A multi-provider LLM orchestration platform with intelligent routing, live token streaming, multimodal input, and GitOps-driven Kubernetes deployment.
Cortex treats LLM calls as a managed resource — routing each request to the optimal provider based on operation class, input size, and modality, with automatic failover across a four-provider chain and real-time token streaming over Server-Sent Events.
Single-provider LLM applications are brittle. Free-tier rate limits trigger at the worst moments. One provider's outage takes the whole product down. Long-context tasks fail on providers with small context windows. Multimodal inputs only work on a subset of providers. And users wait in silence while the model generates, with no feedback until the full response lands. Hardcoding any one provider into the application means accepting all of these failure modes.
Cortex addresses this with a routing layer that selects providers per-request based on the input, a streaming layer that pushes tokens to the browser the moment they arrive, and an eval suite that gates prompt and router changes in CI. The application code never talks to a specific provider — it submits a task to the router, which picks the right chain, handles failover automatically, and streams the output back through a Server-Sent Events channel. The chain attempted, the final provider used, and any mid-stream provider switch are all observable in the UI.
Each task selects a provider chain based on three signals — the operation, the input length, and whether the input contains an image. The first provider in the chain is tried first; on rate limit (429), quota exhaustion, or any other error, the worker falls through to the next provider automatically. Across four providers in the chain, the probability of all four failing simultaneously is effectively zero.
| Signal | Routing decision | Why |
|---|---|---|
| Image input | Gemini → OpenRouter | Gemini is the only multimodal provider in the chain |
| Input > 15,000 chars | Gemini → Cerebras → OpenRouter | Gemini's 1M context window handles arbitrarily long input |
| Reasoning operations (action items, key decisions, explain simply) | Groq → Cerebras → Gemini → OpenRouter | Slightly more deliberate output benefits these ops |
| Default (speed) | Groq → Cerebras → Gemini → OpenRouter | Groq's tokens-per-second is the dominant factor |
Rate-limit detection looks for 429, rate limit, quota, resource_exhausted, or too many in the exception message, advances to the next provider on a hit, and logs at warn level. Any other exception also triggers fallback but logs at error level. If the entire chain fails the task is marked failed and the full chain is persisted for diagnostics.
Polling is the wrong shape for LLM responses. The Node backend doesn't know when the model will finish, so polling either wastes bandwidth on idle checks or makes the user wait for the next interval to see a completed result. Cortex replaces it with Server-Sent Events.
When a task is created, the frontend opens an EventSource connection to GET /api/tasks/:id/stream. The backend snapshots the current task state from MongoDB, then subscribes to a per-task in-process event bus. The task processor calls the LLM provider with stream: true and forwards each chunk to the bus, which the SSE endpoint serializes to event: token frames. Tokens arrive in the browser the moment the upstream provider emits them.
Mid-stream provider fallback. If a provider drops the connection or returns an empty stream mid-response, the router emits a provider_switch event and starts fresh with the next provider in the chain. The frontend clears the partial output, shows a brief switch indicator, and resumes rendering tokens from the new provider. The pre-switch text is discarded because the new provider has no context for what was already written.
Auth design. EventSource cannot set custom HTTP headers, so the standard Authorization: Bearer <jwt> flow does not work. The SSE endpoint uses an httpOnly session cookie set at login time, separate from the Bearer token used by the rest of the API. The cookie is Secure and SameSite=None in production for the cross-origin Vercel-to-Render setup.
UI batching. Groq emits about 70 chunks per second. Calling React's setState on every chunk would re-parse the accumulated markdown 70 times per second. The modal buffers incoming tokens and flushes to state every 33ms, which is the maximum any human eye will perceive as continuous.
Keep-alive. Render's free tier proxy closes idle connections after ~30 seconds. The endpoint writes an SSE comment every 15 seconds, which keeps the connection alive without triggering any client-side event.
The streaming layer is implemented in backend/src/services/eventBus.js, backend/src/services/taskProcessor.js, and frontend/src/components/TaskModal.jsx. The kubernetes branch will replace the in-process bus with Redis pub/sub on channel task_updates:{taskId}, preserving the same external interface.
Every change to a system prompt or to the LLM router triggers an automated eval that scores the output against a versioned set of test cases. The eval lives in backend/eval/ and runs on every PR via GitHub Actions.
Each case declares an input, the operation to run, and a list of structural checks the output must pass — bullet count, required terms, forbidden terms, length bounds, and regex matches. The runner calls the real LLM router (with the full fallback chain), scores each case, and aggregates per-operation pass rates.
