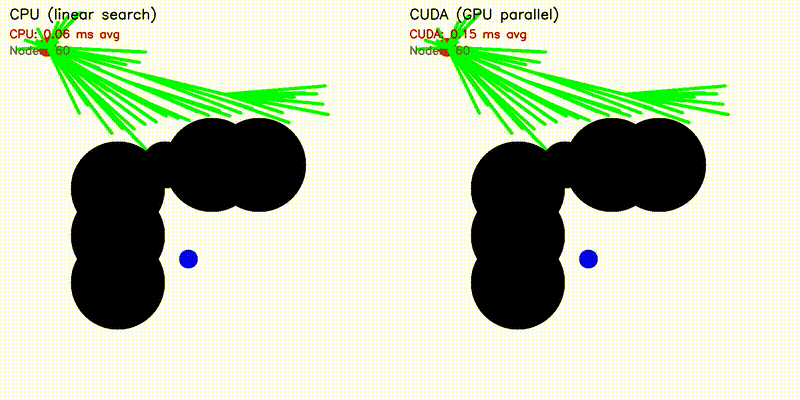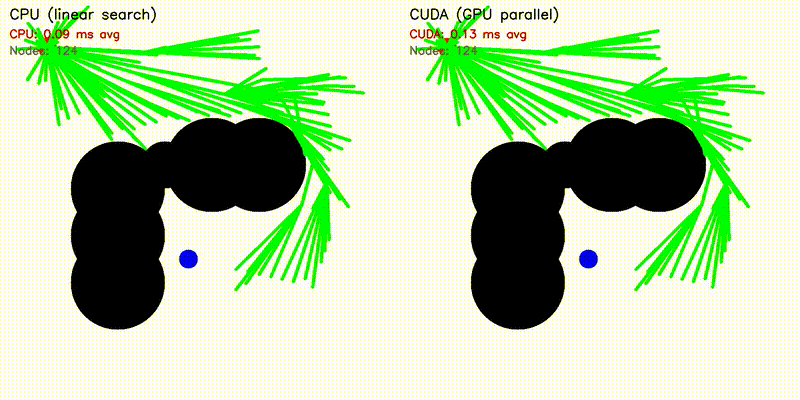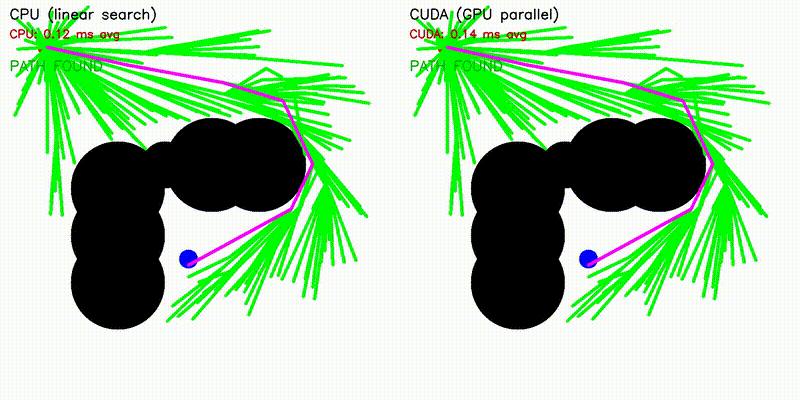 |
| A* | Dijkstra |
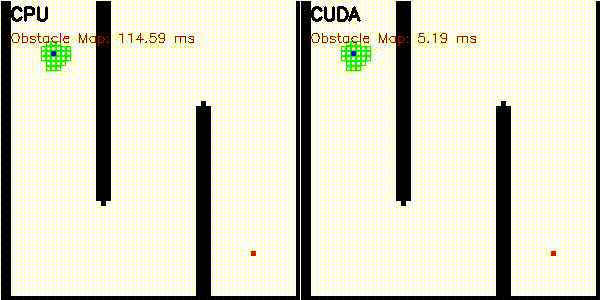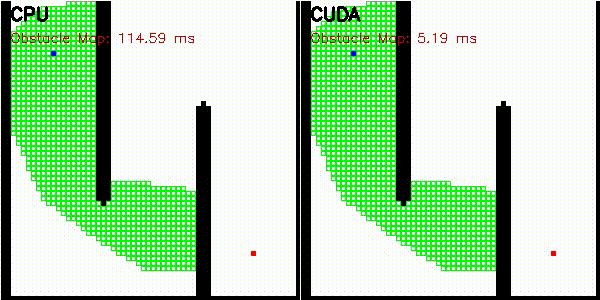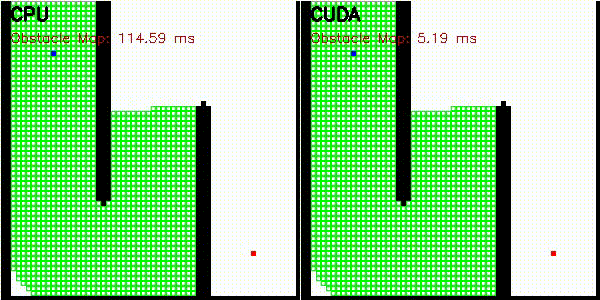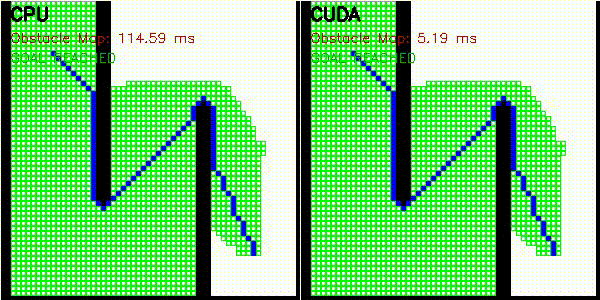 |
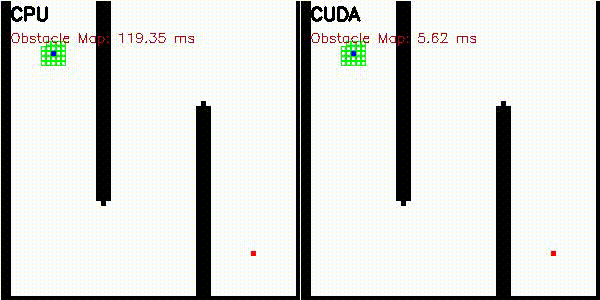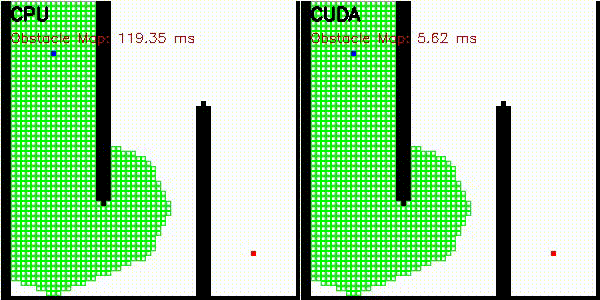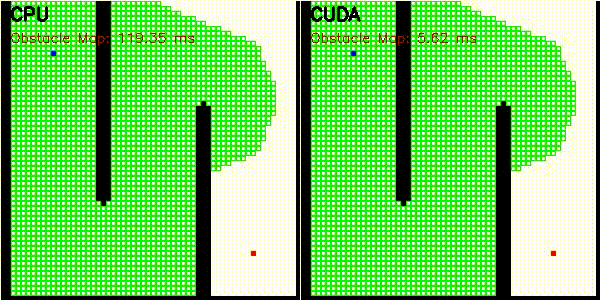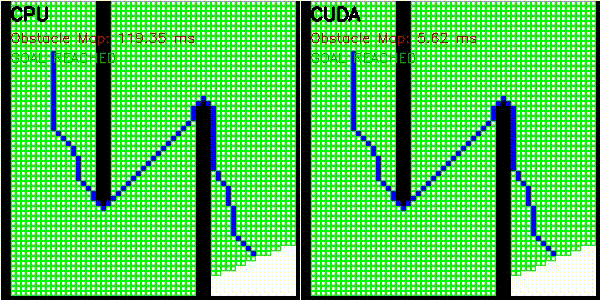 |
| Potential Field | Voronoi Road Map |
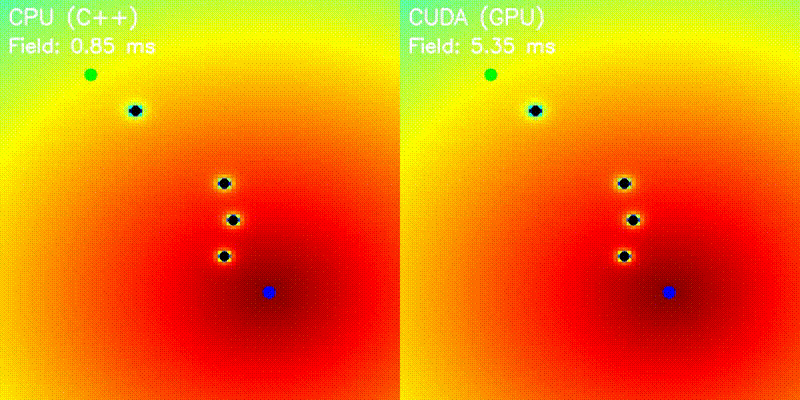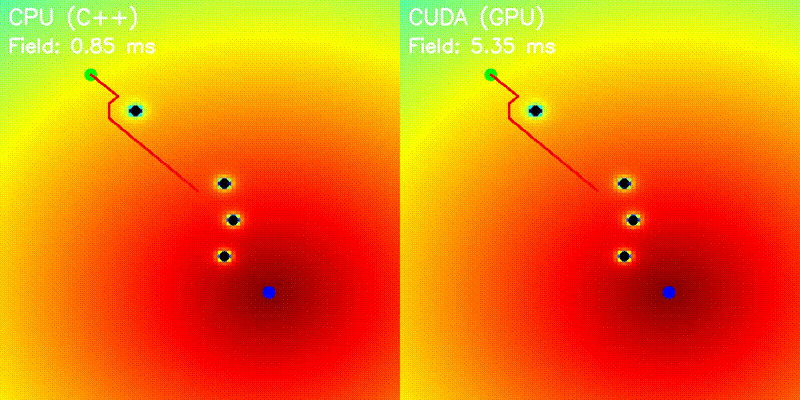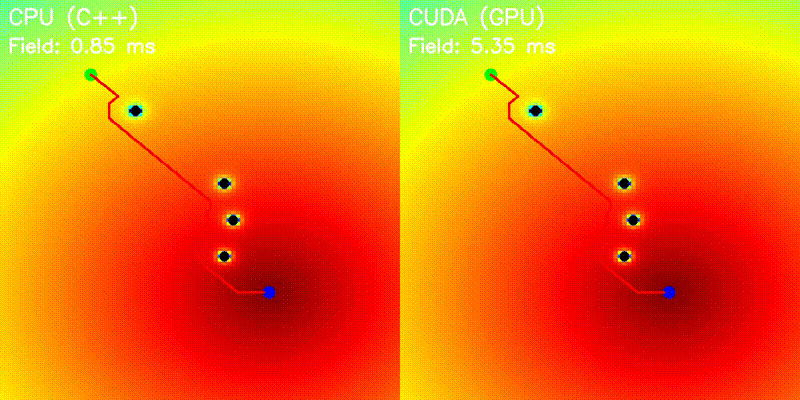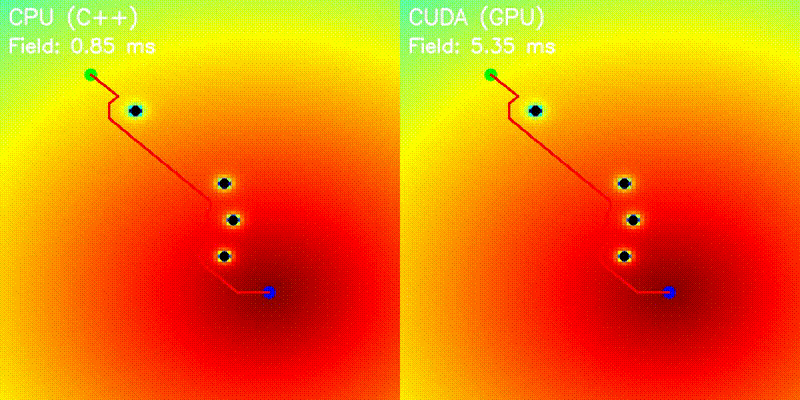 |
