| Folder | Project | Status |
|---|---|---|
| /DeepSeek | Deepseek R1 https://www.youtube.com/watch?v=XMnxKGVnEUc&t=20s tiny R1 https://github.com/Jiayi-Pan/TinyZero | Not Started |
| /Vision | R1 https://www.youtube.com/watch?v=XMnxKGVnEUc&t=20s tiny R1 https://github.com/Jiayi-Pan/TinyZero | Not Started |
| /Llama2 | Llama2 from scratch https://www.youtube.com/watch?v=oM4VmoabDAI&pp=0gcJCUUJAYcqIYzv | Not Started |
| /stable-diffusion | Coding stable diffusion from scratch https://www.youtube.com/watch?v=ZBKpAp_6TGI | Not Started |
| /flash-attention | triton Flash Attention kernel https://youtu.be/zy8ChVd_oTM?si=5106nYOB4sj_X5RQ | Not Started |
| /SFT | Supervised Fine Tunining - InstructGPT https://arxiv.org/abs/2203.02155 | Not Started |
| /GPT-2 | GPT-2, replicating GPT2 from scratch following karpathy/nanoGPT but with my own tokenizer | ✅ Completed |
| /BERT | BERT, replicating BERT paper (without additional guidance) using my own tokenizer | ✅ Completed |
| /llm-tokenizer | Tokenizers, LLMs tokenizers following karpathy/minbpe | ✅ Completed |
| /mingpt | MiniGPT, implementing transformers from 'Attention is All You Need' following karpathy/minGPT | ✅ Completed |
| /makemore | Makemore, simple language models following karpathy/makemore | ✅ Completed |
