8-week curriculum for AI Builders
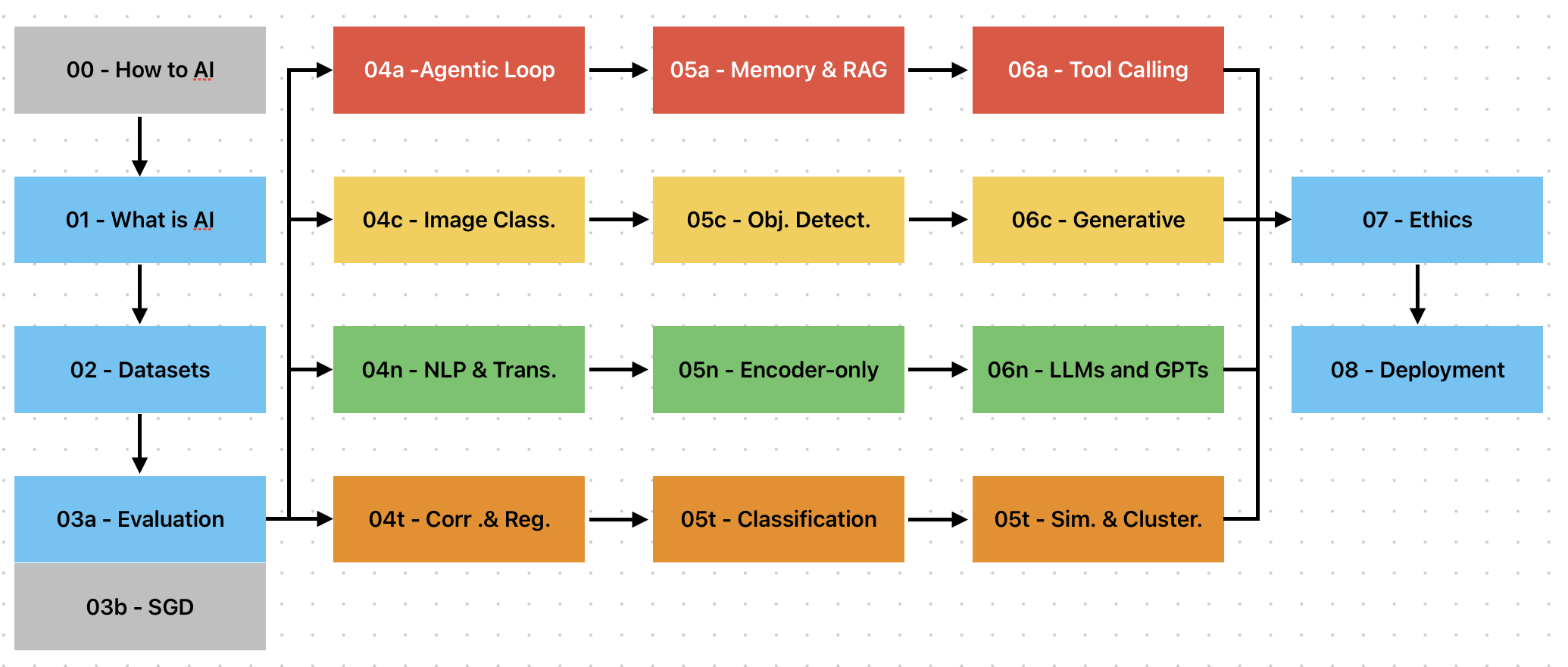
- บทที่ 0 - How to AI 2026 [Recommended Setup for AI Builders]
- บทที่ 1 - Artificial Intelligence (AI) คืออะไร
- บทที่ 2 - ชุดข้อมูลมหัศจรรย์และถิ่นที่อยู่
- บทที่ 3 - Stochastic Gradient Descent ตั้งแต่เริ่มต้น
- Track - Agentic
- Track - Vision
- Track - Texts
- Track - Tabular Data
- บทที่ 7 - จริยธรรมปัญญาประดิษฐ์
- บทที่ 8 - Prototype Deployment
ในบทเรียนนี้เราจะแนะนำเครื่องมือที่จำเป็นสำหรับการพัฒนา AI ในโครงการ AI Builders 2026 เพื่อให้ทุกคนสามารถทำโครงงานให้เสร็จภายใน 8 สัปดาห์ได้อย่างมีประสิทธิภาพ
Video: YouTube
Notebooks: TH
ในบทเรียนนี้เราจะเรียนรู้ว่า Artificial Intelligence (AI), Machine Learning (ML), Deep Learning (DL) และ Large Language Model (LLM) คืออะไร เหมือนกันหรือแตกต่างกันอย่างไร สามแนวทางการพัฒนาระบบปัญญาประดิษฐ์ที่กำลังเป็นที่นิยมในปัจจุบันคืออะไร-แนวทางไหนเหมาะกับการใช้งานแบบใด เราจะเรียนรู้ส่วนประกอบของระบบปัญญาประดิษฐ์ วิธีการ "โปรแกรม" LLM (แทนที่จะแค่ prompt), เทรน machine learning model ด้วยตัวอย่างจำแนกรูปภาพอาหารไทย 48 ชนิดจากชุดข้อมูล FoodyDudy หลังจากนั้นเราจะเรียนรู้วิธีการวัดผลเบื้องต้น (ก่อนไปเรียนละเอียดในบทที่ 3) และความท้าทายของการวัดผลในโลกที่ LLM ให้ผลลัพธ์ที่ไม่ตายตัว
Video: YouTube
ในปัจจุบันชุดข้อมูลที่มีพร้อมทั้งปริมาณและคุณภาพเป็นส่วนสำคัญในการสร้าง AI Systems ในบทเรียนนี้เราจะเรียนรู้วิธีการหาข้อมูลมาเทรนโมเดลของเราทั้งจากชุดข้อมูล open data, web scraping, หรือสร้างขึ้นมาเองจากโมเดลและโค้ด open source ทั้งนี้การหาข้อมูลมาเทรนโมเดลจากแหล่งข้อมูลสาธารณะที่กล่าวมานั้นเราต้องให้ความสำคัญเรื่องลิขสิทธิ์และจริยธรรม (แม้แต่โมเดลเองก็สร้างข้อมูลที่ผิดลิขสิทธิ์-จริยธรรมได้; เรียนเพิ่มเติมในบทที่ 7)
Video: YouTube