 |
| 3D RRT (Drone)* | Occupancy Grid Mapping |
 |
 |
| FastSLAM 1.0 | AMCL |
 |
 |
| Value Iteration (CPU vs CUDA convergence) | Particle Filter on Episode (PFoE, demo) |
 |
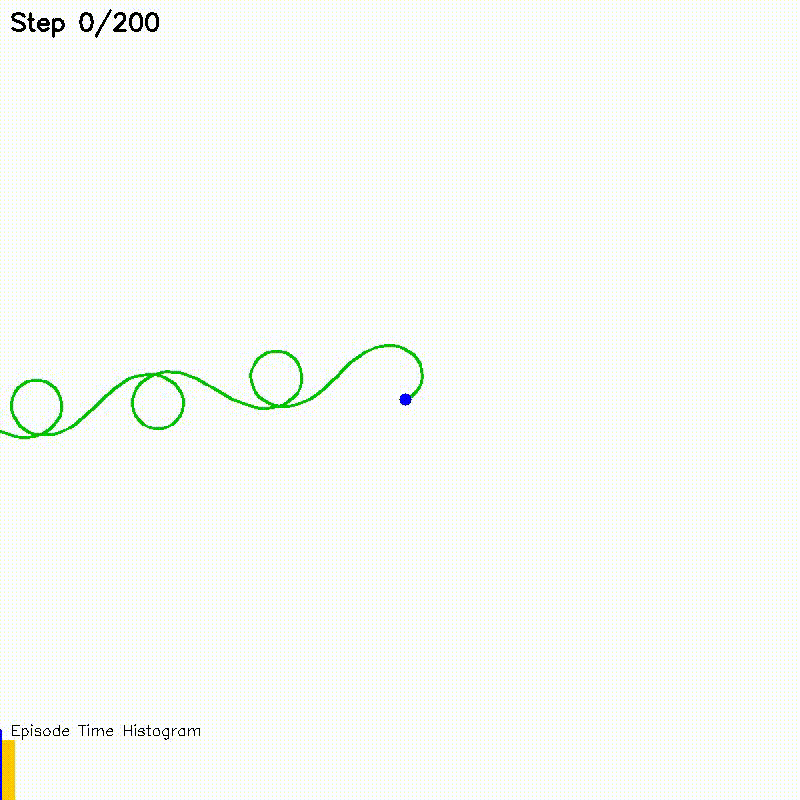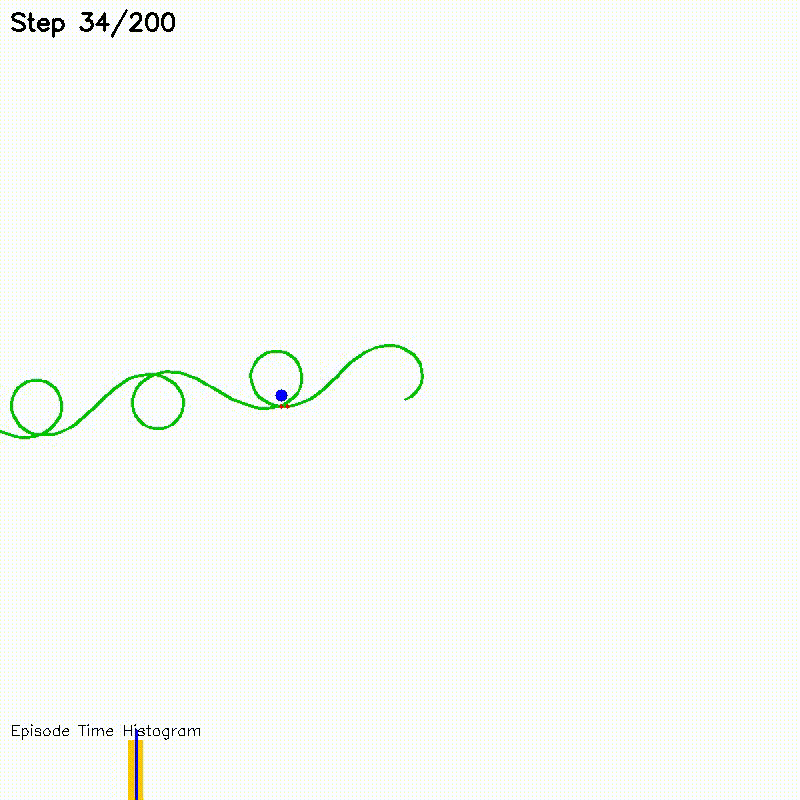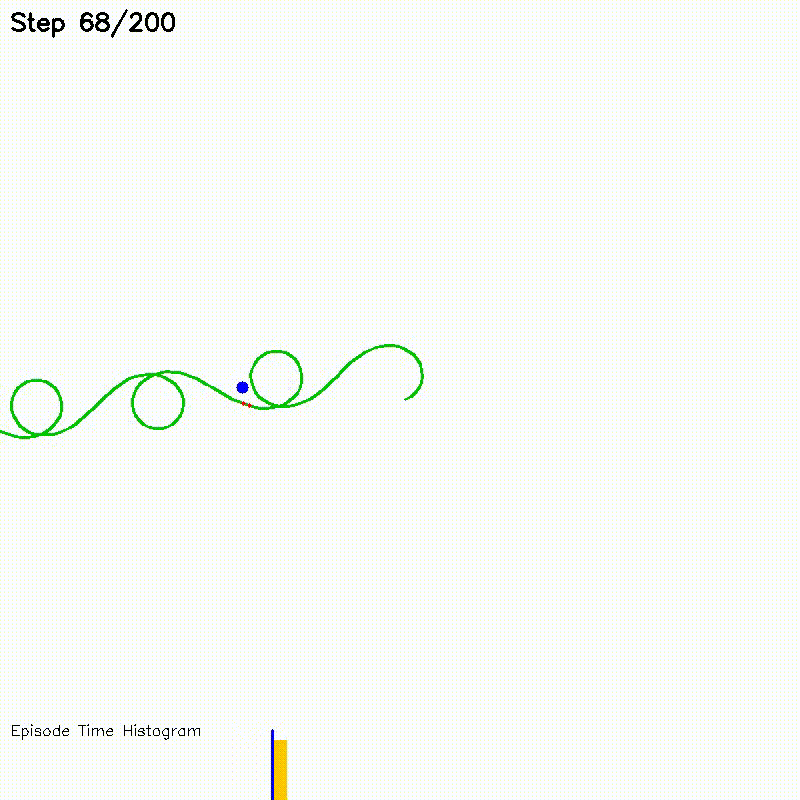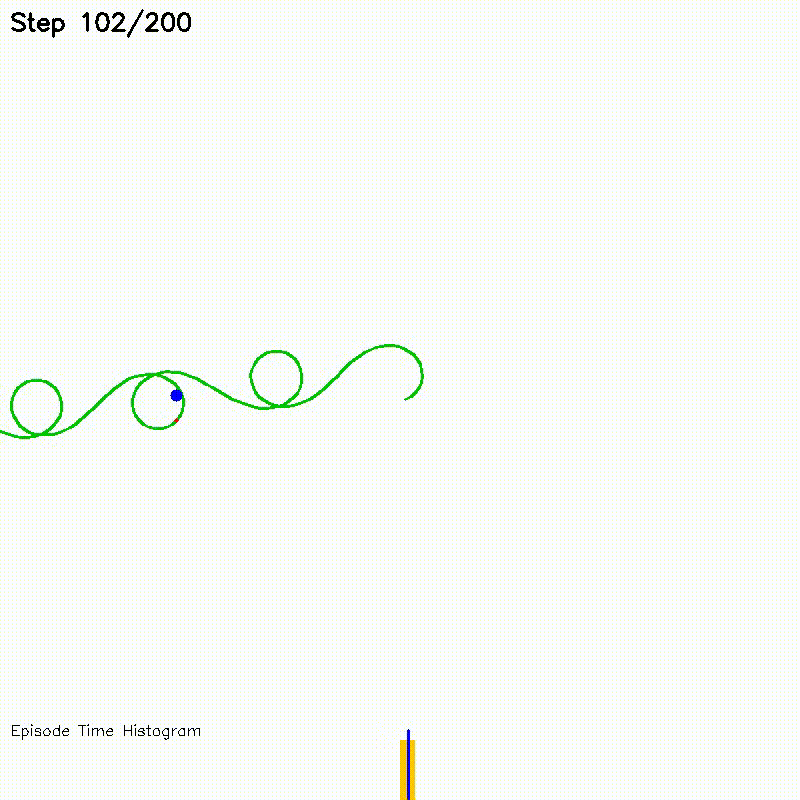 |
Recent additions push the repository beyond direct CUDA ports of classic robotics algorithms into differentiable building blocks, GPU-native learning systems, point-cloud processing, and large-scale swarm optimization.