| /micrograd | Micrograd, implementation of backpropagation following karpathy/micrograd | ✅ Completed |
| /zero-shot-retrieval | Zero Shot LLM Retrieval, submissions to Kaggle VMWare Zero-shot Retrieval competition | ✅ Completed |
| /personalized-fashion-recommendations | SparseNN Recommender System, submissions to Kaggle H&M Recommender System competition | ✅ Completed |
| /algorithms | Codeforces contests and Leetcode Hard Design questions | 🟠 In Progress |
Replicated GPT2 from scratch following karpathy/nanoGPT but with my own tokenizer, achieving same loss and eval performance to hugging face GPT2 model. This is an example of improving token/s throughput for given model size by optimizing pytorch operations. Read more on my GPT2 training notes
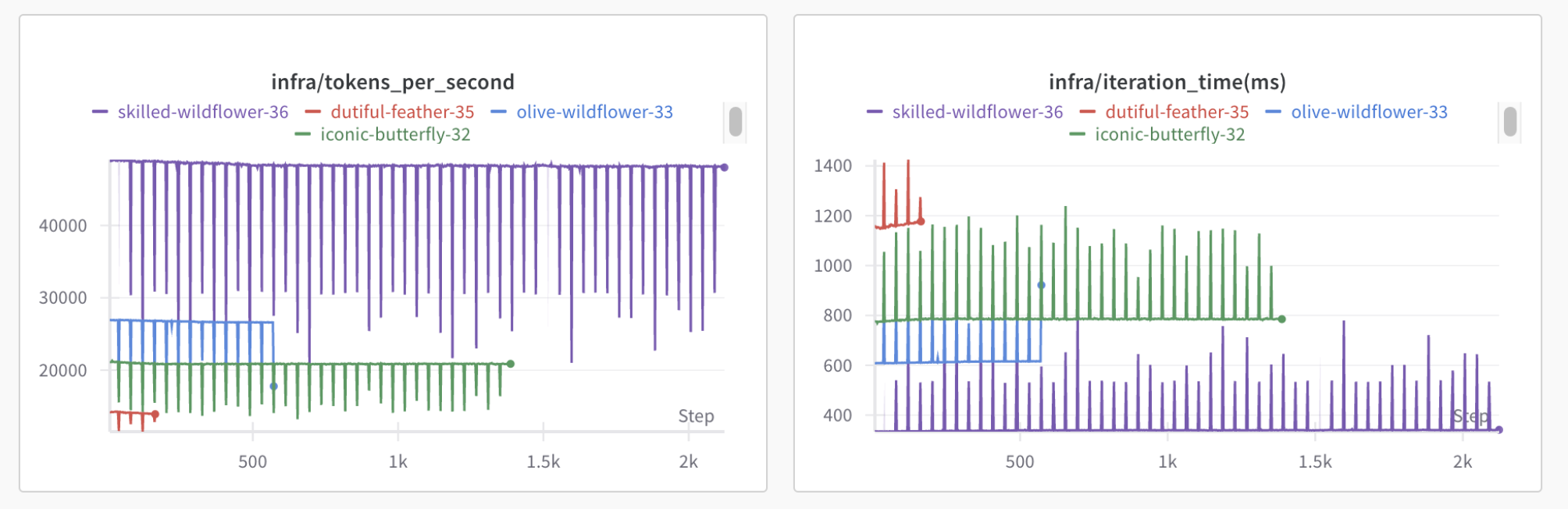
Implemention of BERT paper without additional guidance using my own tokenizer. This is an example of pretraining on Next Sentence Prediction (NSP) and Masked Language Modelling (MLM) tasks.
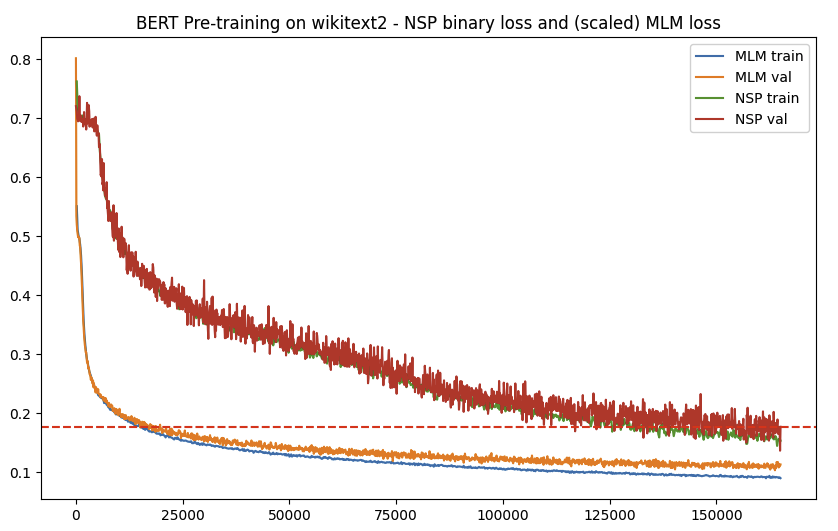
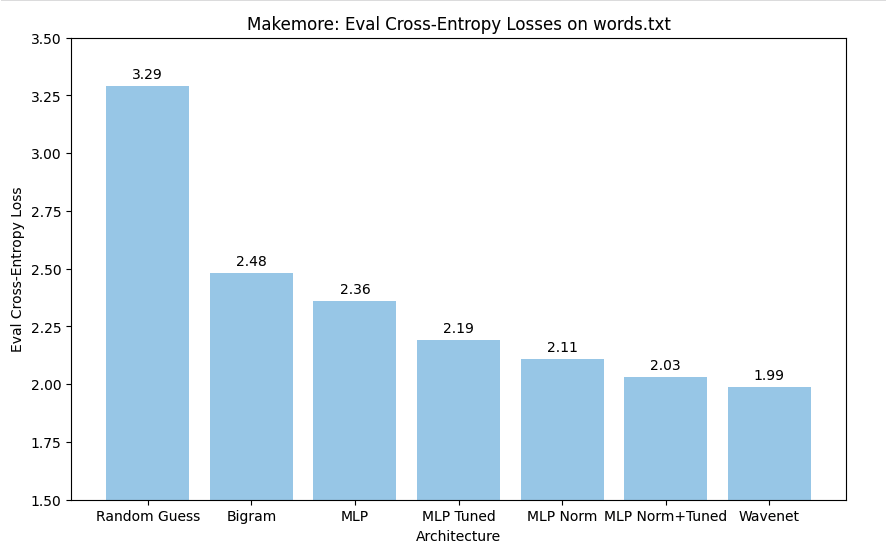
Implementation of "Attention is All You Need" trasfomer architecture with minimal pytorch APIs, similar to karpathy/minGPT. This is the next word prediction cross-entropy loss achieved on the Shakespeare dataset with different baselines.
