This project is forked from Eruption forecast model for Whakaari but has been significantly modified and extended for this specific application. Process raw seismic tremor data, extract time-series features, train machine learning models, and predict volcanic eruptions probability based on seismic patterns.
Dempsey, D. E., Cronin, S. J., Mei, S., & Kempa-Liehr, A. W. (2020). Automatic precursor recognition and real-time forecasting of sudden explosive volcanic eruptions at Whakaari, New Zealand. Nature Communications, 11(1), 1–8. https://doi.org/10.1038/s41467-020-17375-2 This model implements a time series feature engineering and classification workflow that issues eruption alerts based on real-time tremor data. https://github.com/ddempsey/whakaari
Ardid, A., Dempsey, D., Caudron, C., Cronin, S., Kennedy, B., Girona, T., Roman, D., Miller, C., Potter, S., Lamb, O. D., Martanto, A., Cubuk-Sabuncu, Y., Cabrera, L., Ruiz, S., Contreras, R., Pacheco, J., Mora, M. M., & De Angelis, S. (2025). Ergodic seismic precursors and transfer learning for short term eruption forecasting at data scarce volcanoes. Nature Communications , 16(1), 1–12. https://doi.org/10.1038/s41467-025-56689-x
Ardid, A., Dempsey, D., Caudron, C., & Cronin, S. (2022). Seismic precursors to the Whakaari 2019 phreatic eruption are transferable to other eruptions and volcanoes. Nature Communications, 13(1), 2002. https://doi.org/10.1038/s41467-022-29681-y
Endo, E. T., & Murray, T. L. (1991). Real-time Seismic Amplitude Measurement (RSAM): a volcano monitoring and prediction tool. Bulletin of Volcanology, 53, 533–545.
Caudron, C., et al., 2019, Change in seismic attenuation as a long-term precursor of gas-driven eruptions: Geology, https://doi.org/10.1130/G46107.1
Rey-Devesa, P., Prudencio, J., Benítez, C., Bretón, M., Plasencia, I., León, Z., Ortigosa, F., Gutiérrez, L., Arámbula-Mendoza, R., & Ibáñez, J. M. (2023). Tracking volcanic explosions using Shannon entropy at Volcán de Colima. Scientific Reports, 13(1), 1–11. https://doi.org/10.1038/s41598-023-36964-x
Christ, M., Braun, N., Neuffer, J., & Kempa-Liehr, A. W. (2018). Time Series FeatuRe Extraction on basis of Scalable Hypothesis tests (tsfresh – A Python package). Neurocomputing, 307, 72–77. https://doi.org/10.1016/j.neucom.2018.03.067
Lei, Y., & Wu, Z. (2020). Time series classification based on statistical features. Eurasip Journal on Wireless Communications and Networking, 2020(1). https://doi.org/10.1186/s13638-020-1661-4
Chardot, L., Jolly, A. D., Kennedy, B. M., Fournier, N., & Sherburn, S. (2015). Using volcanic tremor for eruption forecasting at White Island volcano (Whakaari), New Zealand. Journal of Volcanology and Geothermal Research, 302, 11–23. https://doi.org/10.1016/j.jvolgeores.2015.06.001
Time-series feature analysis and eruption forecasting for volcano data. Successor package to Whakaari. This model implements a time series feature engineering and classification workflow that issues eruption alerts based on real-time tremor data. https://github.com/ddempsey/puia
This software is intended for research purposes only.
-
Probabilistic Predictions: This eruption forecast model provides probabilistic predictions of future volcanic activity, NOT deterministic guarantees. Predictions should be interpreted as likelihood estimates based on historical seismic patterns.
-
No Guarantee of Accuracy: This model is not guaranteed to predict every future eruption. Volcanic systems are complex and can exhibit unexpected behavior. False negatives (missed eruptions) and false positives (false alarms) are possible.
-
Software Limitations: This software is not guaranteed to be free of bugs or errors. Users should validate results independently and use this tool as one component of a comprehensive volcano monitoring strategy.
-
Not for Operational Use: This package is a research tool and should not be used as the sole basis for public safety decisions, evacuation orders, or emergency response without expert volcanological assessment.
-
Expert Interpretation Required: Results should always be interpreted by qualified volcanologists familiar with the specific volcano being monitored.
Always consult with local volcano observatories and follow official warnings from government agencies.