| Project | Binaries | Highlights |
|---|---|---|
| Autodiff + GPU MLP foundation | test_autodiff, test_gpu_mlp |
Dual-number forward-mode autodiff and a compact GPU MLP training/inference engine used as the base for later research-style experiments. |
| Differentiable MPPI | diff_mppi, comparison_diff_mppi, benchmark_diff_mppi, benchmark_diff_mppi_cartpole, benchmark_diff_mppi_dynamic_bicycle, benchmark_diff_mppi_manipulator, benchmark_diff_mppi_manipulator_7dof |
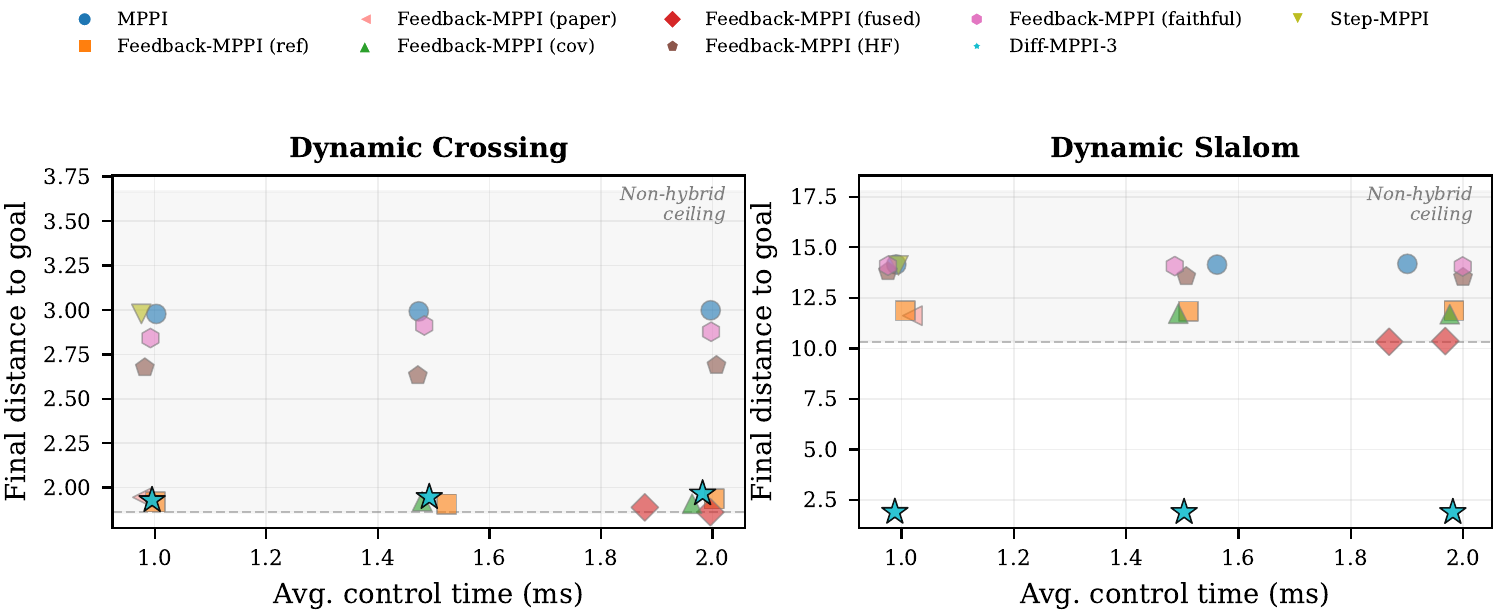
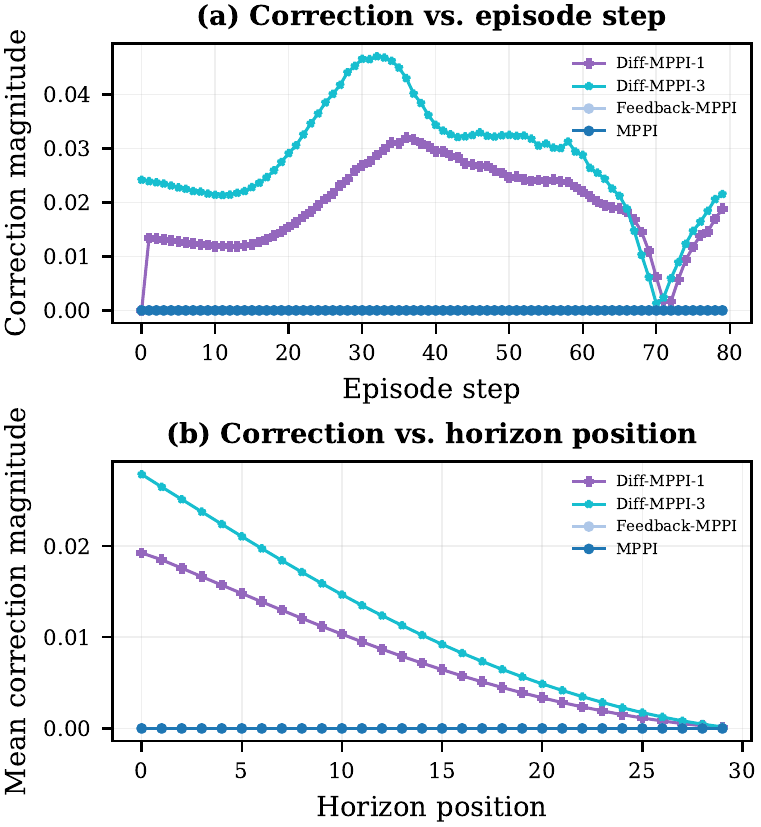
Augments MPPI with a short autodiff refinement stage. Evaluated on 2D dynamic-obstacle navigation, CartPole, dynamic-bicycle, 2-link planar arm, and 7-DOF serial arm. Includes strong in-repo feedback baselines, matched-time tuning, mechanism analysis, MuJoCo transfer checks, and uncertainty follow-ups. On the hard dynamic_slalom task, the hybrid controller is the only method that succeeds in the submission-critical 1.0 ms exact-time table, and the gap survives broader matched-time robustness sweeps. |
| Differentiable Particle Filter | diff_pf, diff_pf_mlp |
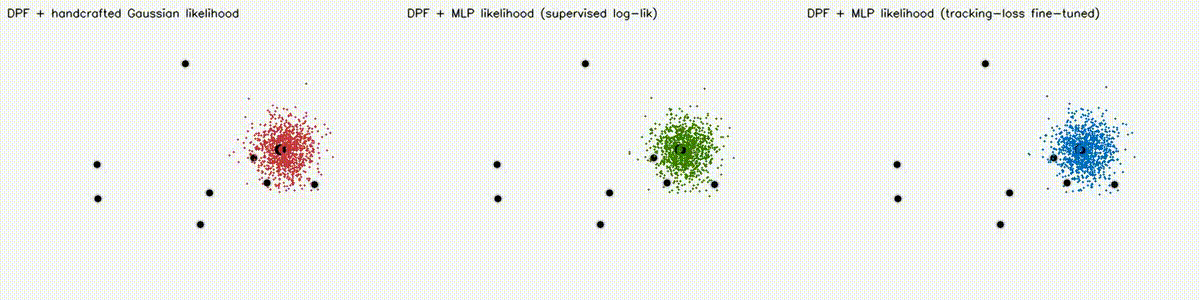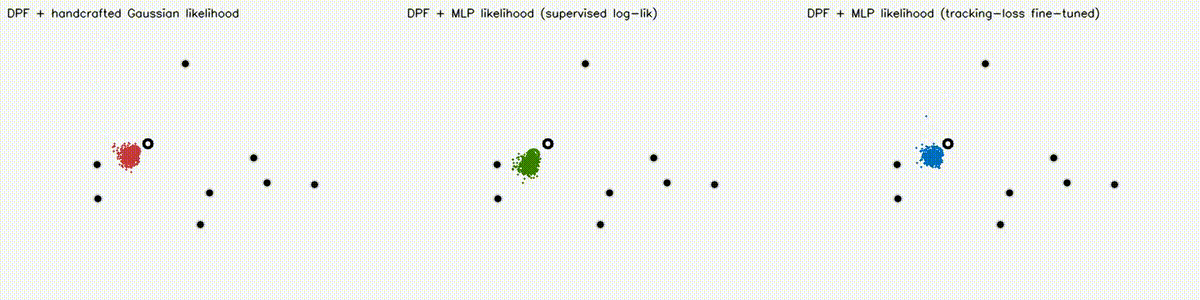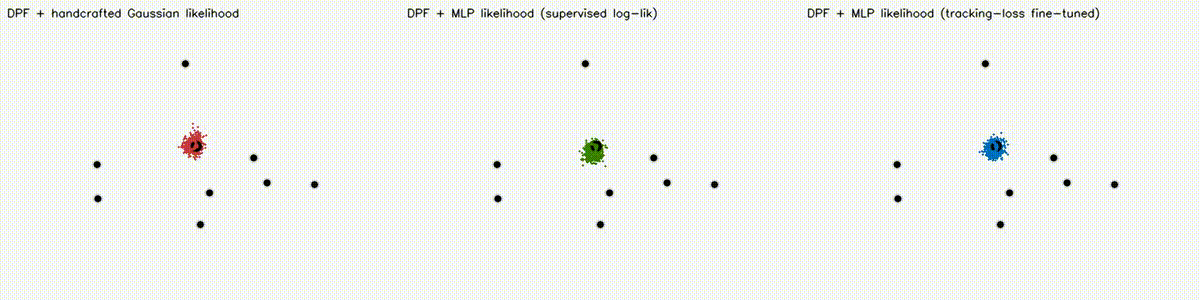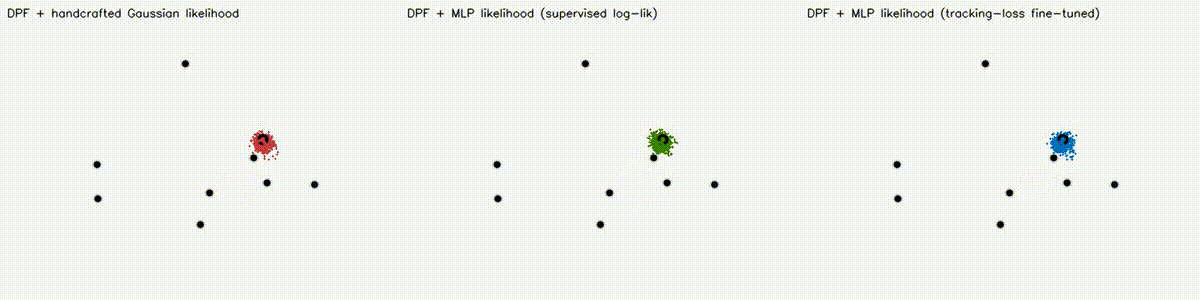
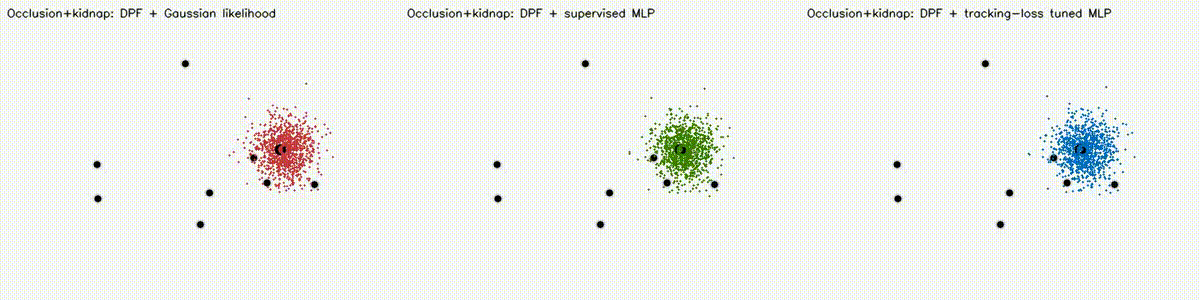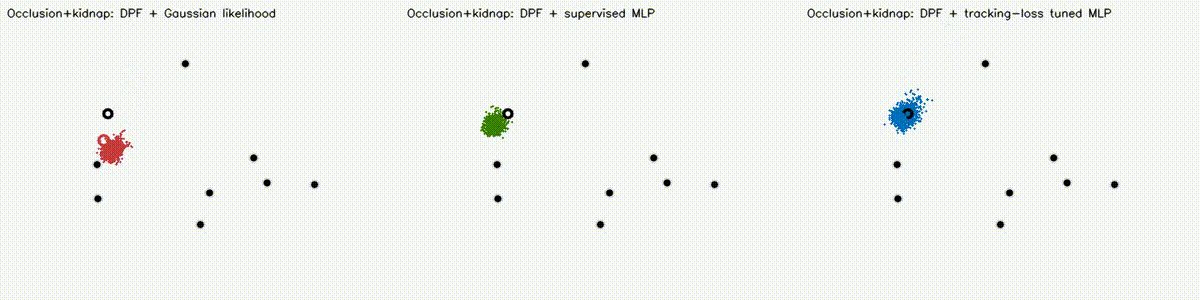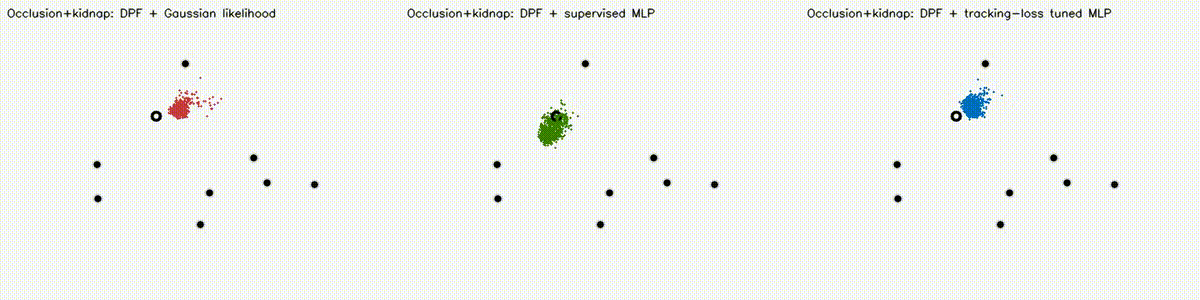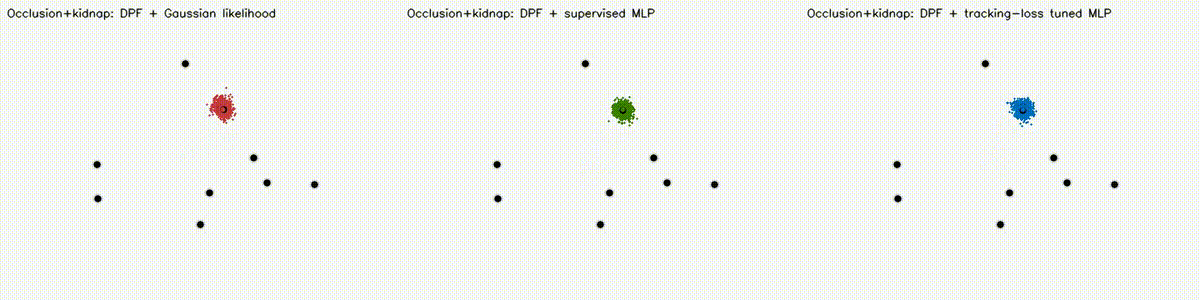
Localization analogue of Diff-MPPI. Soft-resampling kernel (mix likelihood with uniform, importance-corrected) + reparameterized motion noise so the full PF forward pass is autodiff-able via the same dual-number engine. Tuning the motion-noise scale alpha end-to-end on tracking loss drives RMSE from 18.8 m (hand-tuned hard-resample baseline) down to 8.1 m on the 8-landmark 40 m x 30 m scene — a 57% reduction over 120 Adam epochs. diff_pf_mlp swaps the handcrafted Gaussian likelihood for a 2-input, 16-hidden, 1-output MLP that is pre-trained supervised against the analytic log-likelihood, fine-tuned by rollout finite differences, or trained by direct GPU backprop on a differentiable observation surrogate. Latest clean tracking RMSE: handcrafted Gaussian 6.97 m, supervised MLP 7.19 m, tracking-tuned MLP 6.16 m (0.88x handcrafted). In hard scenes, tracking-tuned MLP reaches 6.91 m vs Gaussian 10.27 m under 18% range outliers (0.67x), and 7.56 m vs 10.38 m under occlusion + hidden kidnap (0.73x). Under distance-dependent range bias, direct-surrogate training reaches 5.81 m vs Gaussian 8.33 m (0.70x) in ~2.9 s. |