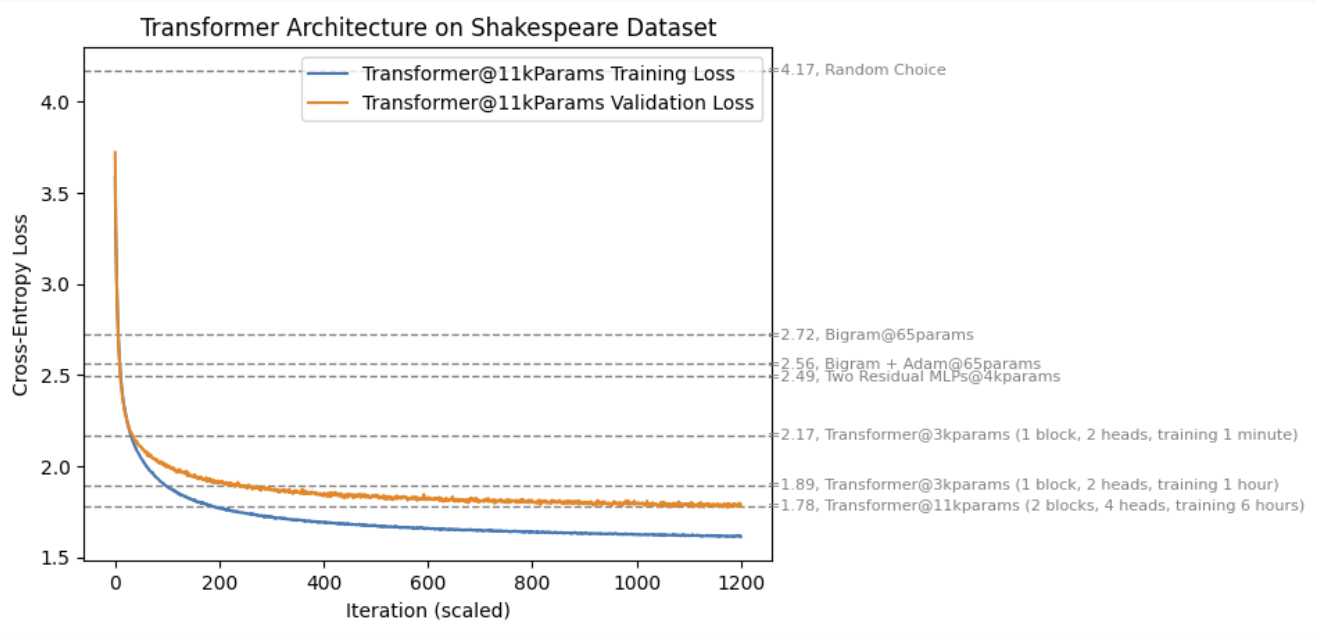
*the number of parameters is wrong, should be in the range of millions. Re-running the best model with Karpathy hyperparams achieved a validation loss of 1.66. This is an example generation of Shakespeare like text with Transformer@3k parameters.