ในบทเรียนนี้เราจะเจาะลึกเรื่องการวัดผลและการเปรียบเทียบกับ baseline ตั้งแต่การแบ่งข้อมูล train/valid/test split อย่างถูกต้อง, metric สำหรับ classification, regression metrics, information retrieval ไปจนถึงการประเมินระบบ LLM ยุคใหม่ด้วย semantic similarity, LLM-as-Judge และ rubric-based scoring พร้อมกรอบการตัดสินใจเลือก metric ที่เหมาะสมกับแต่ละ task
Video: YouTube
ในบทเรียนนี้ เราจะทำการสร้างวิธีที่โมเดลของเราเรียนรู้ในบทเรียนที่แล้วๆมา เรียกว่า stochastic gradient descent ขึ้นมาเองตั้งแต่ต้นโดยใช้เพียงแค่ Pytorch สำหรับ linear algebra และการทำ partial derivatives เท่านั้น ด้วยตัวอย่างการจำแนกรูปภาพตัวเลข 3 และ 7 ออกจากกัน
บทเรียนแปล-สรุปมาจาก 04_mnist_basics.ipynb ของ fastai ผู้ที่สนใจสามารถไปติดตามบทเรียนต้นทางได้ที่ course.fast.ai
Video: YouTube
Notebooks: TH
Track - Agentic
Week 4 - 4a Agentic AI from Scratch
เนื้อหาในบทเรียนนี้:
- ทำความเข้าใจ LLM เบื้องต้น
- รู้จัก ReAct framework สำหรับการสร้าง LLM driven agents
- เทคนิคการใช้ CoT และ Few-shot prompting เพื่อเพิ่มความแม่นยำให้ agents
- ปัญหาที่พบบ่อย (Common failure cases) พร้อมแนวทางแก้ไขในบทเรียน
โดยเราจะสร้าง agent ในรูปแบบพื้นฐานที่สุดเป็นตัวอย่างด้วย LLM
gemma-3-1b-it
Video: YouTube
Notebook: Agentic AI from Scratch
Week 5 - 5a RAG and Automating Prompting
เนื้อหาในบทเรียนนี้:
- การ deploy LLM ดัวย llama cpp (กับวิธีอื่น ๆ)
- การใช้ LangGraph เขียน Agents
- RAG - ทำให้ agent ค้นข้อมูลใน vector databases
- APE ดัวย DSPy ทำให้ prompt พัฒนา โดยเราจะสร้าง agent ที่ดีขี้นเพื่อตอบคำถามที่อยู่นอก training scope
Video: YouTube
Notebook: RAG and APE
Disclaimer: due to complex file heirarchy and a need for reproducible environments, please use this repository for local execution.