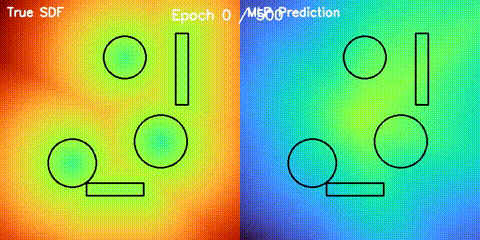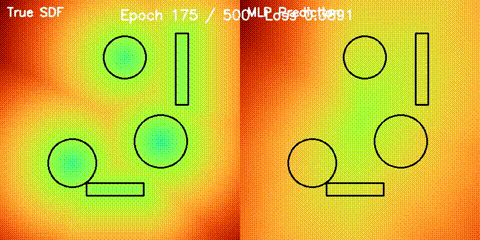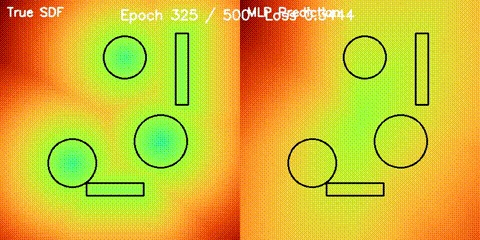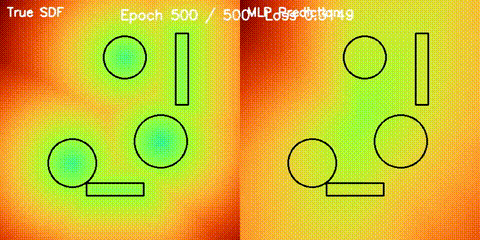
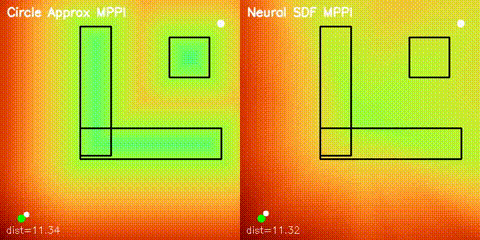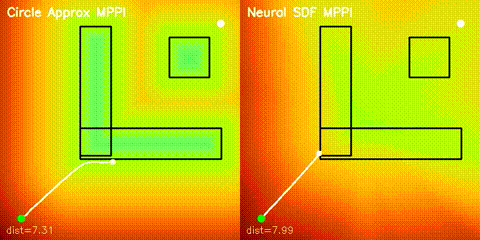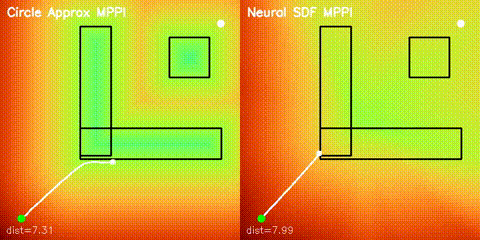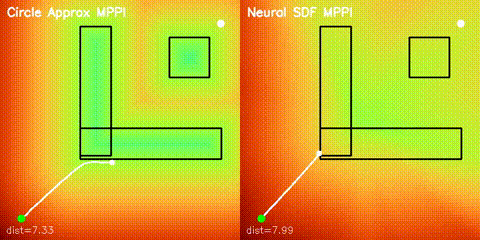
| Neural SDF Navigation | neural_sdf, sdf_potential_field, sdf_mppi, comparison_sdf_nav |
Learns 2D signed distance fields with a GPU MLP, then uses them for potential-field planning and MPPI on non-circular obstacle layouts. |
| Neuroevolution for Cart-Pole | neuroevo, comparison_neuroevo |
Evolves 4096 neural policies in parallel on GPU and compares them against a CPU baseline with side-by-side learning curves. |
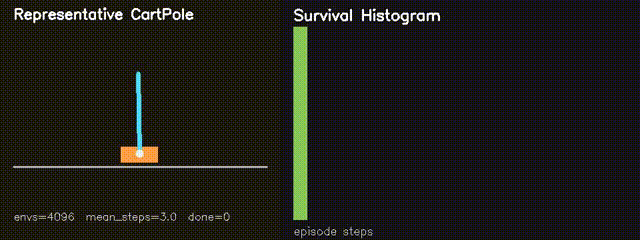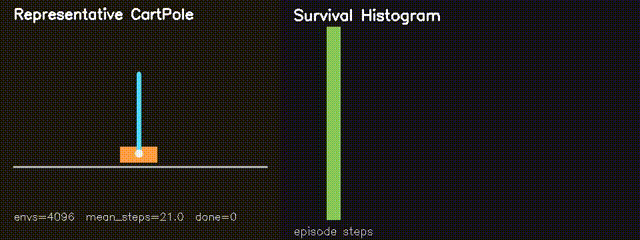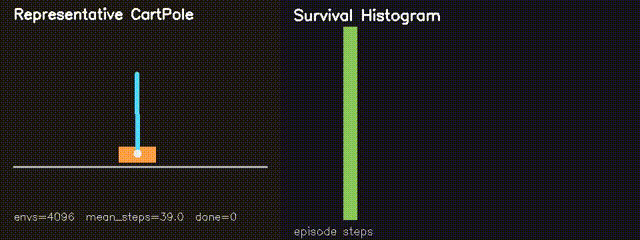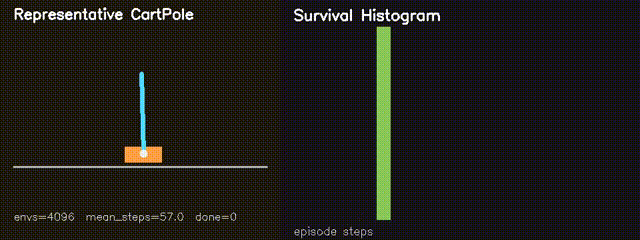
| MiniIsaacGym | mini_isaac, mini_isaac_rl |
Runs thousands of CartPole environments in parallel on GPU and trains a compact policy with GPU-side REINFORCE updates. |
| CudaPointCloud | voxel_grid_filter, statistical_filter, normal_estimation, gicp, ransac_plane, benchmark_pointcloud |
GPU voxel filtering, outlier removal, PCA normals, plane extraction, and GICP registration. Supports PLY/KITTI/XYZ file input. Normal estimation reaches 3,171x speedup at 10K points. |
| Swarm Optimization | pso_cuda, differential_evolution, cma_es, aco_tsp, comparison_swarm |
Large-scale PSO, DE, CMA-ES, and ACO implementations with animated convergence comparisons. |
| MPPI vs Differentiable MPPI | Differentiable MPPI trajectory rollouts |
 |
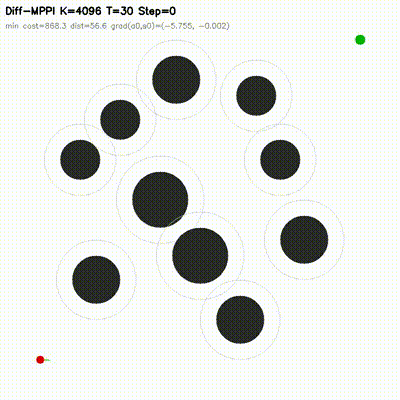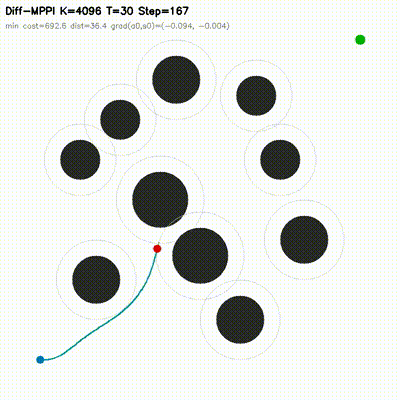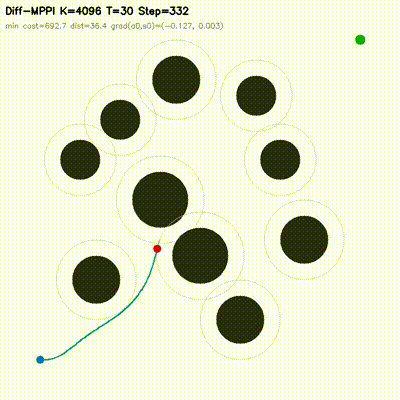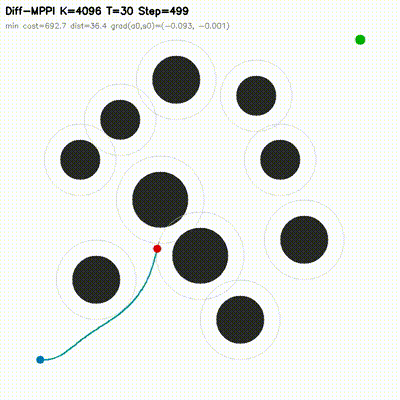 |
| Diff-MPPI exact-time Pareto | Diff-MPPI gradient freshness |
 |
 |
| Diff-MPPI 7-DOF benchmark | Diff-MPPI ablation figure |
 |
 |
| Diff-MPPI task scenarios | Differentiable Particle Filter: hard-resample vs DPF untrained vs DPF trained (3 panels) |
 |
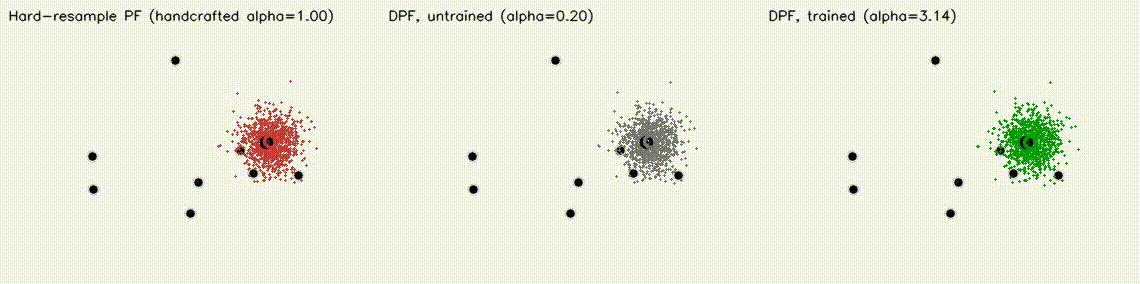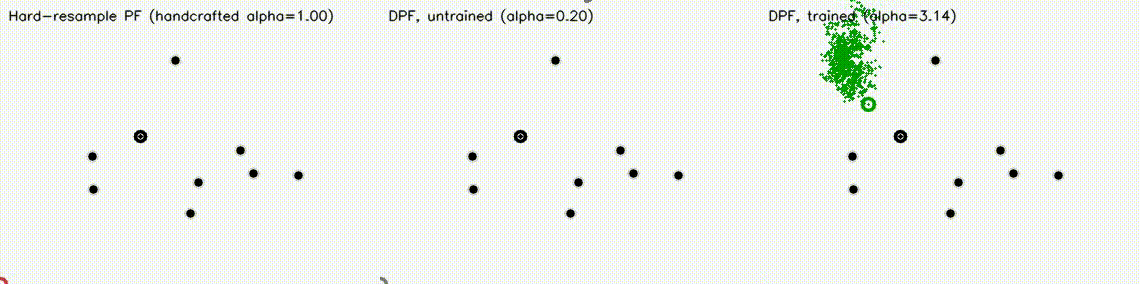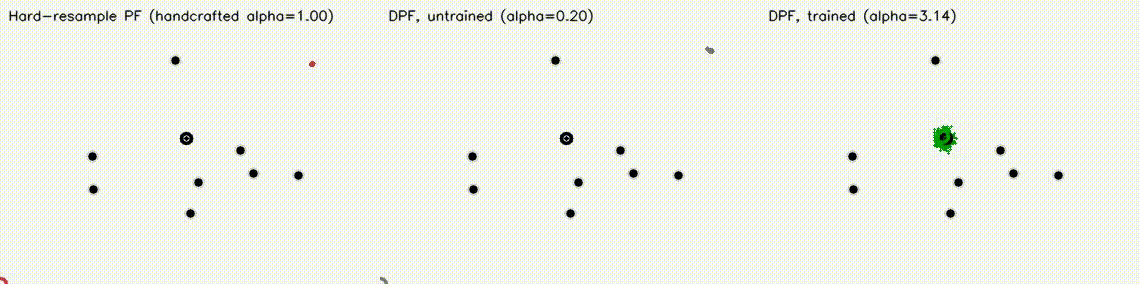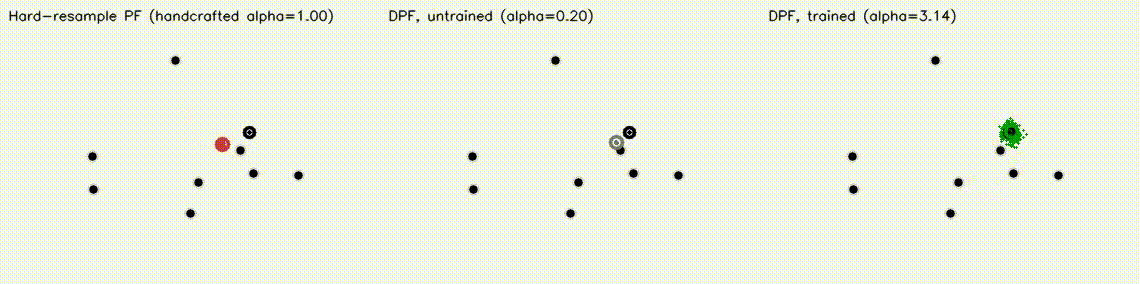 |
| DPF + Gaussian vs supervised MLP vs tracking-loss tuned MLP | DPF MLP hard scene: 18% range outliers |
 |
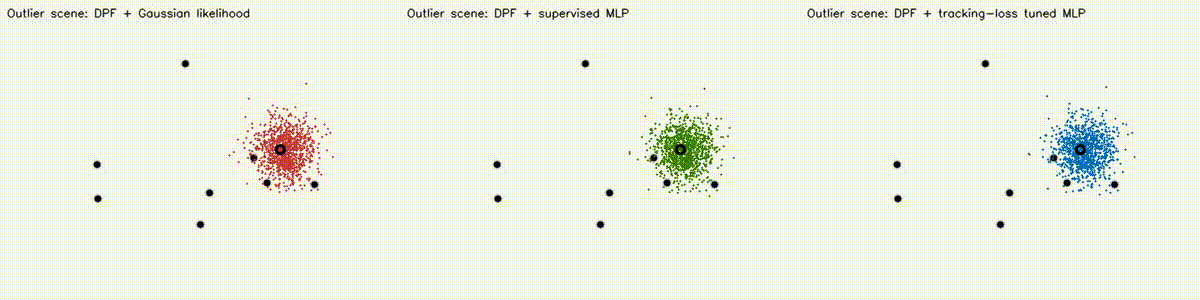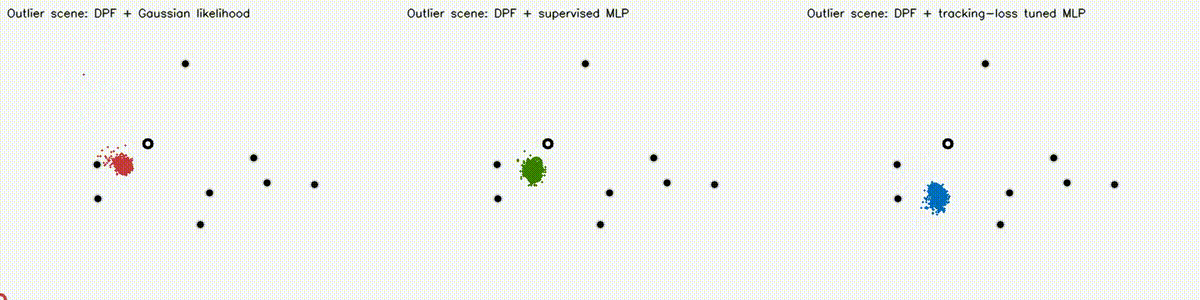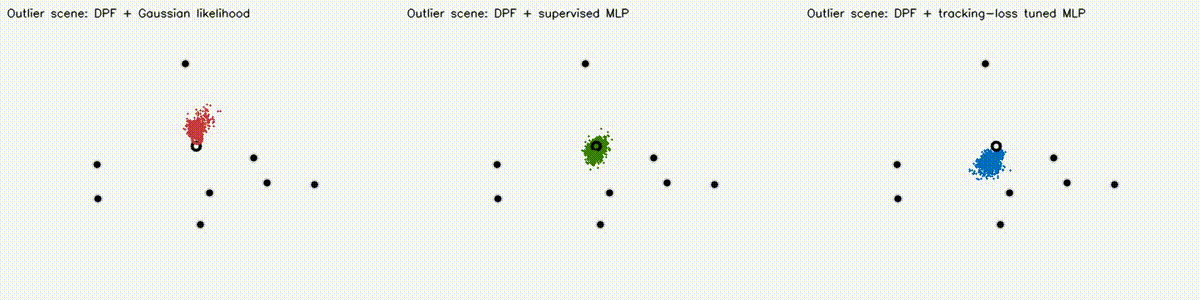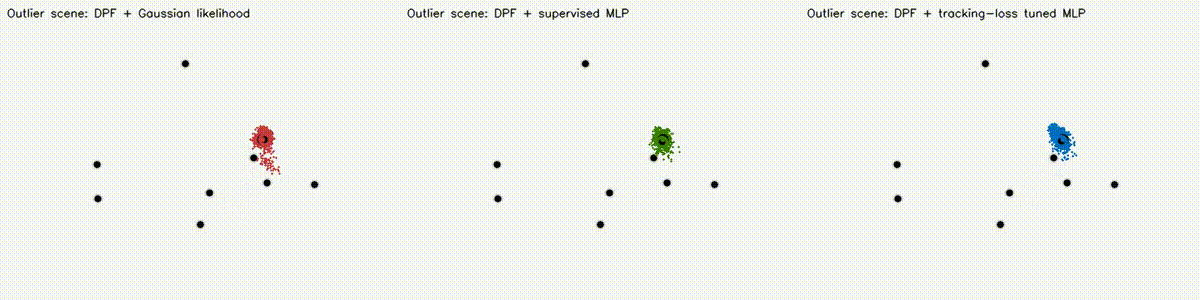 |