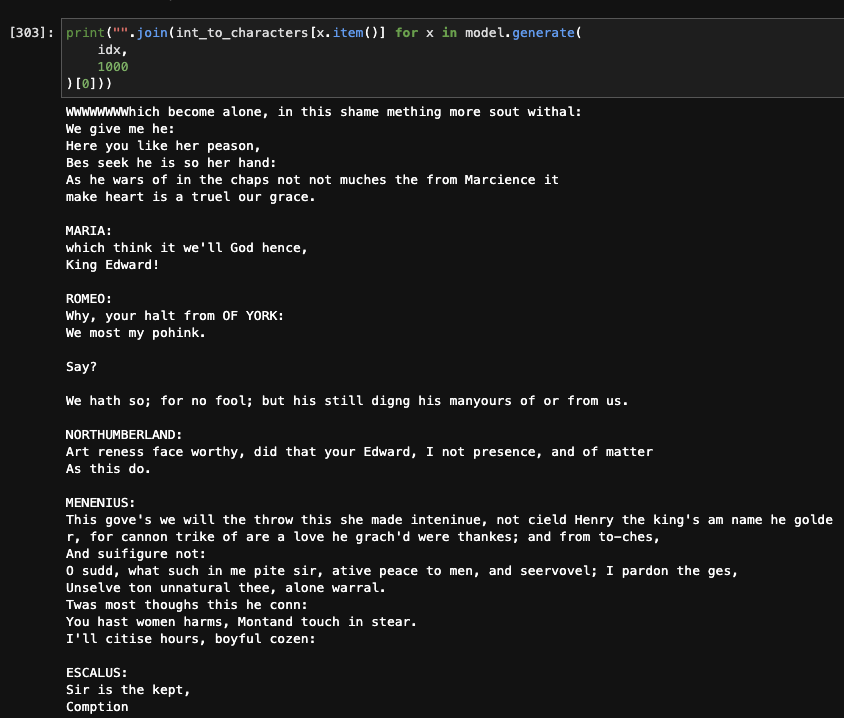
Replicated the makemore repo from Karpathy from his Zero to Hero NN course. Implementation of name-generation language models. Bi-grams, MLP, RNNs and other models in plain pytorch. This is the performance I was able to reproduce independently on the several architectures covered in the course.
Here are some interesting histogram from hyperparameter search on some simple language model
Python-only implemention of Neural Networks. Playing with my own implementation of micrograd from Karpathy. Some interesting results

- make_moons_30_Jan_A.ipynb - a small MLP is able to optimize loss function, but it learns a linear function. Not able to make the model learn non linearity.
- make_moons_30_Jan_B.ipynb - a small MLP with more techniques is able to learn non linear function from scikit learn moon. The circles function are half learned but not completely


Using VMWare docs corpus (30M documents) from Kaggle to implement a e2e retrieval system using LLM encoders and generative models. Picture below is the tensorboard of the 12 stacked transformer blocks from https://huggingface.co/intfloat/e5-small-v2 used for text embedding
