题目 4 —— “AutoSolver:让 AI Agent 自主求解配送分配问题” (Keeta Department)
互联网经济的核心是外卖配送,而高效地将订单-骑手最优配对对于美团为首的企业至关重要。本系统是一个对于固定格式的“骑手-订单”数据进行自动学习与编写求解脚本的 Agent。这不是一个单一算法脚本,而是一个会自动持续学习、复盘、迭代,故而生成的脚本越来越强的本地系统。 给它数据集和 API,它给你一条可追踪、可解释、可改进的求解进化路径。
我的 MTASA 系统由四个完全独立的相互可交互模块组成:
- genius (“全知者”):本地评测器,负责接收数据集,并验证、打分、出报告。
- fool (“无知者”):迭代性 AI Agent,负责改 solver、模块内轻量级烟测、提交给 Agent 测试、读结果、再改进的循环学习。
⚠️ 拥有复杂的多层级缓存式记忆体,并用 BM25 算法访问记忆。 - teacher (“教育者”):包含另一个独立的 Teacher AI,拥有经验和策略知识库,负责提醒方向、避坑、约束,
⚠️ 防止反复回退基线版本、防止违法行为(比如引用非公共库、代码体超过 100K、未改动就提交测试…)。 - frontend (前端):本地控制台,GUI 展示,帮助用户配置、启动、观察全流程(如有需要)。
💡 模仿人类学习:核心就是 全知者 和 无知者 的递归式交互,无知者在测试和探索中逐渐拟合/逼近全知者,模拟 “人类(我)参加美团黑客松” 的学习过程。
💡 模仿计算机内存:AI Agent 最大痛点便是上下文空间不足。使用多层可检索缓冲型记忆,防止上下文压缩导致的记忆紊乱。
💡 工具集:Agent 与“单纯的 LLM-tools”的最大区别便是能够调用工具,以及可以“不达目的不罢休地运行”。没有一系列恰当的工具集,Agent 就像失去手脚的大脑。我准备了 TeacherAI、代码块修改、记忆读/写等等工具。
💡 "真"迭代:我们的迭代是“修改式”的,即每个版本都站在前一轮的基础上。而不是像大部分人那样直接裸调用 AI,就会变成“每一轮重写一个脚本”,那样进展较慢且浪费 token。
我认为我的系统确实与众不同,至少它不能被随便地 Vibe Coding 出来——关键在于,模拟我(一个十足的无知者)在这次黑客松比赛的真实学习过程,它隐含着的就是我,一个人类从 0 开始的学习过程。
本人毫无相关基础背景,对于 “ILP, 美团的 SCDN 算法, 匈牙利算法” 等名词闻所未闻(报名时本以为是
A*/BFS之类的加权寻路优化)。反倒因此,我在本次项目中获得了刚开始难以设想的收获,甚至感激这次机会。它促使着我学习新领域,把经验、失败和判断标准结构化,最后沉淀成可重复的方法 —— 而这一切浓缩到了最终这个 Agent 系统中。
这个系统最关键的一点是:它在模仿人类(我)的学习过程。
无知者承认其无知,从纯贪心算法出发,基于证据/有限信息提出小假设或改进,向全知者求证。保存失败与成功经验,保留所有版本脚本。自适应——从失败里学习,迭代越久越长——这个过程本身非常有价值。
我推测出了几乎与线上网站完全精准一致的评分公式!我很好奇大家是否都能做到。
Genius 的核心评分位于 genius/official_like.py,目标是最小化 penalty 分数。
对一条输出行:主骑手 + 若干备选骑手(c1 ~ cm),记候选序列为
其中 puncov 代表所有骑手都拒单时的失单惩罚,显然,非合单为 100,合单为 200。故而整个解的总成本为每行的算数平均 C:
在反复的使用已知数据集 large_seed301 进行线上测试结合本地解输出分析后,我统计发现行分数采用意愿升序和降序两次递归的算数均值:
这便是我用 Excel 和统计学理论分析得到的最优拟合评分函数。它不完全等于线上打分规则,但最多只有 ±3 分左右的差距(除非有违规行为)。
项目采用 probe 驱动的数据反演方法(详见 teacher/DATASET_FEATURE.md):
- 以
