Kirill_Ulich_k.ulitch@yandex.ru#19
Conversation
|
Here is some feedback on your application work:
|
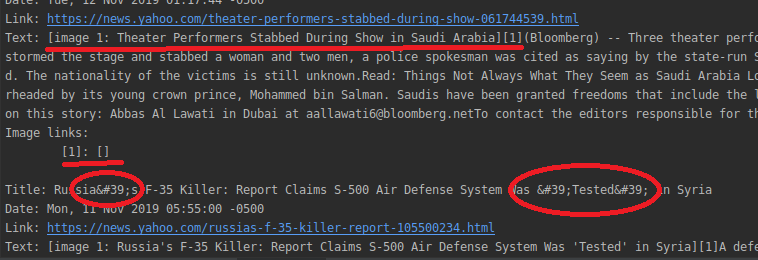
| from parser_rss import format_description | ||
|
|
||
|
|
||
| @dataclass() |
There was a problem hiding this comment.
You dont need brakets here, since you dont pass any arguments into this decorator
| if not isinstance(item, Item): | ||
| raise TypeError(f'Object with type {type(item)} is not serializable. Expected type: {Item}') | ||
|
|
||
| return {'title': item.title, |
There was a problem hiding this comment.
dataclasses lib has function as_dict which you can use to cast your dataclass object into a dictionary
…lems with images without links. --version works now without rss source.
|
Iteration 2 completed |
|
|
||
| logging.info('Loop for creating items.') | ||
| for item in parser.entries: | ||
| text_, img_links_ = format_description(item.description) |
There was a problem hiding this comment.
Why do you need underscores after text and img_links?
| :rtype: str | ||
| """ | ||
| logging.info('Converting items to dicts.') | ||
| map_of_dict_items = map(lambda item: asdict(item), items_) |
There was a problem hiding this comment.
You can replace this with simple list comprehension, e.g. [asdict(item) for item in items_]
| return parser | ||
|
|
||
|
|
||
| class GettingRSSException(Exception): |
There was a problem hiding this comment.
It's better to create separate module exceptions.py, where you store your custom exception objects.
|
Also for Iteration 2 it would be great if you could add step-by-step guide on how to run your application an a clean machine using setup tools |
…EADME.md updated. Iteration 3 completed.
|
Iteration 3 completed. |
|
User should be able to specify RSS feed url without using |
|
Iteration 4 completed |
Please make sure that lib you are using for conversion does not require any additional packages on Linux OS. |
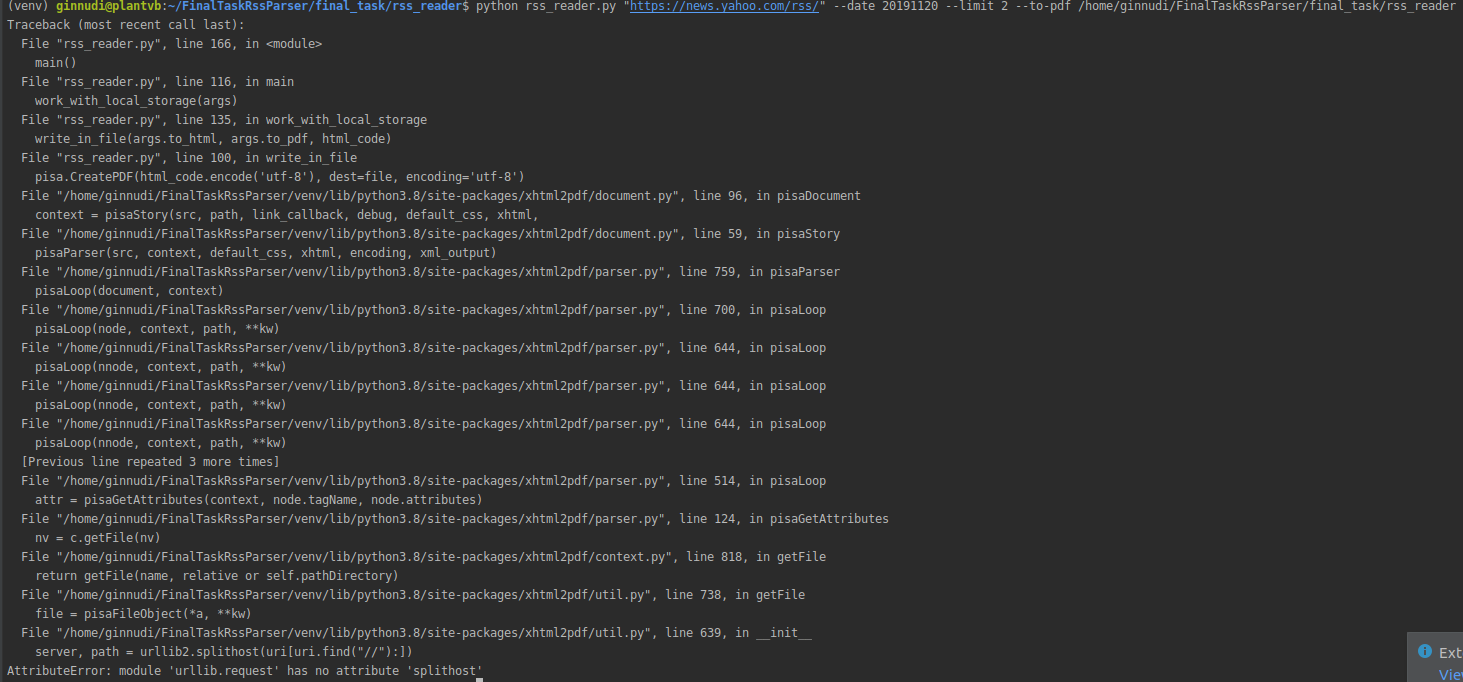
|
From git repository of xhtml2pdf: "All additional requirements are listed in requirements.txt file and are installed automatically using the pip install xhtml2pdf method." On Windows application works correctly. I not sure, but maybe neccessery version 0.2.1 of xhtml2pdf. But I cannot check it, because I do not have Linux. |
| text, img_links = format_description(item.description) | ||
|
|
||
| if not text: | ||
| continue |
There was a problem hiding this comment.
