Zaharadniuk_Aliaksei_fiz.zagorodnAA@gmail.com#2
Conversation
| import sys | ||
|
|
||
|
|
||
| def get_parse(args_in=''): |
There was a problem hiding this comment.
Here and below:
It's a good practice to add type hits in your function signatures (e.g. def get_parse(args_in='': str) -> Dict[str, Any]:
Please, take a loot at typing lib
There was a problem hiding this comment.
All lines were found and fixed where appropriate. Will be updated during the next "push" iteration.
| logs.log_err_exit() | ||
| parser.exit() | ||
|
|
||
| return {'url': args.url, 'json': args.json, 'verbose': args.verbose, 'limit': args.limit} |
There was a problem hiding this comment.
Please, take a look at dataclasses lib. It might be better to replace this dict with dataclass object.
There was a problem hiding this comment.
Since it may touch the fundamental logic of the program, I'll try to implement dataclasses when I have a working program with at least first four complete iterations.
| """This function receives the answer from server""" | ||
|
|
||
| news = feedparser.parse(url) | ||
| if news.entries: |
There was a problem hiding this comment.
return news if news.entries else None
There was a problem hiding this comment.
The line was found and fixed. It will be updated during the next "push" iteration.
|
|
||
| for i in range(3): | ||
| try: | ||
| a = urllib.request.urlopen(url).getcode() |
There was a problem hiding this comment.
Please, do not use single-charachter variables names.
There was a problem hiding this comment.
I have checked all one letter variables in the program and fixed it. It will be updated during the next "push" iteration.
| In case of failure, it reconnects in 10 seconds | ||
| """ | ||
|
|
||
| for i in range(3): |
There was a problem hiding this comment.
This logic will retry to get a response from server if status code is other than 200. But it's is useless to retry for example 400, 500 HTTP errors, invalid urls and some. You can think about more optimal solution. urllib has it's own Retry included.
There was a problem hiding this comment.
The function was fixed. It will be updated during the next "push" iteration.
Please make sure that project structure is the same as specified in our README.md. This is important for CI checks that will be added in future. Note that we only require that application entry point shold be in
Your documentation looks great, but you were supposed to use separate file
While we allow using 3rd party libraries in your final project, it is realy bad practice to copy its code directly, even if you changed it a little. Usually you want to use it through imports. Or if you need to change its functionality a little, you should implement your own class that inherits the one in the library and reimplement required behavior there. Please fix these issues, especially the last one, |
|
Новая версия программы. Включает вторую и третью итерацию. Структура программы была изменена, чтобы полностью соответствовать требованиям, внесены изменения в код программы. Исправлено большинство замечаний. Полностью переделаны некоторые функции. Добавлена опция записи новостей в локальное хранилище, извлечение новостей из локального хранилища для последующей печати в консоль. Переписан setup.py файл, удалены библиотеки feedparser, html2text. Программа при установке автоматически скачивает новые и необходимые библиотеки для корректной работы. Работоспособность была проверена на Windows 10 (1903) и на Linux Fedora 30 с python версии 3.8 |
|
|
Версия 3.1 (первые три итерации). Исправлена ошибка ModuleNotFoundError добавлением пути поиска файлов в переменные среды. Исправлены все замечания с import, изменена структура программы. В файл README.MD добавлена глава запуска приложения с примерами команд. Описан запуск "сырого" не установленного пакета из каталога rss_reader, сборка пакета для установки, установка пакета, запуск пакета при его установке. |
|
Here is feedback on your application work:
3rd Iteration is not that trivial as it looks, specifically because of that we are asking you to describe your method of storing cached news. |
| except SystemExit: | ||
| logs.log_err_init_args(args_in) | ||
| logs.log_err_exit() | ||
| parser.exit() |
There was a problem hiding this comment.
Here and below: It is better to have only one exit point in the program. For example you can raise your custom exception here and handle it in the main function.
There was a problem hiding this comment.
It was fixed for major cycles. The rest will be fixed after fourth iteration.
| flag = True | ||
| except FileNotFoundError: | ||
| print('Error: File not found. (Maybe this is a first time you are running a program)') | ||
| return 1 |
There was a problem hiding this comment.
Here and below: while sometimes it is common practice to return your custom 'statuses' it reassly dampens code readability. It is better to raise/reraise an exception here and handle it in the main thread. If everythoong went good just return True.
There was a problem hiding this comment.