Week 6 - 6a Programmatic Tool Calling and Other Topics
เนื้อหาในบทเรียนนี้:
- การเขียน custom tools นอกเหนือจาก RAG
- รวมส่วนประกอบจาก week ก่อน ๆ (ReAct and RAG) เข้าด้วยกัน
Video: YouTube
Notebook: Tool Calling
Disclaimer: due to complex file heirarchy and a need for reproducible environments, please use this repository for local execution.
Track - Vision
Week 4 - 4v Image Classification and Semantic Segmentation
ในบทเรียนนี้เราจะเรียนรู้ว่าการวิเคราะห์ภาพด้วย AI ในหัวข้อ Image Classification (การจำแนกประเภทภาพ) และ Semantic Segmentation (การแบ่งส่วนภาพระดับพิกเซล) มีหลักการทำงานอย่างไร โดยเริ่มตั้งแต่การปูพื้นฐานทฤษฎี Convolutional Neural Network (CNN) และ Vision Transformer ไปจนถึงการลงมือทำจริงด้วยไลบรารี Hugging Face และ PyTorch นอกจากนี้ยังสอนตั้งแต่การเตรียมชุดข้อมูล, การฝึกสอนโมเดล (Train Model), การประเมินผล ไปจนถึงการสร้าง Web Application ง่ายๆ ด้วย Gradio เพื่อทดสอบโมเดลที่เทรนเสร็จแล้ว
Video: Youtube
Notebooks: Image Classification, Semantic Segmentation
ในบทเรียนนี้เราจะเรียนรู้ว่าการทำ Object Detection (การตรวจจับวัตถุ) และ Instance Segmentation (การตรวจจับพร้อมแยกส่วนวัตถุ) ทำงานอย่างไร โดยเจาะลึกตั้งแต่ทฤษฎีพื้นฐานของ Bounding Box, สถาปัตยกรรมโมเดล (CNN และ Transformers), รูปแบบข้อมูล (YOLO, COCO) และการวัดผล (mAP) รวมถึงการสาธิตเขียนโค้ดจริงเพื่อเทรนโมเดลด้วย Ultralytics (YOLO) และ Hugging Face นอกจากนี้ยังแนะนำเทคนิคประยุกต์ใช้ Segment Anything Model (SAM) ในการสร้าง Mask อัตโนมัติ (Pseudo Label) เพื่อลดเวลาทำ Data Annotation ครับ
Notebooks: Object Detection, Instance Segmentation
ในบทเรียนสัปดาห์ที่ 6 ของ Vision Track เราจะมาทำความรู้จักกับ Multimodal Large Language Model (MLLM) ซึ่งเป็นโมเดลภาษาขนาดใหญ่ที่ไม่ได้จำกัดแค่การรับข้อความ แต่สามารถเข้าใจบริบทจาก "ภาพนิ่ง วิดีโอ หรือเสียง" ได้ด้วย (เช่น การป้อนรูปภาพแล้วให้ AI อธิบายภาพ)
บทเรียนนี้จะเจาะลึกไปถึงกลไกสถาปัตยกรรมการเชื่อมต่อ Vision Encoder เข้ากับ Large Language Model (เช่น การใช้ Projector/Adapter และ Cross-Modality Attention) รวมถึงสอนเทคนิคการปรับจูนน้ำหนักโมเดลขนาดใหญ่ด้วยเทคนิค LoRA (Low-Rank Adaptation) เพื่อให้เราสามารถไฟน์จูนโมเดลพันล้านพารามิเตอร์บนการ์ดจอขนาดเล็กได้ พร้อมสาธิตการเขียนโค้ดไฟน์จูนโมเดลเพื่อตอบคำถามจากภาพถ่ายดาวเทียม (Visual Question Answering)