| DPF MLP stress scene: occlusion + hidden kidnap | DPF MLP biased-range scene |
 |
 |
| Neural SDF vs true field | Neural SDF MPPI vs circle approximation |
 |
 |
| Neural SDF potential-field navigation | Neural SDF MPPI rollout |
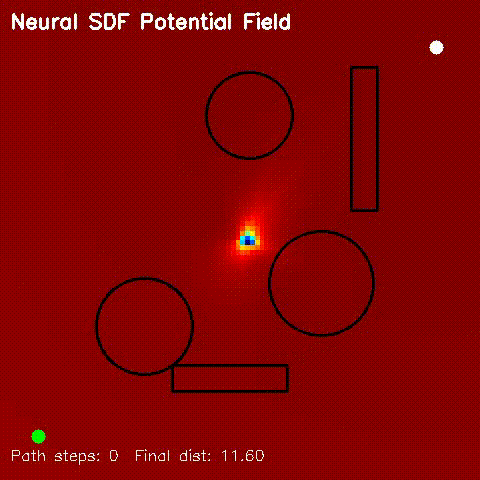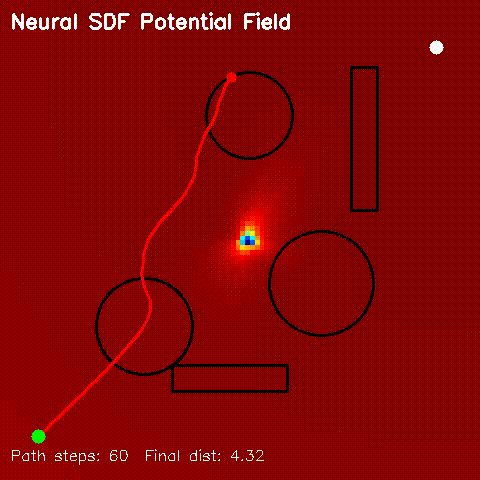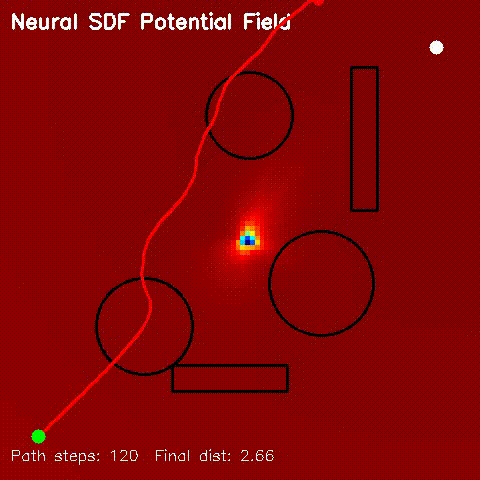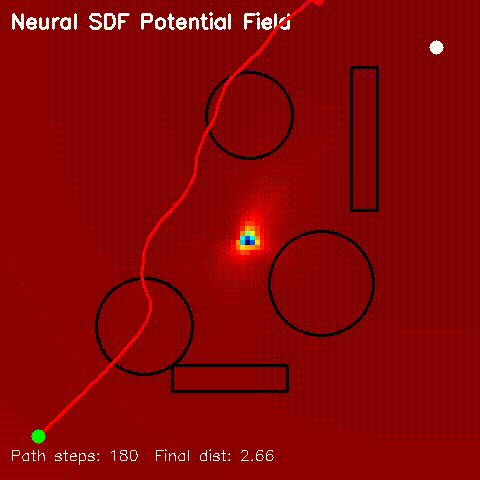 |
 |
| Neuroevolution: CPU 100 vs CUDA 4096 individuals | Swarm Optimization: PSO vs DE vs CMA-ES |
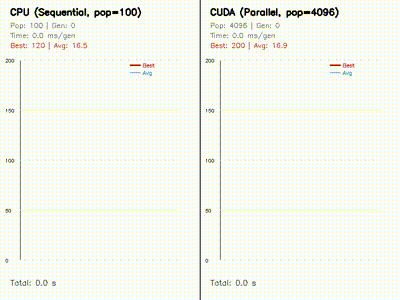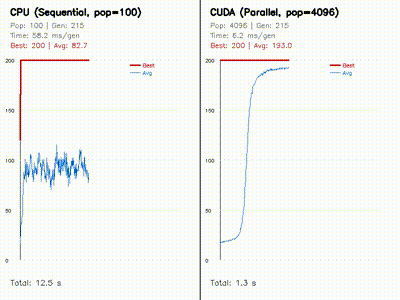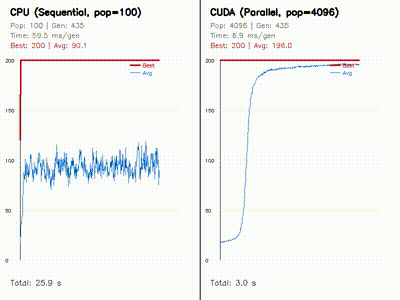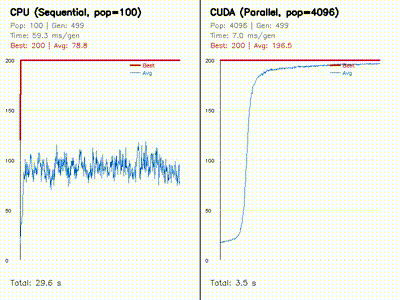 |
 |
| GPU Neuroevolution Cart-Pole replay | Particle Swarm Optimization |
 |
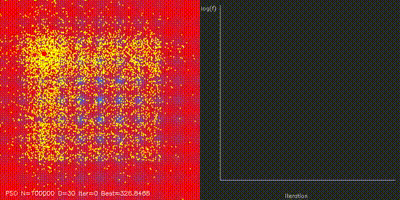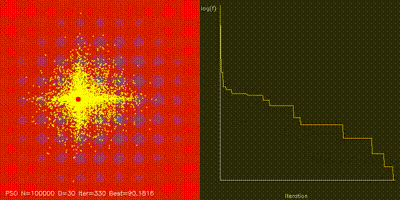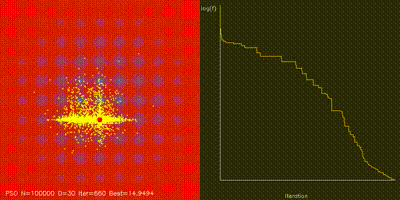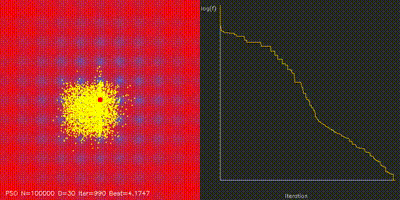 |
| 4096-way CartPole simulation | MiniIsaacGym REINFORCE training |
 |
 |
| Ant Colony Optimization for TSP | |
 |
Text-first highlights for modules without public GIFs yet:
| Module | Why it matters |
|---|---|
| CudaPointCloud | Large benchmarked speedups without approximation-heavy CPU baselines: normal estimation reaches 3,171x at 10K points and RANSAC plane reaches 547x at 100K. |
| MuJoCo transfer checks | InvertedPendulum-v4 and Reacher pilots show the Diff-MPPI stack ports to standardized tasks, even though they are not the main win condition. |
Autodiff + GPU MLP foundation snapshot:
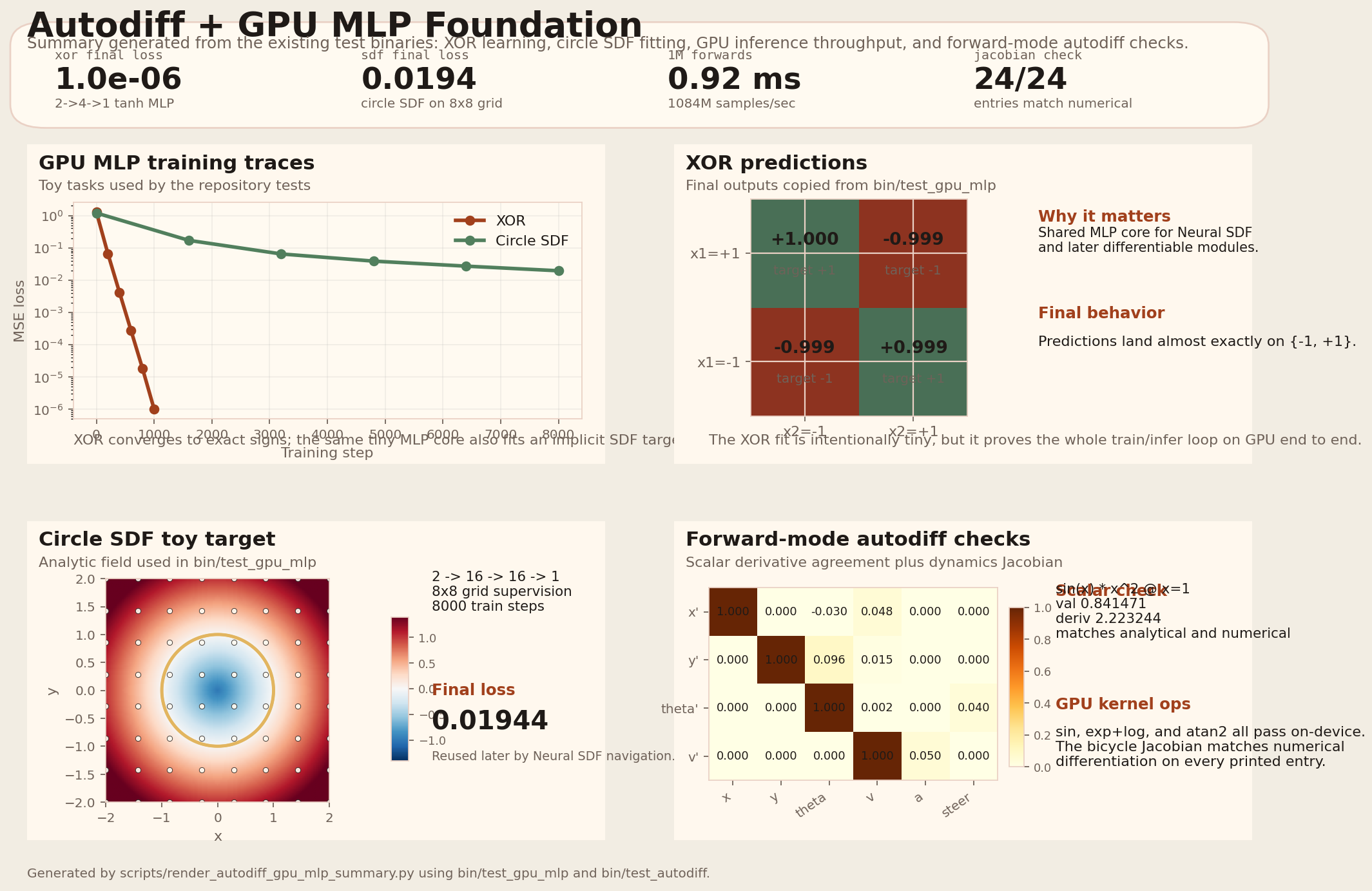
Generated from the existing test binaries with:
python3 scripts/render_autodiff_gpu_mlp_summary.pyRecent research-style additions are summarized on the GitHub Pages gallery:
Reproducible benchmark entry point:
python3 scripts/run_repro_suite.py --dry-run --suite smoke
python3 scripts/run_repro_suite.py --build --suite diff-mppiThe runner records the exact benchmark, summary, and optional plotting commands in build/repro_suite/manifest.json.
See docs/reproducibility.md for the suite catalog and output layout.
Concise highlights:
| Area | Key result |
|---|---|
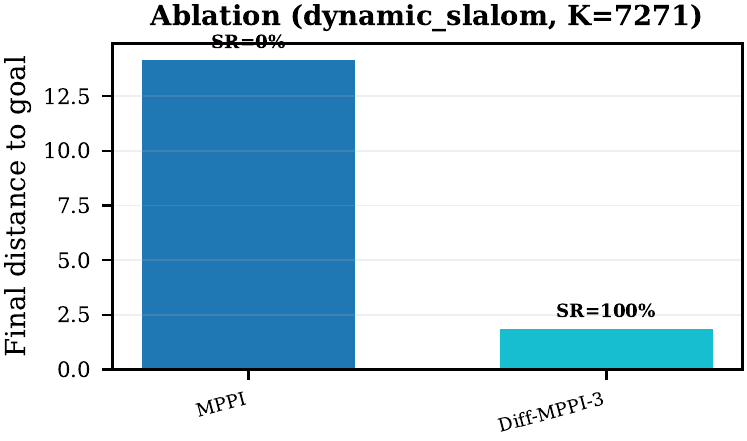
| Diff-MPPI, dynamic navigation | On dynamic_slalom, the submission-critical exact-time table at 1.0 ms still has diff_mppi_3 as the only successful controller (dist 1.90), while feedback_mppi_fused reaches 10.33, feedback_mppi_paper 11.61, and mppi 14.15. The harder family-level matched-time sweep keeps the same qualitative split: the best non-hybrid family still fails while the best Diff family succeeds. |