Using Fashion Recommender System dataset to build a muli-stage ranking recommender system for 10M users and 100k fashion articles https://www.kaggle.com/competitions/h-and-m-personalized-fashion-recommendations
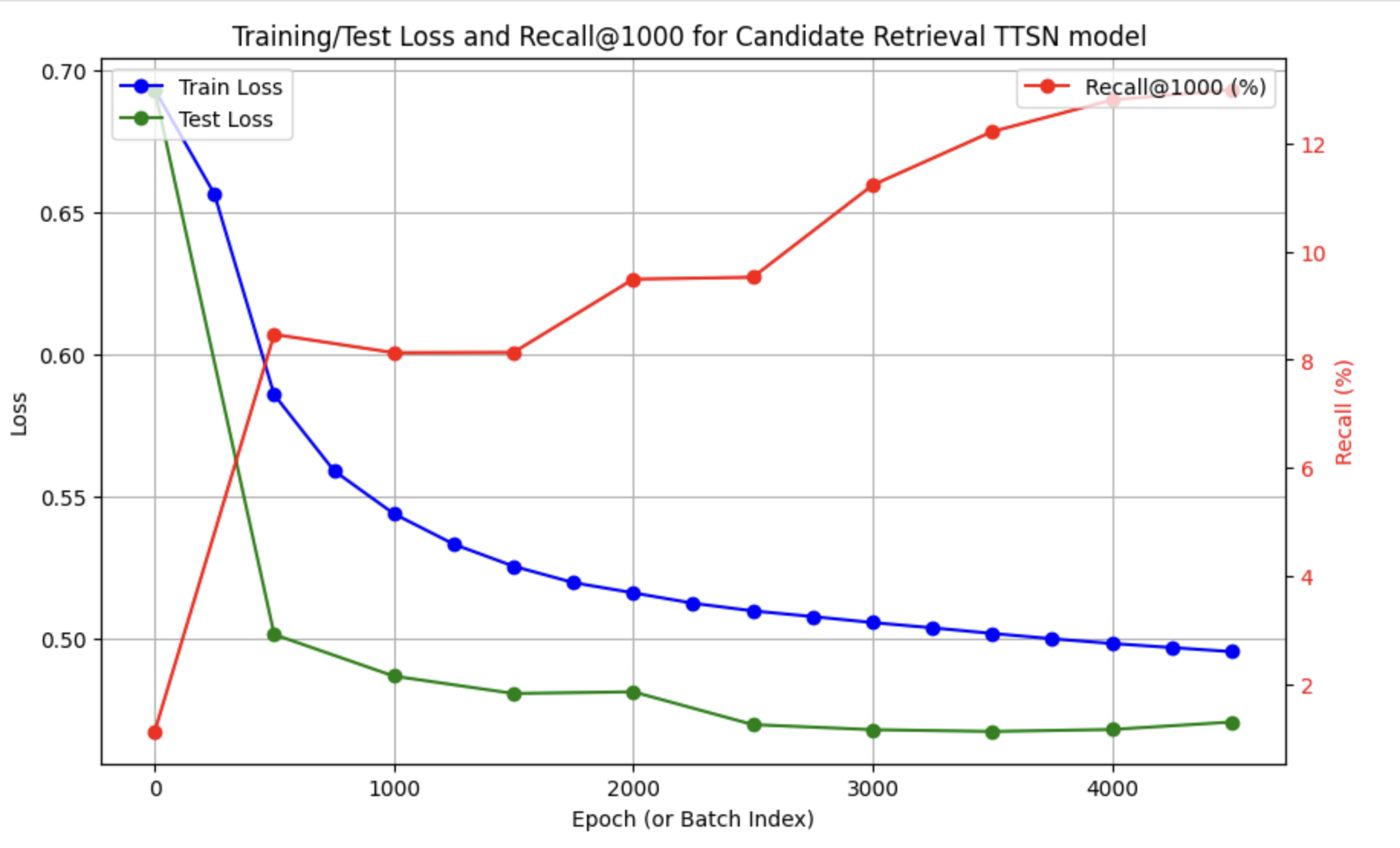
- personalized-fashion-recommendation-2-Feb-B.ipynb TTSN model for candidate retrieval, trained only on categorical features with customer and article tower, improving recall@1000 from 1% to 10%. Will probably need to bring recall higher before moving on to ranking stage.
- https://github.com/alirezadir/machine-learning-interviews/blob/main/src/MLSD/ml-system-design.md
- https://pytorch.org/tutorials/intermediate/torchrec_intro_tutorial.html
- https://www.kaggle.com/competitions/otto-recommender-system/discussion/384022
- https://web.stanford.edu/class/cs246/slides/07-recsys1.pdf
- http://cs246.stanford.edu/
- Tue Jan 28 Recommender Systems I
- [slides]
- Ch9: Recommendation systems
- Thu Jan 30 Recommender Systems II
- [slides]
- Ch9: Recommendation systems
- https://applyingml.com/resources/discovery-system-design/
- https://applied-llms.org/
- Neel Nanda Transformers https://www.youtube.com/watch?v=bOYE6E8JrtU&list=PL7m7hLIqA0hoIUPhC26ASCVs_VrqcDpAz&index=1