$\phi(c)\in\mathbb{R}^{19}$ 描述每个 case 的结构特征向量(规模、bundle 结构、score/willingness 分布、联合统计等)。 - 通过在线 probe 的 subset-sum 编码把特征桶映射到可观测分差,再由线上 report 反解桶区间。
核心解码关系:
这等价于把隐含特征投影到离散桶空间,再进行逆映射校准。其价值在于:
- 不依赖单个本地文件锚点,避免线上/本地行级漂移带来的误判。
- 可将 case 识别从经验判断升级为可验证的统计画像。
- 能直接支撑模拟集生成与策略分桶(tiny/small/medium/large/low_w/scarce/high_noise)。
Fool 内置两层长期记忆:
- 数据集级记忆(
FoolMemory)- 持久化回合结果:
episodes.jsonl、strategy_index.json、session_summaries.jsonl - 检索使用 BM25-hybrid 排序(关键词匹配 + case-tag 重叠 + 最近收益加权)
- 持久化回合结果:
- 全局笔记记忆(
MemoryNotesStore)- 一条知识一份 Markdown(含 frontmatter 元数据)
- 聚合索引
MEMORY.md自动重建,供下一轮 header 直接引用
检索可抽象为:
从而把“记住历史”变成“可度量、可排序、可复用”的工程能力,而不是纯文本堆积。
Teacher 能力分两条链路:
- 静态策略注入:每轮系统前缀固定携带 playbook,约束动作边界与优化方向。
- 周期 Teacher Review:当迭代停滞/周期触发时,生成结构化 verdict(observation / exhausted_directions / next_candidates),并注入下一轮 round header。
可视为一个慢变量控制器:
其中
每轮由 run_round 执行受约束的工具调用循环:
- 构造 prefix + round header(含最近历史/记忆索引/可选 teacher review)
- LLM 输出
<intent>+ 工具调用 - 使用
block_patch对 draft 做最小增量修改 - 运行
smoke_test_solver做本轮提交前冒烟验证 - 输出
<final>,提交 Genius,读取正式报告 - 以 outcome 分类更新记忆与桶冠军
其中 outcome 不只看全局均分,而是桶级别的改进判定:
这使系统具备“局部突破可累积、全局目标不丢失”的多目标推进能力。
Fool 编辑脚本的核心不是自由删除重写整个文件,而是受限块替换,这样做才是“真”迭代:
block_patch使用 SEARCH/REPLACE 原子批量应用- 支持精确匹配、统一缩进容错、
...省略匹配 - 任一块失败则整批回滚,保证 draft 不被半写入污染
该机制把“LLM 修改代码”从不可控文本改写,收敛为可验证的事务操作,而普通的调用 API,每次都会推翻重做,毫无“积累经验”可言。
使用 qwen-3.7-max (思考强度 xhigh) ,首轮为纯贪心基线出发,对象数据集为仿线上网站的模拟数据集,运行迭代 15 轮的结果。存在明显学习过程曲线:
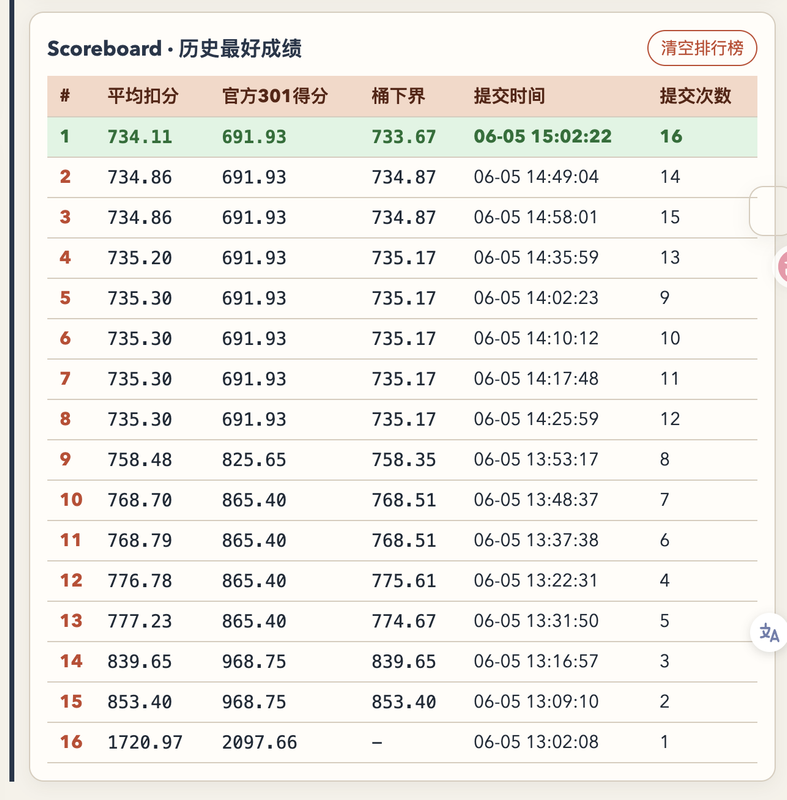
推荐环境:macOS / Linux
- 控制面(
run_local.py/fool_loop.py/genius_judge.py)建议使用 Python 3.10+ - 必须安装 Python 3.6。Genius 默认使用
python3.6执行 solver,因为线上测试系统为 3.6,如果您本机没有 Python3.6,请参见此处。
先确认本机可直接调用:
python3.6 --version若命令不存在,Genius 会返回 FATAL 报告(属于环境问题,不是算法分数问题)。
pip install requests tiktoken如果您使用的是 pip3:
pip3 install requests tiktokenSolver 提交脚本本身不应依赖任何第三方库(纯 stdlib)。
如需显式指定 solver 解释器(例如 pyenv/conda 下的 3.6 路径):
python genius/genius_judge.py \
--solver fool/templates/solver_greedy.py \
--input-dir data/sample_10_cases \
--scoring official_like_latest \
--report out/reports/report.txt \
--python-cmd /absolute/path/to/python3.6测试(非必需):
python -m pytest genius/testsgit clone 本仓库后,在终端-仓库根目录执行:
python run_local.py或:
python3 run_local.py启动后打开任意浏览器访问:
http://localhost:7860(若 7860 被占用,会自动尝试 7861、7862、7863...)
系统的前端可视化与进程管理就在此进行。
接下来,您需要:配置大模型的 API-key、导入您的数据集,即可开始运行 MTASA 系统!
一、前端支持读取 MacOS 系统的 ~/.zshrc(即 bash 的配置文件)中填写常见 API Key:
OPENAI_API_KEYANTHROPIC_API_KEY(或CLAUDE_API_KEY)OPENROUTER_API_KEYDEEPSEEK_API_KEYDASHSCOPE_API_KEY
二、如果您不使用 MacOS 系统,您也可以在 localhost 界面里手动填 API,直接点击“手动配置 API”按钮,然后填写,您不必担心密钥的安全问题,因为 localhost 是本机窗口。
假设您想使用千问 AI,MTASA 支持把百炼作为独立的 api_type=aliyun 接入,底层走 OpenAI 兼容的 Chat Completions 接口。
如果你在 ~/.zshrc 中配置了 DASHSCOPE_API_KEY,前端会自动发现该 profile。
手动配置示例:
{
"api_type": "aliyun",
"api_key": "$DASHSCOPE_API_KEY",
"base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"model": "qwen-plus"
}上游推理模型常见的 Reasoning Effort 档位可能包括:
none、minimal、low、medium、high、xhigh
不同 provider / 不同模型通常只支持其中一部分。MTASA 当前可选档位为 low / medium / high / xhigh。
⚠️ 请将您提供的正式的数据集放到根目录下的/data/sample_10_cases,替换原本的占位测试集。- 模型:建议 deepseek-v4-pro (及其他国内厂商,如 Minimax / Qwen 最新代的 pro 或 max 版本) 或 chatgpt-5.3-codex (或 5.5) 或 Claude-opus-4.7。
- 迭代轮数:建议 20~50,至少 20 轮,否则由于大模型的本质(高维语言概率计算)有可能结果不理想。
- 最大步数:50
- AI 回复的 Token 上限:128K (与具体模型相关)
Reasoning Effort:openrouter以及aliyun的模型可选high / xhigh;而deepseek-v4-pro一般用low / medium,否则会比较缓慢(甚至每次迭代 15~20 分钟)。其他模型还请您自由探索。⚠️ 填写后,点"检查 API",以确认连通。- 最后点击“开始运行”即可开始迭代。
三、运行过程中,您可以看到历史上每轮的分数、本轮迭代中十个数据集各自的具体成绩(就像官网那样)、AI 思考过程历史、Agent 调用工具历史等等,过程非常透明且可视。