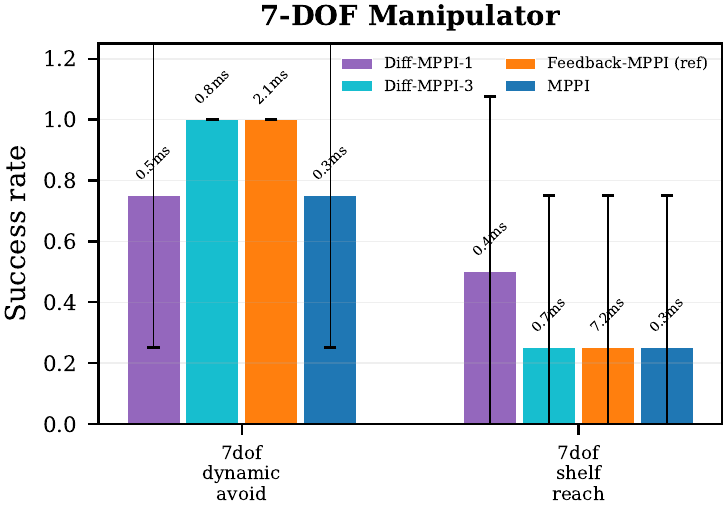
| Diff-MPPI, 7-DOF manipulator | At K=512 on 7dof_dynamic_avoid: diff_mppi_3 reaches success=1.00 at 0.84 ms, while feedback_mppi_ref reaches 0.75 at 4.01 ms. The hybrid controller is 4.8x faster and more reliable. |
| Diff-MPPI, 2-link manipulator | On arm_static_shelf at K=256: feedback_mppi_ref and feedback_mppi_cov both reach success=1.00 at 0.15 final distance, while vanilla MPPI stays at 0.00. |
| Diff-MPPI, faithful baseline | Both feedback_mppi_paper (covariance-regression + LQR, every-step) and feedback_mppi_faithful (two-rate, current-action-only) fail on dynamic tasks, confirming that gradient refinement provides complementary value no feedback architecture can replicate. |
| Diff-MPPI, ablation | step_mppi (learned sampling bias) performs at vanilla MPPI level (dist 14.25 vs 14.23), showing that improved sampling alone cannot solve dynamic obstacle tasks—gradient refinement is the key mechanism. |
| Neural SDF navigation | Learned 2D SDFs with potential-field planning and MPPI rollouts on non-circular obstacle layouts. |
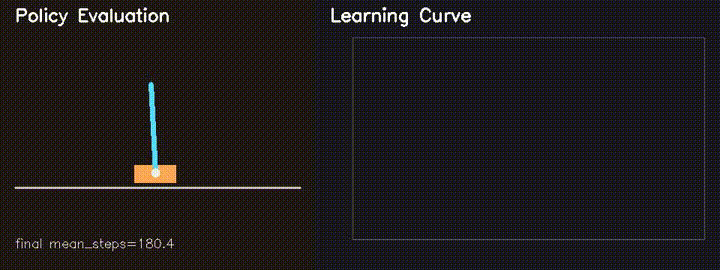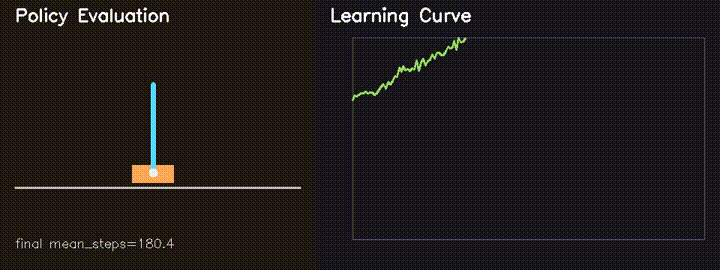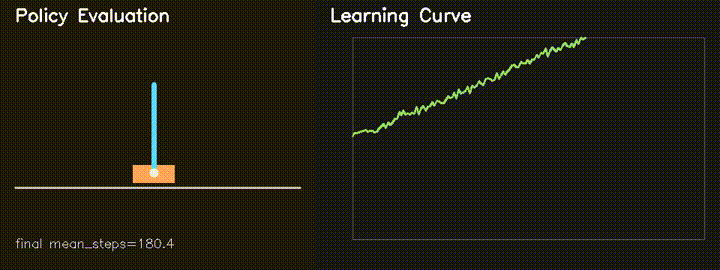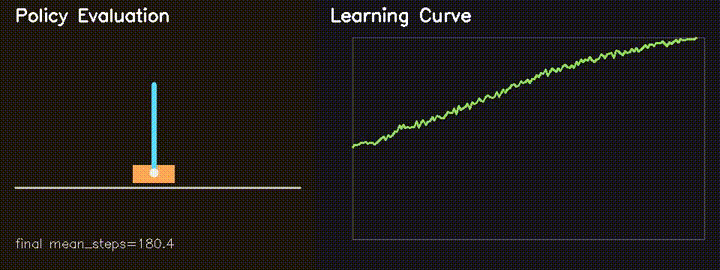
| MiniIsaacGym RL | GPU REINFORCE CartPole: average survival 82.6 to 180.4 steps in 160 generations. |
| CudaPointCloud | Normal estimation reaches 3,171x speedup at 10K points, RANSAC plane 547x at 100K. Supports --ply/--kitti/--xyz file input. |
| Swarm / neuroevolution | GPU PSO, DE, CMA-ES, ACO, and 4096-way neuroevolution with animated comparisons. |
Entry points (full commands, follow-up suites, and detailed numbers live under paper/diff_mppi_*_followup.md):
./bin/benchmark_diff_mppi --quick
python3 scripts/summarize_diff_mppi.py --csv build/benchmark_diff_mppi.csv
python3 scripts/plot_diff_mppi.py --csv build/benchmark_diff_mppi.csv --out-dir build/plots
python3 scripts/tune_diff_mppi_time_targets.py --preset dynamic_navOut-of-domain transfer pilots: benchmark_diff_mppi_cartpole, benchmark_diff_mppi_dynamic_bicycle, benchmark_diff_mppi_manipulator, benchmark_diff_mppi_manipulator_7dof.
benchmark_diff_mppi now hosts a 12-planner sweep across 3 dynamic scenarios x 5 speed-scales x 2 radius-scales x 4 seeds, surfacing where DWA, STOMP, Diff-MPPI, and the Hybrid A* family each win. Detailed report: docs/local_planner_comparison.md. Hybrid A* design notes: docs/hybrid_astar_baseline.md.