- References and Acknowledgments
- Features
- Package Architecture
- Pipeline Overview
- Installation
- Data Sources
- Quick Start: Complete Pipeline
- Reports
- Advanced Usage
- Supported Classifiers
- Cross-Validation Strategies
- Threshold Optimization & Scoring
- Output Directory Structure
- Requirements
- Development
- Contributing
- License
Detailed documentation (wiki):
- Pipeline Walkthrough; Sections 1–12, per-stage code examples
- API Reference; Constructor and method parameter tables
- Visualization & Plotting; All plot types and usage
- Configuration; notify decorator, pipeline config save/replay, logging
- Output Directory Structure; Full directory tree
- Architecture; Component details, design principles, key classes
- Tremor Calculation: Process raw seismic data (SDS/FDSN) to calculate RSAM, DSAR, and Shannon Entropy metrics across multiple frequency bands
- Label Building: Generate training labels from eruption dates with configurable forecast horizons
- Feature Extraction: Extract 700+ time-series features using tsfresh for machine learning
- Enhanced Feature Selection: Three-method feature selection; tsfresh statistical, RandomForest permutation importance, or combined two-stage
- Model Training: Train 10 classifier types (Random Forest, Gradient Boosting, XGBoost, SVM, Logistic Regression, Neural Networks, Ensembles) across multiple random seeds
- Model Evaluation: Comprehensive evaluation with ROC curves, precision-recall curves, confusion matrices, threshold analysis, calibration curves, feature importance, SHAP explainability, seed stability violin plots, frequency band contribution charts, and learning curve plots (
plot_learning_curve_grid) viaModelEvaluatorandMultiModelEvaluator; cross-classifier comparison plots and ranking tables viaClassifierComparator - Two Training Workflows:
evaluate()for in-sample evaluation (80/20 split),train()for full-dataset training with future-data evaluation viaModelPredictor;fit()as a unified entry point that dispatches between the two - Seed Ensemble Merging: Combine all 500 seed models + their feature lists into a single
.pklfile viaBaseEnsemble.save()/SeedEnsemble/ClassifierEnsemble/merge_seed_models()/merge_all_classifiers(); eliminates per-seed I/O at prediction time and enablespredict_proba()directly on the ensemble - Multi-processing: Parallel processing for faster tremor calculations and model training
- Interactive HTML Reports: (beta, not fully functional yet) Generate self-contained Plotly-powered reports for every pipeline stage via
ForecastModel.generate_report()or the standalonegenerate_report()function; no external dependencies except an optionalweasyprintfor PDF export - Telegram Notifications:
notifydecorator andsend_telegram_notificationdirect function send structured Telegram messages (success/error, elapsed time, file attachments) - Modular Architecture: Clean separation of concerns with focused utility modules
eruption-forecast/
├── src/eruption_forecast/
│ ├── data_container.py # BaseDataContainer; shared ABC for TremorData & LabelData
│ ├── tremor/ # Seismic tremor processing
│ ├── label/ # Training label generation
│ ├── features/ # Feature extraction & selection
│ ├── model/ # ML model training & prediction
│ ├── sources/ # SDS and FDSN data source adapters
│ ├── plots/ # Visualization utilities
│ ├── report/ # (beta) Interactive HTML report generation
│ ├── utils/ # Focused utility modules
│ └── decorators/ # Function decorators
└── tests/ # Unit tests
Full directory tree, design principles, and per-component details: wiki/Architecture.md
Raw Seismic Data (SDS / FDSN)
│
▼
┌─────────────────────┐
│ CalculateTremor │ RSAM + DSAR + Entropy → tremor.csv
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ LabelBuilder │ Binary labels → label_*.csv
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ TremorMatrixBuilder │ Windowed matrix → tremor_matrix_*.csv
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ FeaturesBuilder │ 700+ features → all_features_*.csv
└──────────┬──────────┘
│
▼
┌─────────────────────────────────────────────┐
│ ModelTrainer │
│ ┌─────────────┐ ┌─────────────────────┐ │
│ │FeatureSelect│ │ ClassifierModel │ │
│ │ or │ │ (10 classifiers, │ │
│ │ combined │ │ 3 CV strategies) │ │
│ └─────────────┘ └─────────────────────┘ │
│ ↓ evaluate() ↓ train() │
│ 80/20 split + metrics Full dataset │
└─────────┬───────────────────────────────────┘
│ trained_model_*.csv + *.pkl
│
│ (optional) trainer.merge_models()
│ → merged_model_*.pkl (SeedEnsemble)
▼
┌─────────────────────────────────────────────┐
│ ModelPredictor │
│ ┌──────────────────────────────────────┐ │
│ │ predict_proba() │ │
│ │ (forecast mode; no labels needed) │ │
│ └──────────────────────────────────────┘ │
│ Single model or multi-model consensus │
└──────────────────────┬──────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ Report (beta, optional) │
│ generate_report() / fm.generate_report() │
│ → self-contained HTML (Plotly, CDN JS) │
│ Tremor · Labels · Features · Training │
│ Comparator · Prediction · Pipeline │
└─────────────────────────────────────────────┘
This project uses uv as the package manager.