四、如果运行中出现报错,如若不是您网络或者 API 的问题,点击左侧的“继续”按钮即可继续。
五、如果您想要清空记忆重新做/更换数据集,请点击右侧的**“清空排行榜”和左侧的“归档并清空 out”**即可消除长期记忆。这样做会清空 Agent Memory,重新从基点出发。
python genius/genius_judge.py \
--solver fool/templates/solver_greedy.py \
--input-dir data/sample_10_cases \
--scoring official_like_latest \
--report out/reports/report.txtpython fool/fool_loop.py \
--api-type openai \
--api-key "$OPENAI_API_KEY" \
--model gpt-4.1-mini \
--iterations 10 \
--input-dir data/sample_10_cases \
--scoring official_like_latest这些约束由 Genius/流程强制执行:
- solver 入口固定:
solve(input_text: str) -> list[tuple[str, str]] - 输入固定为 TAB 分隔 4 列:
task_id_list, courier_id, total_score, willingness task_id_list中逗号是任务包,不是 CSV 分隔符- 同一
task_id不能重复分配 - 同一
courier_id不能重复使用(备份也算使用) - 评分模式固定:
official_like_latest - solver 文件不超过 100KB
- 本地单 case 默认上限 30 秒(对应线上约 10 秒预算)
- solver 提交路径必须纯 Python 标准库(不要引入外部依赖)
每次 run 会写到:
out/runs/<run_id>/solver_vNNN.pyout/runs/<run_id>/report_vNNN.txtout/runs/<run_id>/harness_vNNN.jsonout/runs/<run_id>/draft.pyout/runs/<run_id>/fool.logout/runs/<run_id>/dialog/round_NNN.jsonl
最佳结果在迭代结束时同步到:
- 脚本:
out/solvers/best_solver.py - 成绩:
out/reports/best_report.txt
项目的约束和 skills:
requirements.mdskill.mdteacher/DATA_STRATEGY_PLAYBOOK.mdteacher/MTASA_BOTTLENECK_OPTIMIZATION_GUIDE_CN.mdgenius/README.md与fool/README.md
很高兴您能耐心的读完这份挺长的报告,感谢您的阅读和使用,我由衷感到这次参赛机会蕴含的眼界、缘分和经验对我收获颇丰。很荣幸参与本次美团的首届,也是我的首次黑客松。
再次表达对美团 AI Hackathon 大赛活动项目组、尤其 Keeta 部门的感激。
Agent 记忆体: https://github.com/agentscope-ai/ReMe/blob/main/docs/copaw_context_design_zh.md
AI 自动替换/修改代码块: https://github.com/Aider-AI/aider/blob/main/aider/coders/editblock_prompts.py
模拟测试集参考美团官方开源数据:https://github.com/meituan/Meituan-INFORMS-TSL-Research-Challenge
美团关于 Agent AI 的见解:https://tech.meituan.com/2026/05/07/agent-ai-coding.html