How can we check if a username or email exists within a billion records?
Providing an optimal solution to a common use case for extremely large datasets i.e Twitter, Meta, Google, Amazon, etc
Normally, for smaller datasets, we would use a filter or a find on a dataset to find the specific user which filters each row in the dataset one by one. For smaller datasets, this is okay however, what happens if the dataset becomes huge? Say a billion records like that at Facebook or Amazon? Running a simple direct to DB SELECT * (USER --> DB) could cause a major bottleneck causing an unusable UI and leading to major performance issues.
There are a few approaches we can take:
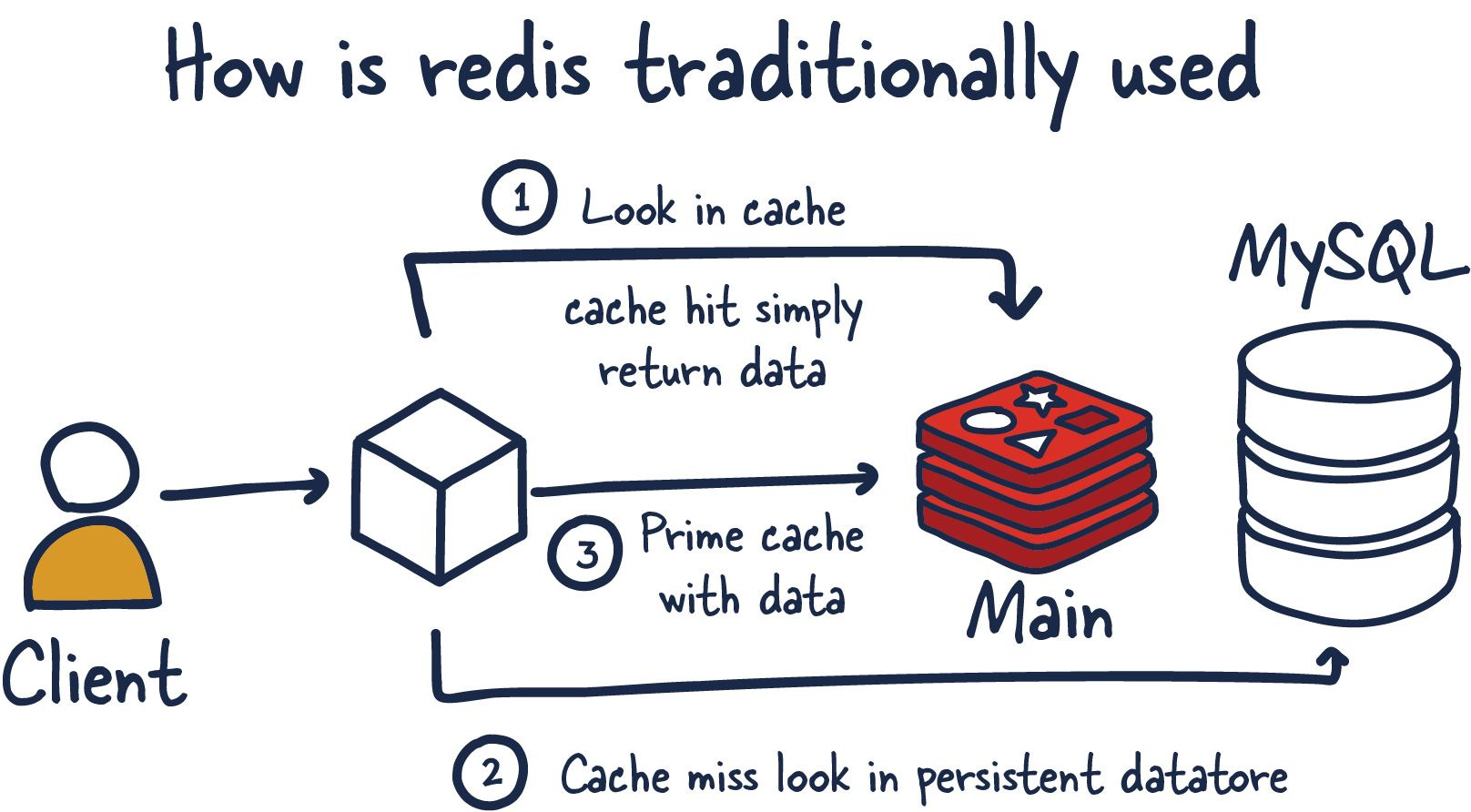
- Leverage caching use Redis or locally with a Concurrent Hashmap
- USER ----> CACHE ---> DB
- Here the user can mitigate the need to call a direct to DB query by instead referencing the CACHE for frequently
accessed data within a FAST, TEMPORARY storage layer.