# Clone the repository
git clone https://github.com/martanto/eruption-forecast.git
cd eruption-forecast
# Install dependencies
uv sync
# Install with dev dependencies
uv sync --group devThe package reads seismic data from two sources, both routed through CalculateTremor.
SDS is a standardized directory and file layout used by SeisComP to store waveform data portably across data servers and analysis tools. See the official SDS specification for full details.
Directory layout:
<sds_dir>/
└── YEAR/
└── NET/
└── STA/
└── CHAN.TYPE/
└── NET.STA.LOC.CHAN.TYPE.YEAR.DAY
Example for network VG, station OJN, channel EHZ, day 075 of 2025:
/data/
└── 2025/
└── VG/
└── OJN/
└── EHZ.D/
└── VG.OJN.00.EHZ.D.2025.075
Field reference:
| Field | Description | Example |
|---|---|---|
YEAR |
Four-digit year | 2025 |
NET |
Network code (≤ 8 chars) | VG |
STA |
Station code (≤ 8 chars) | OJN |
CHAN |
Channel code (≤ 8 chars) | EHZ |
LOC |
Location code (≤ 8 chars, may be empty) | 00 |
TYPE |
Data type; D = waveform data (most common) |
D |
DAY |
Three-digit day-of-year, zero-padded | 075 |
Files are miniSEED format. Periods in filenames are always present even when a field is empty.
Usage:
from eruption_forecast import CalculateTremor
tremor = CalculateTremor(
station="OJN",
channel="EHZ",
start_date="2025-01-01",
end_date="2025-01-31",
n_jobs=4,
).from_sds(sds_dir="/data/sds").run()FDSN downloads waveform data from any FDSN-compatible web service (IRIS, GEOFON, etc.) and caches it locally as SDS miniSEED so subsequent runs skip the network.
tremor = CalculateTremor(
station="OJN",
channel="EHZ",
start_date="2025-01-01",
end_date="2025-01-31",
).from_fdsn(client_url="https://service.iris.edu").run()Here's a complete end-to-end example from raw seismic data to trained models and eruption forecasting (adapted from main.py):
from eruption_forecast import ForecastModel
# Initialize the forecast model with station and configuration
fm = ForecastModel(
root_dir="output",
station="OJN",
channel="EHZ",
network="VG",
location="00",
window_size=2,
volcano_id="Lewotobi Laki-laki",
n_jobs=4,
verbose=True,
)
# Complete pipeline with method chaining
fm.calculate(
source="sds",
sds_dir="/path/to/sds/data",
methods=["rsam", "dsar", "entropy"],
plot_daily=True,
save_plot=True,
remove_outlier_method="maximum",
).build_label(
start_date="2025-01-01",
end_date="2025-07-24",
day_to_forecast=2,
window_step=6,
window_step_unit="hours",
eruption_dates=[
"2025-03-20",
"2025-04-22",
"2025-05-18",
"2025-06-17",
"2025-07-07",
],
).extract_features(
select_tremor_columns=["rsam_f2", "rsam_f3", "rsam_f4", "dsar_f3-f4", "entropy"],
save_tremor_matrix_per_method=True,
exclude_features=["agg_linear_trend", "linear_trend_timewise", "length"],
use_relevant_features=True,
).train(
classifier="rf",
cv_strategy="stratified",
random_state=0,
total_seed=500,
with_evaluation=False,
number_of_significant_features=20,
sampling_strategy=0.75,
save_all_features=True,
plot_significant_features=True,
).forecast(
start_date="2025-07-28",
end_date="2025-08-04",
window_step=10,
window_step_unit="minutes",
)What this pipeline does:
- Calculate tremor (RSAM, DSAR, Shannon Entropy) from raw seismic data with outlier removal
- Build labels from known eruption dates (training period: Jan 1 – Jul 24)
- Extract features using tsfresh (700+ features) and select top 20
- Train models using Random Forest with 500 random seeds for robust predictions
- Forecast future eruptions (Jul 28 – Aug 4) using the trained ensemble
See main.py in the repository for the complete working example.