It will be fixed after the fourth iteration.
|
Версия программы 3.5 Исправлены основные замечания по флагам limit, date, verbose, а так же их комбинации. Была дополнена третья итерация: прежде чем записать новость, программа проверяет наличие дубликата внутри журнала. Была сделана четвертая итерация: добавлено конвертирование в формат pdf согласно недавним рекомендациям в slack. Использование конвертации подробно описано в README.md |
| # Everything deals with time delay will be repeated | ||
| except urllib.error.HTTPError as http_err: | ||
| if http_err.code in (503, 504, 522, 524): | ||
| print('') |
There was a problem hiding this comment.
Here, above and below: It is better to think of some other way to make an empty line instead of printing ''
There was a problem hiding this comment.
It will be fixed during final commit.
|
Here is some feedback on your application:
|
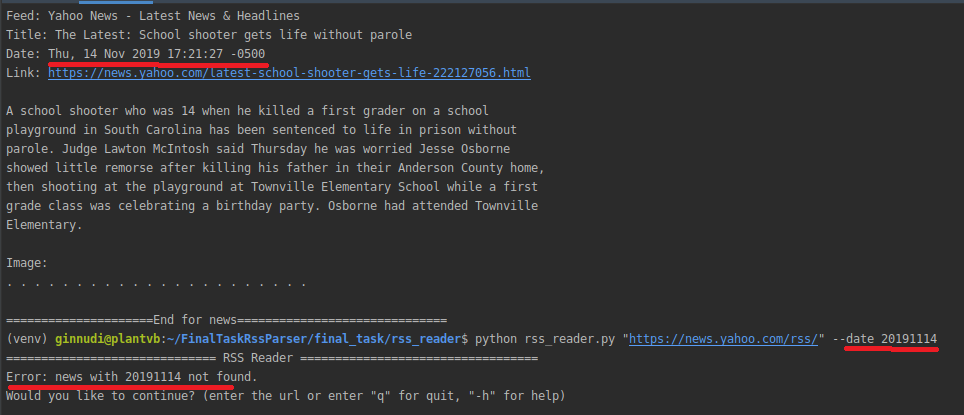
|
Четвертая итерация, добавлено конвертирование в формат html. Улучшено конвертирование в формат pdf. Исправлена ошибка с отображением даты, улучшен вывод логов (теперь логи печатаются с новостями). Улучшен процесс конвертации новостей из локального хранилища (теперь для конвертации не нужен Интернет). Исправлена ошибка с шрифтами при конвертировании новостей. Улучшен ввод аргументов (теперь для использования программы не обязательно вводить url для позиционного аргумента). Исправлен ряд замечаний относительно кода. |
You can squash these commits |
|
Here is some feedback on your app work:
Same for
|

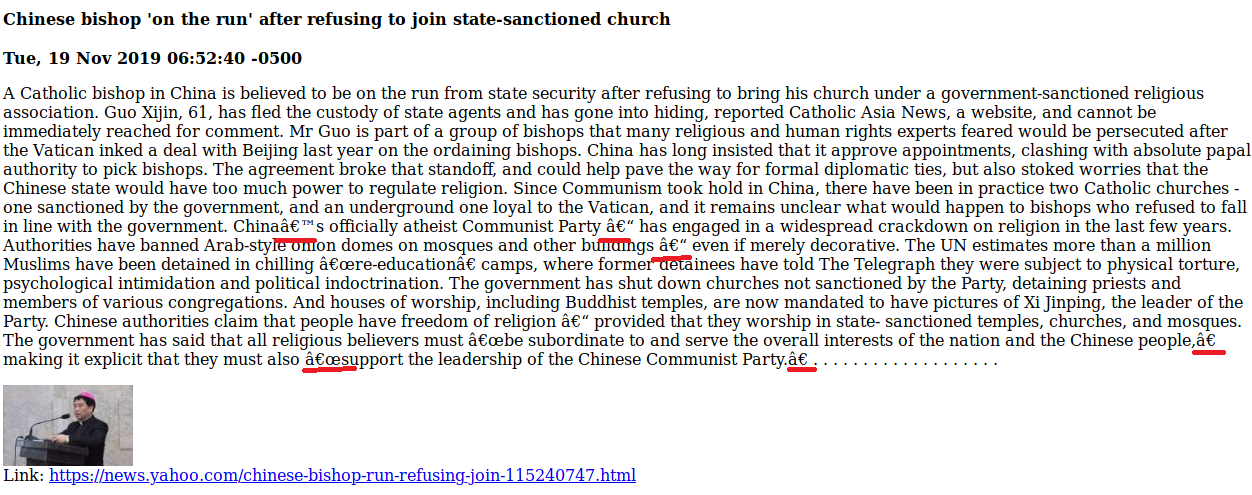
| return {'url': args.url, | ||
| 'json': args.json, | ||
| 'verbose': args.verbose, | ||
| 'limit': args.limit, | ||
| 'date': args.date, | ||
| 'pdf': args.pdf, | ||
| 'html': args.html} |
There was a problem hiding this comment.