- HOW DOES THIS HELP OUR SCENARIO? When a user creates an account, the server checks the cache to see if the username or email already exists. If the data is NOT found in the cache (called a CACHE MISS) then the system will query the database. The result is then stored into the cache for future requests.
- The cache has an expiration data as well so the data does not become stale.
- Link here for visual: https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F8533bf77-bf19-4feb-b744-c4c29bd38592_1616x892.jpeg
- WHAT ARE THE DRAWBACKS? :
- Cache misses still reference direct to DB queries which can also cause slowdowns.
- The cache can serve stale data
- Caching uses memory and if the cache is not managed properly (memory leaks, cache becomes too large) this can lead to excessive memory usage. In our scenario, say each username stores 10 bytes of memory, storing a billion usernames will require 10 GB of memory.
- Here the user can mitigate the need to call a direct to DB query by instead referencing the CACHE for frequently
accessed data within a FAST, TEMPORARY storage layer.
- USER ----> CACHE ---> DB
- Leverage Bloom Filters
- Bloom Filters are highly efficient and Probabilistic way to check if a username or email exists and are highly potent when speed and space are critical. Takes very little memory and membership checking takes 0(k) --> k is the number of hash functions
- Blooms filters use a BIT array of size m and is initialized to size 0 eg --> 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
- Afterward, an input like a username or email address is added to k number of positions within the bit array.
- m is chosen to balance memory usage and acceptable false positive rate
- m is determined based on the number of expected elements (n)
- k is chosen to minimize false positives while maintaining efficient performance
- k is determined based on the desired number of false positive probability (p)
- THE MATH:
- m is the size of the bit array
- k is the number of hash functions
- n is the number of elements expected to be inserted into the Bloom Filter
- ln(2) is the natural logarithm of 2, approximately 0.693
- --> m = -n * ln(p) / (ln(2))^2 || k = m /2 * ln(2)
- EXAMPLE:
- Platforms like Twitter MUST maintain a less than 1% false positive rate ( p = 0.001 or 1% )
- because the false positive rate is extremely low, the bit array must be several gigabytes ( m = 9.6 billion bits or ~1.2 gb )
- Twitter has about a billion users ( n = 1 billion )
- Optimal number of hash functions according to the formula ( k = 10 )
- THE PROCESS:
- example:
- INIT --> BF is initialized as m = 10 (bit array size) and k = 3 (number of hash functions). The username to be checked is "cat"
- START --> "cat" is hashed into three different (unique) hash functions
- the hash functions return positions 3, 5, and 7
- BF sets the positions 3, 5, 7 in the bit array to 1
- CHECK -->
- the same hash functions will produce 3, 5, and 7 again
- Since all these positions are 1, the filter will indicate that "cat" is probably in the set.
- VALIDATION -->
- if we check "dog", the hash funcitons returns positions 2, 5, and 9 and if the position 2 is 0, we can conclude that "dog" is definately not in the set
- TLDR -->
- element is passed through the k hash functions, generating k hash values
- corresponding k positions in the bit array are checked
- if all k positions are set to 1, the element is probably in the set
- if any position comes back as 0, the element is definitely not in the set
- example:
- WHAT ARE THE DRAWBACKS?
- FALSE POSITIVES --> There is a chance that the Bloom Filter can indicate that an element exists when it doesnt called a False Positive. This is caused by multiple elements can set the same bits in the array to 1. Therefore, its possible that when checking for an element, all k positions may be 1 event though the element is never added resulting in a False Positive. However, if any element returns a 0, then the element is GUARANTEED to not be in the set, so False Negatives can never occur.
- CANT REMOVE ELEMENTS --> Once an elements sets a bit to 1, the bits cannot be cleared without possibly affecting other elements. Bloom Filters do not support deletions. This means that if a user deletes their account, the bloom filter might still indicate that the username or email exists leading to a false positive.
{kind=link}
Combine both Redis caching with Bloom Filters to efficiently manage user accounts. How?
-
Pass the username into the bloom filter first to verify if the username is taken.
-
This will return whether the usename is taken or not, but there is a chance of a false positive. So at this point, pass the username into the redis cache to check the cache memory to verify it exists
-
On cache miss, then query the database and update the result into the cache for next query
-
--> FOR SMALL DATASETS == Direct Database Query
-
--> MID TO LARGE DATASETS == Caching (ie Redis)
-
--> EXTREMELY LARGE DATASETS == Bloom Filters