Full per-stage guide with code examples: wiki/Pipeline-Walkthrough.md
The report/ package generates self-contained, interactive HTML reports (powered by Plotly, loaded from CDN) for every pipeline stage. No image files are produced; each report is a single .html file you can open in any browser or share by email.
fm.calculate(...).build_label(...).train(...).generate_report()
# → output/VG.OJN.00.EHZ/reports/pipeline_report.html
# Select specific sections only
fm.generate_report(sections=["tremor", "label"])
# Export to PDF (requires: uv add weasyprint)
fm.generate_report(fmt="pdf")from eruption_forecast.report import generate_report
path = generate_report("output/VG.OJN.00.EHZ")
print(f"Report saved to {path}")
# Specific sections
path = generate_report("output/VG.OJN.00.EHZ", sections=["tremor", "training"])Each report class can be used directly for a focused view:
from eruption_forecast.report import (
TremorReport,
LabelReport,
FeaturesReport,
TrainingReport,
ComparatorReport,
PredictionReport,
PipelineReport,
)
# Tremor: data completeness, band stats, full-range + daily detail chart
path = TremorReport("output/.../tremor.csv", station="OJN").save()
# Labels: window config, class distribution, eruption timeline
path = LabelReport(
"output/.../label_2025-01-01_....csv",
eruption_dates=["2025-03-20", "2025-04-22"],
).save()
# Features: feature counts, top-N bar, band contribution
path = FeaturesReport(
features_csv="output/.../all_extracted_features.csv",
significant_features_dir="output/.../significant_features/",
selection_method="combined",
).save()
# Training: per-seed <details>, aggregate mean±std, stability, threshold analysis
path = TrainingReport(
metrics_dir="output/.../metrics/",
classifier_name="RandomForestClassifier",
).save()
# Classifier comparison: grouped bar + aggregate table
from eruption_forecast.report import ComparatorReport
path = ComparatorReport(
classifier_registry={
"rf": "output/.../trainings/evaluations/rf/.../trained_model_rf.csv",
"xgb": "output/.../trainings/evaluations/xgb/.../trained_model_xgb.csv",
}
).save()
# Forecast probabilities: consensus line, uncertainty band, eruption markers
path = PredictionReport(
prediction_df=fm.prediction_df,
eruption_dates=["2025-03-20"],
threshold=0.7,
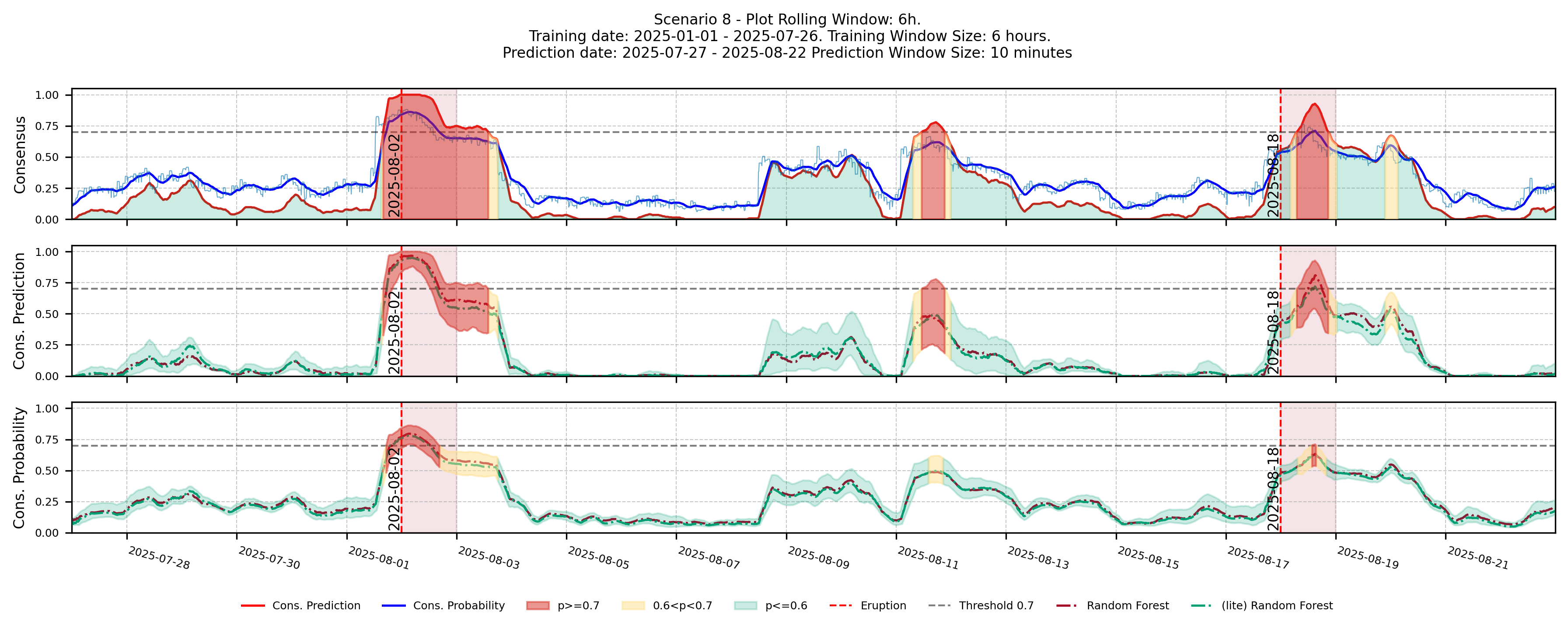
).save()What each report contains:
| Report | Charts | Tables |
|---|---|---|
TremorReport |
Full-range overview, daily detail with date dropdown | Completeness, band stats |
LabelReport |
Class distribution bar, eruption timeline | Window config, class counts |