A question:
You already have all arguments inside args object. Do you really need to make this dict here? Why not just pass args everywhere instead?
There was a problem hiding this comment.
I use this data in the code in rss_reader.py module. It is more convenient for me to use it in this form. In my opinion it make my code easy to read.
| pdf = FPDF() | ||
| pdf.set_font('Arial', 'B', size=14) | ||
| pdf.set_margins(10, 10, 10) | ||
| pdf.add_page(('P', 'A4')) |
There was a problem hiding this comment.
You had the same chunk of code above, it is better to move it to a separate function
There was a problem hiding this comment.
The code above is not the same as above. The main difference is the font: arial_uni for the first case, Arial for the second case.
| url = line[73:] | ||
| info = line[0:66] |
There was a problem hiding this comment.
These numbers are confusingly specific, please leave a comment here why exactly it is 73 and 66
There was a problem hiding this comment.
The function deals with logs, that has specific template: first 66 characters for technical information data, the rest for url. It is convenient for me to slice it this way.
| def log_log_html(): | ||
| """This function logs the conversion of log journal to html""" | ||
|
|
||
| logging.info('Log journal was converted to html') |
There was a problem hiding this comment.
Consider using logging decorator instead of this module.
| def convert_date(date: str): | ||
| """This function converts date""" | ||
| month = {'Jan': '1', | ||
| 'Feb': '2', | ||
| 'Mar': '3', | ||
| 'Apr': '4', | ||
| 'May': '5', | ||
| 'Jun': '6', | ||
| 'Jul': '7', | ||
| 'Aug': '8', | ||
| 'Sep': '9', | ||
| 'Oct': '10', | ||
| 'Nov': '11', | ||
| 'Dec': '12'} | ||
| day = date[5:7] | ||
| month_num = month[date[8:11]] | ||
| year = date[12:16] |
There was a problem hiding this comment.
same: datetime lib
There was a problem hiding this comment.
Since the data from argsparse is a string, it is more convenient to use separate function instead of datetime.
There was a problem hiding this comment.
This function is still redundant. It is better to use existing optimized solution that works in any situation instead of implementing new one
| logs.new_session() | ||
| commands = args_parser.get_parse() | ||
|
|
||
| while True: |
There was a problem hiding this comment.
It is better to just remove user input above and get rid of this while completely. This is not how app is supposed to work
There was a problem hiding this comment.
The structure of the program was fixed, there is no more while cycle. It will be updated during the next commit.
|
|
||
|
|
||
| if __name__ == '__main__': | ||
| main() |
There was a problem hiding this comment.
main function is too large. It is better to split it into a smaller functions
|
Финальная версия программы RSS Reader (четыре итерации) - исправлены основные замечания, изменена логика программы, дополнен функционал. |
| data['link'] = rss.entries[limit].link | ||
| data['title'] = rss.entries[limit].title | ||
|
|
||
| """news_date for third iteration, yyyy-mm-dd""" |
There was a problem hiding this comment.
Comments are usually written using #
| if data['image'] is not None: | ||
| print('Image: ' + data['image']) | ||
| print('. . . . . . . . . . . . . . . . . . . . . .') | ||
| print('') |
There was a problem hiding this comment.
It is better to think of some other way for printing an empty line instead of using print("")
|
Here is feedback on your application: The code is readable, decently structured, mostly corresponds to the PEP8 guidelines. |
Первая версия программы RssReader. Так как создание программы (и ее логическая архитектура) делалась на протяжении предыдущей недели, то окончательный вид (расположение папок, название файлов) не совпадает с тем, что было указано в требованиях README.md. В файле README.txt и README.md имеется полное описание работы программы, указания для установки пакета программы (итерация 2, папка /dist, zip архив), и приведена структура программы. Модуль с unit-тестами будет добавлен позже (планирую его добавить после третьей итерации). В программе используются две сторонние библиотеки: feedparser.py и html2text (пакет из нескольких модулей). Данные библиотеки уже настроены для использования с программой, поэтому рекомендуется использовать именно их, а не аналогичные но скачанные из других репозиториев.