Headline on the hard half (dyn_speed_scale >= 1.5):
| planner | family | hard solved | mean coll | mean ms |
|---|---|---|---|---|
| dwa_med / dwa_fine | DWA | 12/12 | 0.00 | 0.06 |
| hybrid_astar_dwa | Hybrid-A* | 12/12 | 0.00 | 0.07 |
| hybrid_astar_mppi | Hybrid-A* | 11/12 | 0.00 | 0.56 |
| stomp_3_smooth | STOMP | 6/12 | 0.00 | 1.41 |
| diff_mppi_3_early8 | Diff-MPPI | 5/12 | 1.40 | 0.66 |
| hybrid_astar_pp | Hybrid-A* | 3/12 | 15.58 | 0.02 |
| hybrid_astar_dyn_pp | Hybrid-A* | 2/12 | 15.92 | 0.02 |
Findings:
- DWA wins decisively on this benchmark (argmin + tuned w_terminal=20).
- Global + local hybrid closes the paradigm gap for both DWA and MPPI locals; the pattern is paradigm-agnostic.
- Dyn-aware global search alone is brittle -- the constant-speed search vs. accelerate-from-rest sim timing mismatch makes linearised obstacle prediction worse than blind on hard cells.
bin/benchmark_pointcloud compares CPU vs GPU voxel filter, statistical outlier removal, normal estimation, RANSAC plane, and GICP. Both sides use the same brute-force algorithms (no KD-trees). Supports --ply, --kitti, --xyz external input; --op selects voxel/statistical/normals/ransac/gicp/all.
./bin/benchmark_pointcloud --quick
./bin/benchmark_pointcloud --xyz examples/pointcloud/sample_room.xyz --input-only --op ransac --plane-threshold 0.05 --out build/sample_room_plane.plySynthetic-room speedups (CPU O(n^2) baseline; GPU loses on tiny n due to kernel launch overhead):
| Points | Operation | CPU | GPU | Speedup |
|---|---|---|---|---|
| 1,000 | Voxel Grid | 0.67 ms | 1.76 ms | 0.4x |
| 2,000 | Statistical Filter | 339 ms | 0.82 ms | 412x |
| 10,000 | Normal Estimation | 15,487 ms | 4.88 ms | 3,171x |
| 100,000 | RANSAC Plane | 3,077 ms | 5.62 ms | 547x |
- CMake >= 3.18
- CUDA Toolkit >= 11.0
- OpenCV 3.x / 4.x
- Eigen 3
mkdir build
cd build
cmake ../
make -j8Executables are in bin/.
Some design work in this repo follows experiment -> convergence, not abstract design -> implementation:
core/: minimum interfaces shared by multiple variantsexperiments/: discardable concrete variants in different paradigms (functional / OOP / pipeline)docs/: generated process state (experiments.md,decisions.md,interfaces.md)
Current concrete problems (each has 3 paradigm-distinct variants):
planner_selection,fixture_promotion,time_budget_selection,horizon_selection
Entry points (full list in docs/experiments.md):
python3 scripts/run_design_experiments.py # regenerate comparison docs
python3 scripts/design_doctor.py # one-command refresh + validate
python3 scripts/validate_design_workflow.py # CI guard
python3 scripts/scaffold_design_problem.py <slug> --dry-run # new problem with 3 variantsSnapshot / regression / promotion machinery lives under scripts/{snapshot,check,compare,render}_*.py; policies are in experiments/history/*.json. Reusable helpers are extracted into experiments/support.py before any variant is considered for promotion.
docker build -t cuda-robotics .
docker run --gpus all cuda-robotics ./bin/benchmark_pfRequires NVIDIA Container Toolkit.
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| Particle Filter | pf |
1000 particles: predict + weight update + resampling |
| Extended Kalman Filter | (CPU only) | 4x4 matrices - no GPU benefit |
| AMCL | amcl |
Adaptive particle count + GPU likelihood field + KLD-sampling |
| FastSLAM 1.0 | fastslam1 |
Particle x Landmark parallel EKF update (SLAM) |
| Graph SLAM | graph_slam |
GPU pose graph optimization with CG solver (SLAM) |
| PF on Episode | pf_on_episode |
Particle-filter localization over full trajectory episodes |
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| A* | astar_cuda |
Obstacle map construction (grid cells in parallel) |
| Dijkstra | dijkstra_cuda |
Obstacle map construction (grid cells in parallel) |
| RRT | rrt_cuda |
Nearest neighbor search + collision checking |
| RRT* | rrtstar_cuda |
Nearest neighbor + near nodes + rewiring + collision |
| RRT Reeds-Shepp* | rrtstar_rs_cuda |
Batch RS path computation + collision check (nonholonomic) |
| Massive Reeds-Shepp Fan | comparison_reeds_shepp_fan |
1M 3-segment RS candidate paths from a parking-lot start pose per frame, with collision check and argmin reduction (5000x per-path throughput vs CPU) |
| Informed RRT* | informed_rrtstar_cuda |
Ellipsoidal sampling + parallel NN/rewiring |
| 3D RRT* | rrtstar_3d_cuda |
3D nearest neighbor + 3D collision (drone/UAV) |
| Dynamic Window Approach | dwa |
~120K velocity samples evaluated in parallel |
| Frenet Optimal Trajectory | frenet |
~140 candidate paths: polynomial solve + spline + collision |
| State Lattice Planner | slp_cuda |
Parallel lookup table search + trajectory optimization |
| Potential Field | potential_field |
Grid-parallel potential computation (attractive + repulsive) |
| 3D Potential Field | potential_field_3d |
3D grid-parallel potential (216K+ cells, drone/UAV) |
| MPPI | mppi |