FeaturesReport |
Top-N features (horizontal bar), band contribution | Feature counts summary |
TrainingReport |
Seed stability, threshold analysis | Per-seed rows + aggregate mean±std |
ComparatorReport |
Grouped bar per metric × classifier | Aggregate metrics table |
PredictionReport |
Probability lines + uncertainty band + eruption markers | Forecast config |
PipelineReport |
All of the above + executive summary | Pipeline stage availability |
fm.calculate(
source="fdsn",
client_url="https://service.iris.edu",
).build_label(...).train(...)
# Downloaded miniSEED files are cached locally so subsequent runs skip the network.fm.load_tremor_data(
tremor_csv="output/VG.OJN.00.EHZ/tremor/tremor_2025-01-01_2025-12-31.csv"
).build_label(...).extract_features(...).train(...).forecast(...)fm.set_feature_selection_method("combined").train(
classifier="rf",
cv_strategy="timeseries",
total_seed=200,
)fm.train(
classifier="xgb",
with_evaluation=True,
total_seed=100,
)XGBoost (xgb) and the voting ensemble (voting) support GPU training via use_gpu=True. Use gpu_id to select a specific device on multi-GPU machines.
# Train on the first GPU (default)
fm.train(
classifier="xgb",
cv_strategy="stratified",
total_seed=500,
use_gpu=True, # enable CUDA
gpu_id=0, # first GPU (default)
)
# Train on the second GPU
fm.train(
classifier="xgb",
use_gpu=True,
gpu_id=1, # second GPU
)Parallelism architecture:
ModelTrainer.fit()
│
├── [outer] n_jobs → Parallel(loky backend)
│ Each worker runs one full seed independently:
│ resample → feature selection → GridSearchCV → evaluate → save
│ GPU: forced to 1 (seeds share one GPU device)
│
└── [inner, per seed] grid_search_n_jobs
│
├── FeatureSelector → tsfresh/RandomForest, CPU-only
│ GPU: unchanged; safe to parallelise
│
└── GridSearchCV → runs XGBoost CV folds
GPU: forced to 1 (fold workers share one GPU device)
Parallelism rules when use_gpu=True:
| Parameter | Normal (CPU) | GPU (use_gpu=True) |
|---|---|---|
n_jobs (outer seed workers) |
Configurable | Forced to 1; multiple seeds sharing one GPU causes VRAM contention |
grid_search_n_jobs in GridSearchCV |
Configurable | Forced to 1; parallel CV fold workers each try to use the GPU simultaneously |
grid_search_n_jobs in FeatureSelector |
Configurable | Unchanged; feature selection is CPU-only (tsfresh/RandomForest) and is safe to parallelise |
use_gpu=Truehas no effect on non-XGBoost classifiers (rf,gb,svm, etc.). Passing it with those classifiers emits a warning and training proceeds on CPU as normal.