Video: Youtube Notebook: Multimodal
Video: Youtube Playlist Slide: pdf
ในบทนี้จะแนะนำเห็นภาพรวมของ Natural Language Processing และ Application และเรียนรู้เกี่ยวกับโมเดล Transformer ซึ่งเป็นโมเดล NLP ที่สำคัญที่สุดในขณะนี้
Video:
Encoder-only language model เป็นโมเดลที่สามารถปรับจูนเพื่อทำ text classification ที่ดีที่สุด และสะดวกที่สุดตัวหนึ่ง อีกทั้งเป็นพื้นฐานสำหรับโมเดลภาษาขนาดใหญ่ ในบทนี้ผู้เรียนจะได้ทดลองใช้ Hugging Face (transformers, datasets, tokenizers) เพื่อเทรนโมเดล NLP
Video:
- Encoder-only model
- Huggingface tutorial: Fine-tuning encoder-only models for sequence classification
Notebooks: Huggingface
Large language models (LLM) และ ChatGPT เป็นโมเดลที่ทำให้ AI กลับได้รับความนิยมอีกครั้ง และจัดเป็นการปฏิวัติวงการ NLP ครั้งใหญ่ครั้งหนึ่ง บทนี้จะพูดถึงการเทรน Large language model และการเขียน prompt ที่จะทำให้ใช้งาน LLM สำหรับการสร้าง NLP Application
Video:
Reading: Chapter 10 Programming for NLP Application
การสร้างสมการความสัมพันธ์ (correlation) เพื่อทำนายตัวแปรประเภทตัวเลข (numerical) เพื่อนำไปใช้ในการหาความสัมพันธ์หรือพยากรณ์ เช่น การหาความสัมพันธ์ระหว่างตัวแปรที่มีผลต่อยอดขาย หรือ ทำนายพยากรณ์ยอดขายในอนาคต
Notebooks: Part 1, Part 2, Part 3
Week 5 - บทที่ 5t - Classification
การสร้างสมการความสัมพันธ์ เพื่อทำนายตัวแปรประเภทกลุ่ม/ชนิด (categorical) เพื่อใช้ในการทำนายหรือเลือกทางเลือก เช่น ทำนายว่าลูกค้าคนไหนจะหยุดใช้บริการ ทำนายว่าลูกค้าคนไหน เมื่อส่งคูปองไปแล้วจะใช้ หรือ ทำนายว่าเครื่องจักรจะเสียหรือไม่
การวิเคราะห์ความคลายคลึงและการแบ่งกลุ่มข้อมูล เพื่อนำไปใช้ในการแนะนำสินค้าหรือเนื้อหาที่ลูกค้าสนใจ เช่น Shopee แนะนำสินค้าที่เราสนใจ หรือ spotify แนะนำเพลงที่ผู้ฟังน่าจะอยากฟังต่อไป รวมถึงการนำข้อมูลมาใช้ในการแบ่งกลุ่มลูกค้าที่มีความสนใจเหมือนกันสำหรับนำไปทำการตลาดเฉพาะกลุ่ม
Week 7 - บทที่ 7 - จริยธรรมปัญญาประดิษฐ์