4096-sample path-integral control on GPU |
| Hybrid A family* | benchmark_diff_mppi --planners hybrid_astar_{pp,dwa,dyn_pp,mppi} |
Forward-only Hybrid A global path + four local controllers (pure pursuit, DWA, dyn-aware-search + pp, MPPI). Demonstrates the paradigm gap: blind global + pp solves 3/12 hard cells, global + DWA/MPPI local closes the gap to 11-12/12* |
| Differentiable MPPI | diff_mppi, comparison_diff_mppi, benchmark_diff_mppi, benchmark_diff_mppi_cartpole, benchmark_diff_mppi_dynamic_bicycle, benchmark_diff_mppi_manipulator |
MPPI sampling update + autodiff control-gradient refinement + multi-scenario CSV benchmarking under fixed sample and wall-clock caps, plus nominal-linearization / rollout-sensitivity / covariance-regression / fused-feedback / high-frequency-feedback baselines, uncertain-dynamic follow-up, CartPole, dynamic-bicycle, and planar-manipulator pilots outside the base kinematic suite |
| Neural SDF Navigation | neural_sdf, sdf_potential_field, sdf_mppi, comparison_sdf_nav |
Learned implicit obstacle fields for heatmap visualization, potential fields, and MPPI |
| PRM | prm_cuda |
Parallel collision check + k-NN + edge collision |
| Voronoi Road Map | voronoi_road_map |
Jump Flooding Algorithm for parallel Voronoi diagram |
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| ICP | icp |
GPU nearest-neighbor correspondences + batch transform updates |
| NDT | ndt |
Voxelized normal-distribution matching kernels |
| GICP | gicp |
GPU correspondences + point-to-plane system accumulation |
| Voxel Grid Filter | voxel_grid_filter |
Point-wise voxel assignment + centroid accumulation |
| Statistical Outlier Removal | benchmark_pointcloud |
Brute-force GPU k-NN mean-distance filtering |
| Normal Estimation | benchmark_pointcloud |
PCA normal estimation with one thread per point |
| RANSAC Plane | ransac_plane |
One RANSAC hypothesis per thread with device-side RNG |
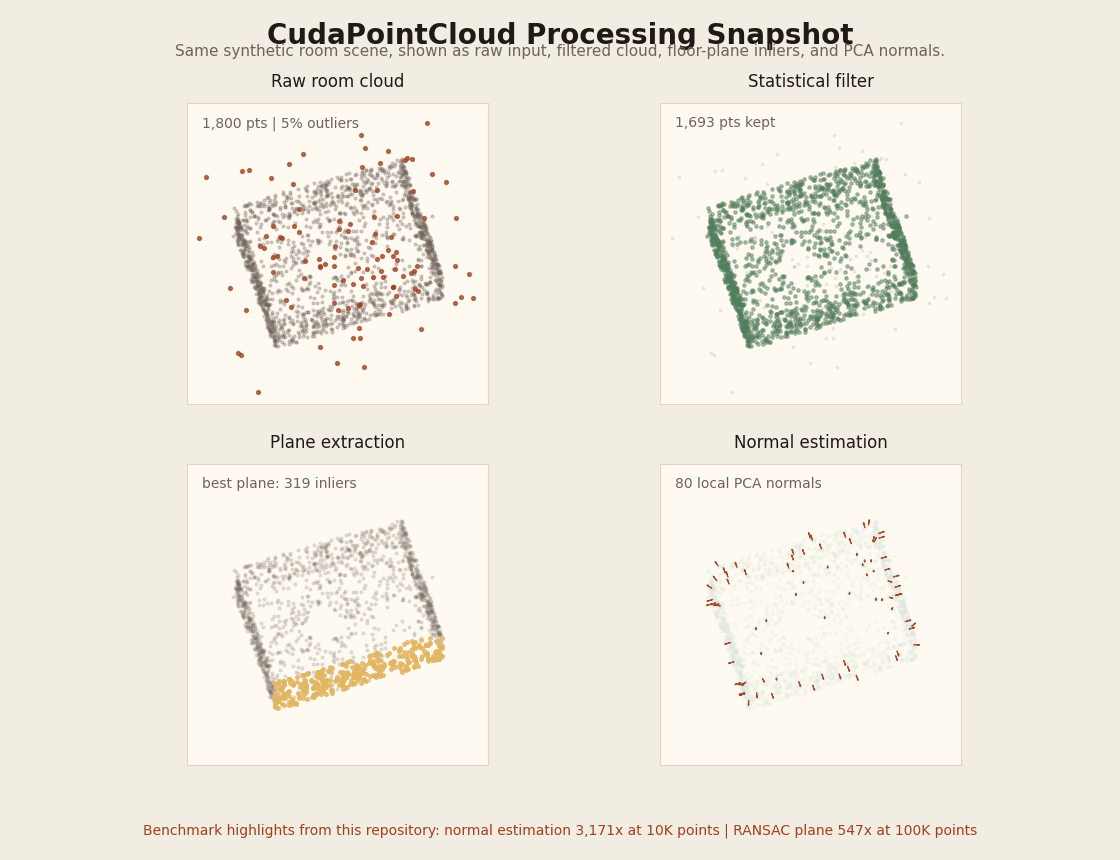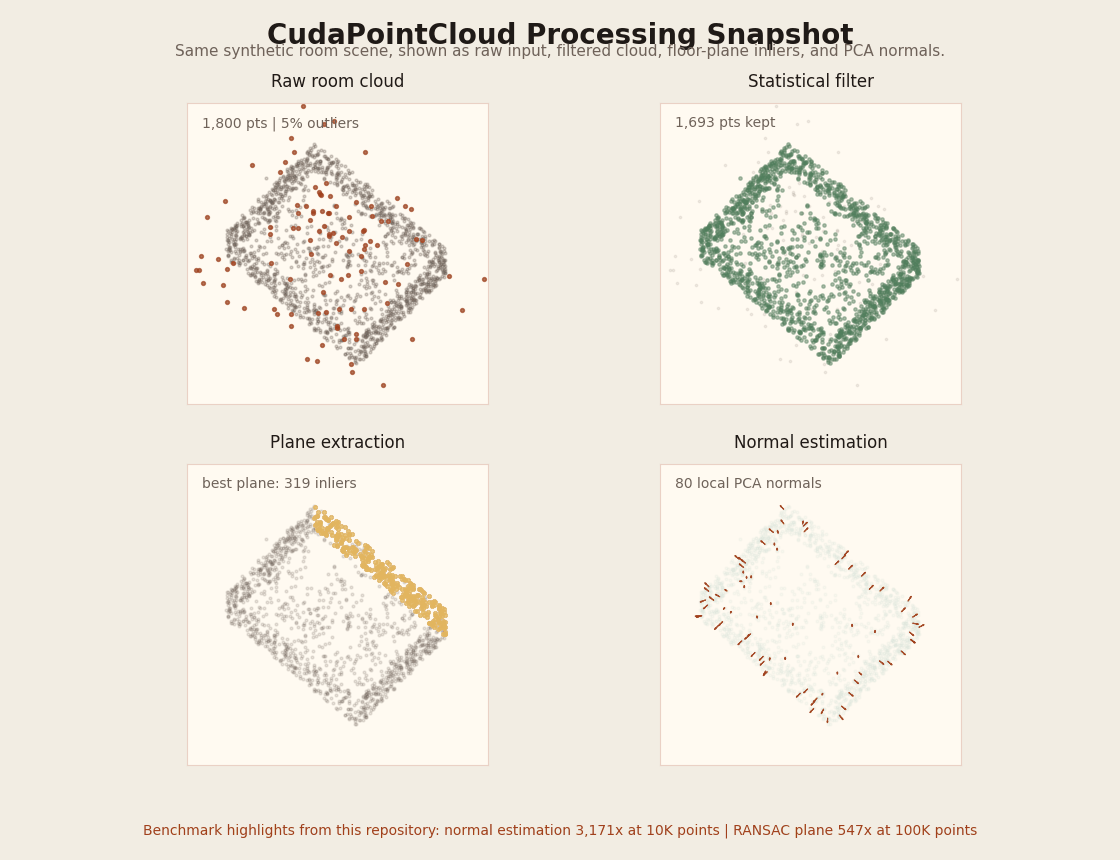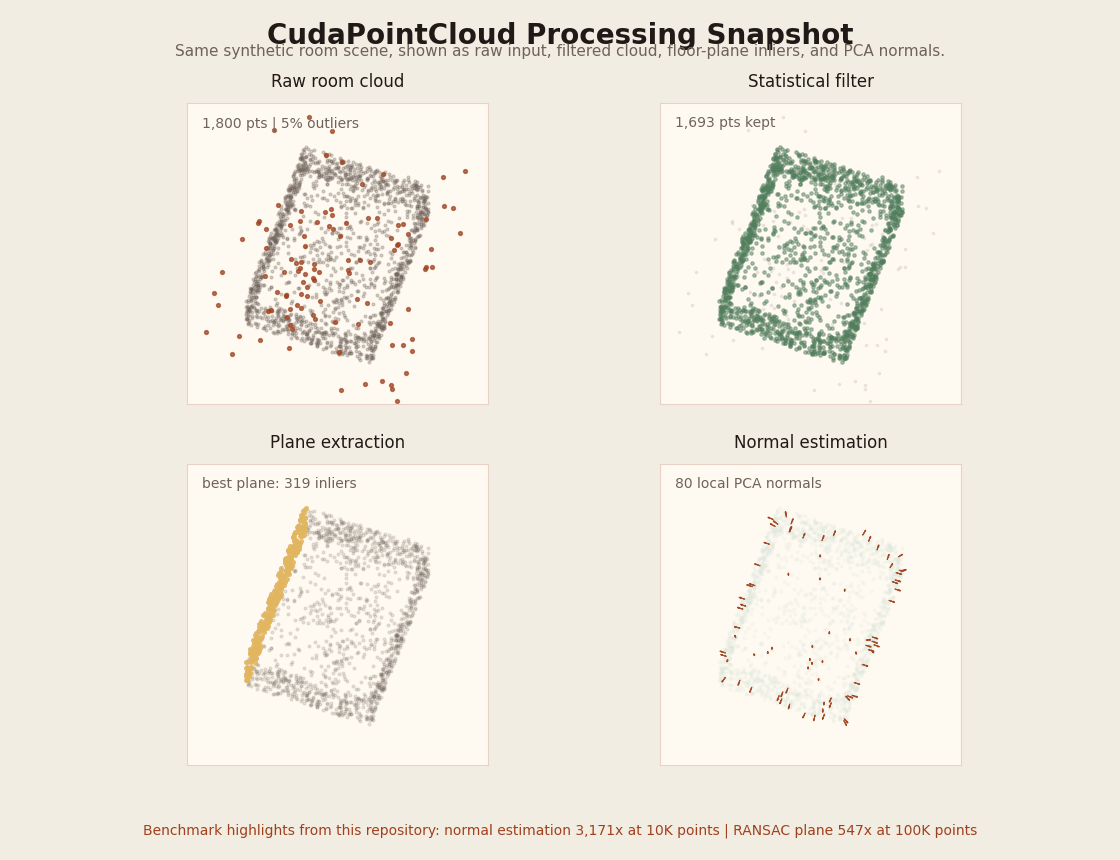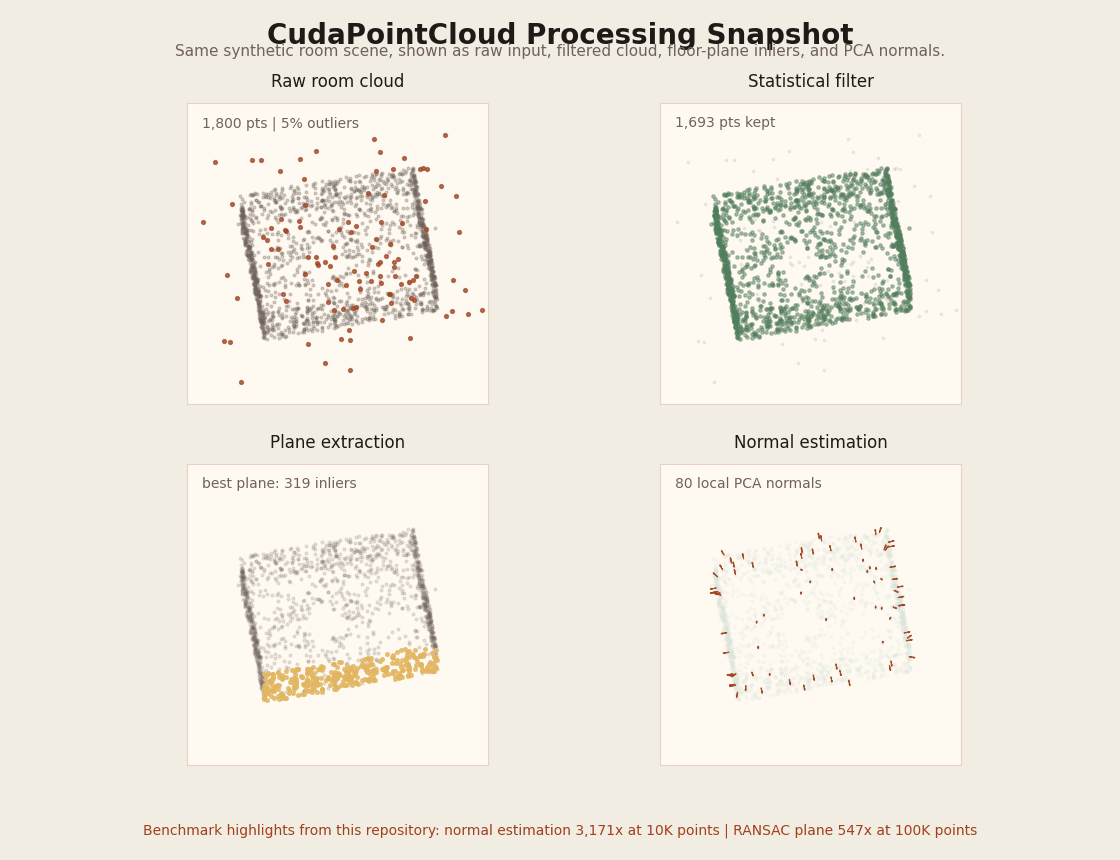
Rotating visual summary of the benchmark room cloud (raw / statistical-filtered / dominant plane / PCA normals). Regenerate with python3 scripts/render_pointcloud_processing_gif.py.
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| Neuroevolution | neuroevo |
One policy evaluation per individual, 4096 individuals in parallel |
| Neuroevolution Comparison | comparison_neuroevo |
CPU sequential evolution vs GPU population-scale evolution |
| PSO | pso_cuda |
100K particles updated in parallel |
| Differential Evolution | differential_evolution |
Population-wide mutation, crossover, and selection on GPU |
| CMA-ES | cma_es |
GPU candidate evaluation and covariance-guided search |
| ACO for TSP | aco_tsp |
Thousands of ants concurrently construct tours |
| Swarm Comparison | comparison_swarm |
Side-by-side convergence visualization for PSO, DE, and CMA-ES |
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| MiniIsaacGym CartPole | mini_isaac |
4096 environments stepped in parallel with GPU-side action generation |
| MiniIsaacGym REINFORCE | mini_isaac_rl |
GPU rollout buffer, return computation, policy-gradient construction, and MLP updates |
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| Occupancy Grid | occupancy_grid |
Ray-parallel lidar update (360 threads/scan) |
| Massive Lidar Simulator | comparison_lidar_sim |
2D DDA raycast, 1 ray = 1 thread; 1M rays/scan in ~0.25 ms (1500x per-ray throughput vs CPU) |
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| Multi-Robot Planner | multi_robot_planner |
N robots: force computation in parallel; scales to 500+ |
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| LQR Steering Control | (CPU only) | Sequential control loop |
| LQR Speed+Steering | (CPU only) | Sequential control loop |
| MPC | (CPU only) | Requires CppAD + IPOPT; uncomment lines in CMakeLists.txt to build |
100 steps (SIM_TIME=10s):
| Particles | CPU | CUDA | Speedup |
|---|---|---|---|
| 100 | 84 ms | 3.4 ms | 25x |
| 1,000 | 1,410 ms | 6.9 ms | 204x |
| 5,000 | 19,417 ms | 12.2 ms | 1,592x |
| 10,000 | 75,618 ms | 27.2 ms | 2,776x |
100 iterations per resolution:
| Samples | CPU | CUDA | Speedup |
|---|---|---|---|
| 9 | 1.1 ms | 1.3 ms | 0.9x |
| 405 | 54 ms | 1.4 ms | 40x |
| 1,449 | 197 ms | 1.4 ms | 140x |
| 8,421 | 1,205 ms | 1.7 ms | 705x |
Run bin/benchmark_pf to reproduce.
| Pattern | Used In |
|---|---|
| 1 sample = 1 thread (embarrassingly parallel) | PF, DWA, Frenet, State Lattice |
| Shared-memory reduction | PF (weight normalize/mean), DWA (min cost), Frenet (min cost) |
| GPU obstacle map / potential field | A*, Dijkstra, Potential Field |
| GPU nearest neighbor search | RRT, RRT*, PRM |
| Jump Flooding Algorithm (JFA) | Voronoi Road Map |
| Inline linear algebra (Cramer's rule) | Frenet (quintic/quartic solve) |
| cuRAND device-side RNG | PF |