Pass a list[str] or comma-separated string to classifier. Each classifier is trained sequentially; all trained model registries are available for multi-model consensus forecasting.
fm.train(
classifier=["rf", "xgb", "gb"],
cv_strategy="stratified",
total_seed=500,
with_evaluation=False,
).forecast(
start_date="2025-07-28",
end_date="2025-08-04",
window_step=10,
window_step_unit="minutes",
)After training several classifiers with evaluate(), use ClassifierComparator
to rank them and produce comparison plots:
from eruption_forecast.model import ClassifierComparator
# From a dict
comparator = ClassifierComparator(
classifiers={
"rf": "output/.../trainings/evaluations/rf/stratified/trained_model_rf_...csv",
"xgb": "output/.../trainings/evaluations/xgb/stratified/trained_model_xgb_...csv",
"gb": "output/.../trainings/evaluations/gb/stratified/trained_model_gb_...csv",
},
metrics=["f1_score", "roc_auc", "recall"], # or None for all DEFAULT_METRICS
)
# Or from a JSON file {"ClassifierName": "/path/to/trained_model_*.csv", ...}
comparator = ClassifierComparator.from_json(
"output/VG.OJN.00.EHZ/evaluations_trained_models.json",
metrics=["f1_score", "roc_auc", "recall"],
)
# Ranked by recall (default), saved to metrics/ranking_recall.csv
ranking = comparator.get_ranking()
# All plots; saved to figures/
results = comparator.plot_all()
# results["metric_bar"] → dict[str, Figure] (one per metric + "all" overview)
# results["seed_stability"] → dict[str, Figure] (one per metric + "all" overview)
# results["comparison_grid"] → Figure
# results["roc"] → Figure
# results["ranking"] → DataFrameAfter training, collapse all seed models into a single .pkl to remove per-seed I/O overhead:
from eruption_forecast.model.seed_ensemble import SeedEnsemble
from eruption_forecast.utils.ml import merge_seed_models, merge_all_classifiers
# Single classifier
merged_path = trainer.merge_models()
# → .../merged_model_RandomForestClassifier-StratifiedKFold_rs-0_ts-500_top-20.pkl
# Load and predict directly
ensemble = SeedEnsemble.load(merged_path)
mean_p, std, conf, pred = ensemble.predict_with_uncertainty(features_df)
# sklearn-compatible interface
proba = ensemble.predict_proba(features_df) # shape (n_samples, 2)
# Multi-classifier bundle
bundle_path = trainer.merge_classifier_models({"rf": rf_csv, "xgb": xgb_csv})
# Pass merged pkl directly to ModelPredictor
predictor = ModelPredictor(
start_date="2025-07-28", end_date="2025-08-04",
trained_models=merged_path, # single merged pkl
# or: trained_models=bundle_path (multi-classifier bundle)
)Silence all console and file output; useful for batch jobs or when embedding the package:
from eruption_forecast import disable_logging, enable_logging
disable_logging()
fm.calculate(...).build_label(...).train(...) # Silent; no output
enable_logging() # Restore output
# Fine-grained control
from eruption_forecast.logger import set_log_level, set_log_directory
set_log_level("WARNING") # Only warnings and errors to console
set_log_directory("output/logs") # Write log files to a custom directoryfm.save_config() # YAML → {station_dir}/config.yaml
fm.save_model() # joblib → {station_dir}/forecast_model.pkl
# Replay the full pipeline from a saved config
fm2 = ForecastModel.from_config("output/VG.OJN.00.EHZ/config.yaml")
fm2.run()
# Resume from a saved model (skip re-training)
fm3 = ForecastModel.load_model("output/VG.OJN.00.EHZ/forecast_model.pkl")
fm3.forecast(start_date="2025-04-01", end_date="2025-04-07",
window_step=12, window_step_unit="hours")Full configuration reference: wiki/Configuration.md
| Classifier | Description | Imbalance Handling |
|---|---|---|
rf |
Random Forest (balanced, robust, default) | class_weight="balanced" |
gb |
Gradient Boosting (handles imbalance natively) | None (natural) |
xgb |
XGBoost (excellent for imbalanced data, GPU-capable) | scale_pos_weight grid search |
svm |
Support Vector Machine (high-dimensional) | class_weight="balanced" |
lr |
Logistic Regression (interpretable, fast) | class_weight="balanced" |
nn |
Neural Network MLP (complex patterns) | None |
dt |
Decision Tree (interpretable baseline) | class_weight="balanced" |
knn |
K-Nearest Neighbors (simple baseline) | None |
nb |
Gaussian Naive Bayes (fast baseline) | None |
voting |
Soft VotingClassifier (RF + XGBoost ensemble, GPU-capable) | Combined |
lite-rf |
Random Forest with a smaller grid for faster training | class_weight="balanced" |
Hyperparameter grids and overriding them: wiki/Training-Workflows.md
| Strategy | Class | Best For |
|---|---|---|
shuffle |
StratifiedShuffleSplit |
Random splits with stratification (default) |
stratified |
StratifiedKFold |
Preserves class distribution across folds |
timeseries |
TimeSeriesSplit |
Temporal data, strict no-future-leakage |
Volcanic eruption datasets are severely imbalanced; eruptions are rare events that may represent less than 5-10% of all windows. Choosing the right optimization criterion for the decision threshold is therefore critical.