It's better to try to avoid using continue. In this particular case it looks fine, but in more complex logic you may want to do something like:
if text: new_item = Item( ...
And you will not need to use continue
|
Unfortunately pdf conversion still does not work for me together with |
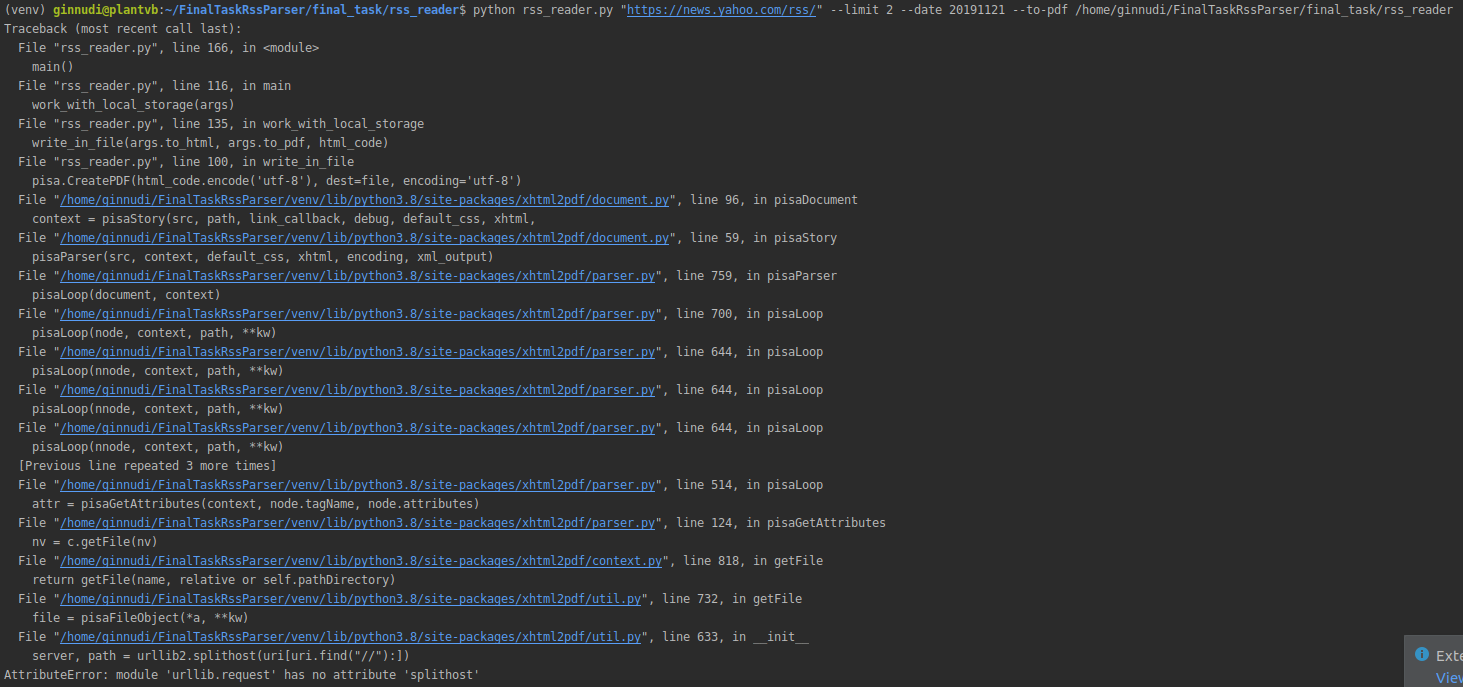
|
I did not discover any issues with iteration 5. But pdf conversion still does not work: you forgot to push your font file. |
|
I did not discover any issues with Iteration 4 work, but please be sure to test it thoroughly in case I missed something |
|
Here is feedback on your application work: Iteration 1: Tests are ok, coverage is high enough. The code is readable, decently structured, absolutely corresponds to the PEP8 guidelines. Commit messages are informative, but do not correspond to the recommended commit message style. |
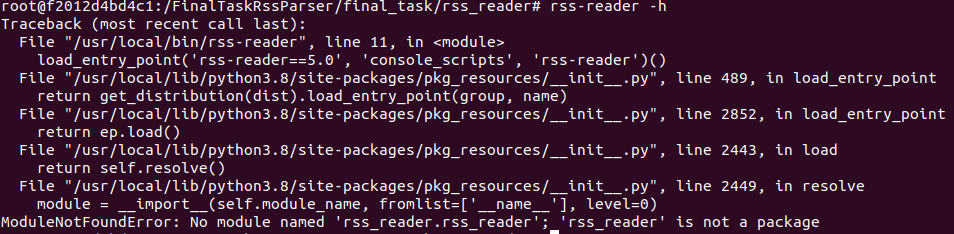
Iteration 1 completed