เมื่อปัญญาประดิษฐ์เข้ามามีบทบาทในชีวิตประจำวัน รวมถึงใช้ในการทำงานสาขาต่างๆ อาทิ ช่วยตรวจโรค ช่วยตรวจจับผู้กระทำผิด หรือช่วยตัดสินค่าตอบแทน/บทลงโทษ ฯลฯ จะเห็นได้ว่าปัญญาประดิษฐ์เกี่ยวข้องกับประเด็นทางสังคมและส่งผลกระทบต่อคนเป็นจำนวนมาก บางครั้งปัญญาประดิษฐ์มีการตัดสินใจที่ผิดพลาด ส่งผลกระทบกับชีวิตของคน หลายครั้งปัญญาประดิษฐ์เป็นส่วนหนึ่งของการเผยแพร่อคติโดยที่ผู้พัฒนาคาดไม่ถึง หรือบางกรณีเป็นการจงใจนำปัญญาประดิษฐ์ไปใช้เพื่อการทำร้ายผู้อื่น การพัฒนาปัญญาประดิษฐ์จึงต้องคำนึงถึงหลักจริยธรรมปัญญาประดิษฐ์หรือ AI Ethics ในการพัฒนาเทคโนโลยีอย่างมีความรับผิดชอบ ในสัปดาห์นี้ เราจะมาทำความเข้าใจว่าปัญญาประดิษฐ์โดยเฉพาะ Generative AI ที่เข้ามามีบทบาทในชีวิตของเราอย่างมากก็สามารถมีอคติในการรับและเผยแพร่ข้อมูลได้อย่างไร รวมถึงคำนึงถึงโอกาสที่เทคโนโลยีจะถูกนำไปใช้ในทางที่ผิดและเราจะหาทางป้องกันความเสี่ยงได้อย่างไร
บทเรียนนี้แปลเป็นภาษาไทยและเพิ่มเติมเนื้อหาจาก Lesson 5 ของ fastai Practical Deep Learning for Coders v4 part1 โดย Rachel Thomas
Video: YouTube
Slides: pdf
Week 8 - บทที่ 8 - Prototype Deployment
ในบทเรียนนี้เราจะเรียนรู้วิธีเปลี่ยน AI / ML prototype จาก notebook ให้กลายเป็น web prototype ที่แชร์ผ่าน public URL ได้จริง โดยใช้ marimo บน Google Colab สำหรับทดลองสร้าง interactive app และใช้ Hugging Face Spaces สำหรับ deploy โดยผู้เรียนสามารถสร้าง Space, แก้ไขไฟล์ app.py และ requirements.txt และ commit ผ่านหน้าเว็บของ Hugging Face ได้โดยตรง
เป้าหมายคือให้นักเรียนสามารถเปลี่ยนงานจาก notebook ให้เป็น demo ที่รันซ้ำได้ แชร์ได้ และเปิดให้ผู้อื่นทดลองใช้งานได้จริง โดยข้ามขั้นตอน deployment ที่ซับซ้อน
Video: YouTube
Notebook: Prototype Deployment
ส่วนหนึ่งของบทเรียนของ AI Builders ทำการดัดแปลง-แก้ไข-ต่อเติมจาก fastai Practical Deep Learning for Coders v4 part1 ตามลิขสิทธิ์ GNU General Public License v3.0 เพื่อให้เหมาะแก่นักเรียนผู้ใช้ภาษาไทยเป็นภาษาแรก ได้แก่ บทที่ 1 และ 2 (ปรับแต่งจาก Lesson 1 พร้อมเพิ่มเติมเนื้อหา), 3b (ปรับแต่งจาก Lesson 3 และ Lesson 4) และ 7 (แปลเป็นภาษาไทยและเพิ่มเติมเนื้อหาจาก Lesson 5)
We adapted and augmented some lessons from fastai Practical Deep Learning for Coders v4 part1 for our curriculum to suit our students whose first language is Thai, namely Lesson 1 and 2 (adapted from Lesson 1; augmented our original contents), Lesson 3b (adapted from Lesson 3 and Lesson 4), Lesson 7 (translated from Lesson 5 and added localized examples).