| Criterion | Formula | Penalizes Missed Eruptions | Penalizes False Alarms | Robust to Imbalance |
|---|---|---|---|---|
| Accuracy | (TP + TN) / N | No; dominated by majority class | No | No |
| F1 Score | 2·P·R / (P + R) | Partially | Partially | No |
| Recall | TP / (TP + FN) | Yes | No; can hit 1.0 by predicting all positive | No |
| Precision | TP / (TP + FP) | No | Yes | No |
| Balanced Accuracy | (Sensitivity + Specificity) / 2 | Partially | Partially | Yes |
| G-mean | √(Sensitivity × Specificity) | Yes | Yes | Yes |
All outputs are organized under {output_dir}/{network}.{station}.{location}.{channel}/
(e.g., output/VG.OJN.00.EHZ/).
output/
└── VG.OJN.00.EHZ/
├── tremor/
│ ├── tremor_*.csv # Merged tremor data
│ └── matrix/ # Tremor matrix outputs (TremorMatrixBuilder)
│ ├── tremor_matrix_unified_*.csv
│ └── per_method/ # Per-column matrices with date-stamped filenames
├── features/
│ ├── extracted/
│ │ ├── train/ # Per-column tsfresh CSVs (training mode)
│ │ └── forecast/ # Per-column tsfresh CSVs (prediction mode)
│ ├── all_features_*.csv # Concatenated features
│ └── label-features_*.csv # Labels aligned with features
└── trainings/
├── evaluations/
│ ├── features/ # Shared feature selection outputs
│ └── classifiers/ # Per-classifier model outputs (evaluations)
└── predictions/
├── features/ # Shared feature selection outputs
└── classifiers/ # Per-classifier model outputs (predictions)
Full directory tree with all sub-paths: wiki/Output-Structure.md
- Python >= 3.11
- pandas >= 3.0.0
- numpy
- scipy
- obspy (seismic data processing)
- tsfresh (time-series feature extraction)
- scikit-learn
- imbalanced-learn
- xgboost
- joblib
- matplotlib
- seaborn
- loguru
- python-dotenv (Telegram notification credential loading)
- ruff (linting)
- ty (type checking)
- pytest (testing)
# Lint and auto-fix
uv run ruff check --fix src/
# Type checking
uvx ty check src/# Run all tests
pytest tests/
# Run with coverage
pytest --cov=src/eruption_forecast tests/
# Run specific test
pytest tests/test_train_model.py- Fork the repository
- Create a feature branch (
git checkout -b feature/my-feature) - Make changes with tests
- Ensure code passes linting and type checks (
uv run ruff check --fix src/) - Update documentation
- Submit a pull request
Commit convention: Use fix/ for bug fixes, ft/ for new features, dev/ as default.
Code style: PEP 8, Google-style docstrings with explicit types, type hints on all functions.
MIT License; see LICENSE file for details.
Disclaimer of Liability: This software is provided "as is" without warranty of any kind, express or implied. The authors and contributors shall not be liable for any damages or losses arising from the use of this software. Volcanic eruption forecasting is inherently uncertain, and this software should be used only as a research tool, not for operational volcano monitoring or public safety decisions.
Version: 0.1.0 Status: Active Development Last Updated: 2026-04-26 (docs/ removed; all links now point to wiki/)