If any operation's pass rate drops more than 5 percentage points below the committed baseline, CI fails the build. Baseline updates are explicit — npm run eval -- --update-baseline — so accepted regressions require a deliberate commit.
The 5-point threshold is wide enough to absorb LLM nondeterminism (cases that flicker pass/fail run-to-run at temperature 0.7) but narrow enough to catch genuine prompt regressions. CI runs in smoke mode by default — one case per operation, with inter-case delays calibrated to fit Gemini's 5-RPM free-tier ceiling. The full 50-case run is available via manual workflow dispatch.
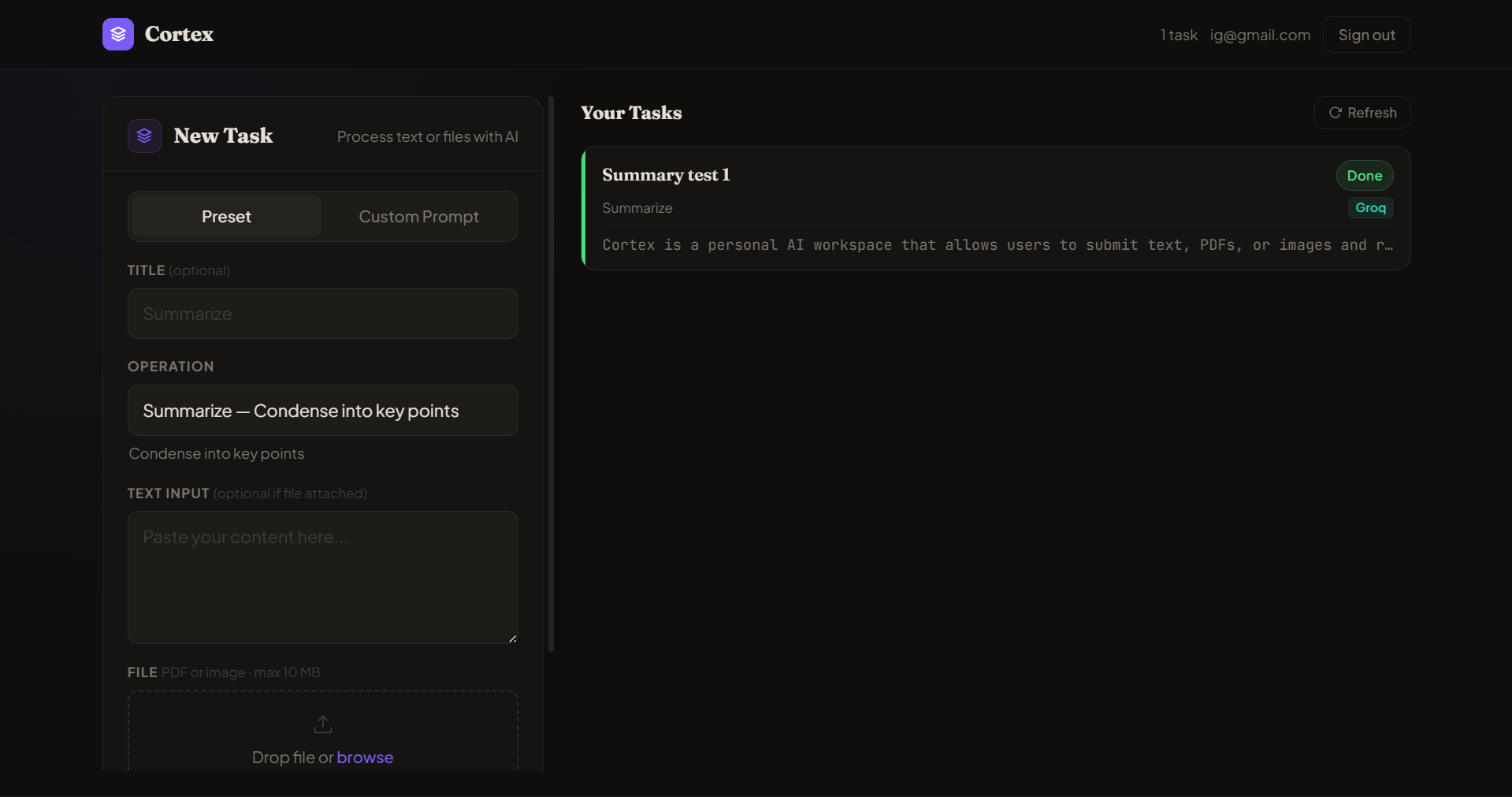
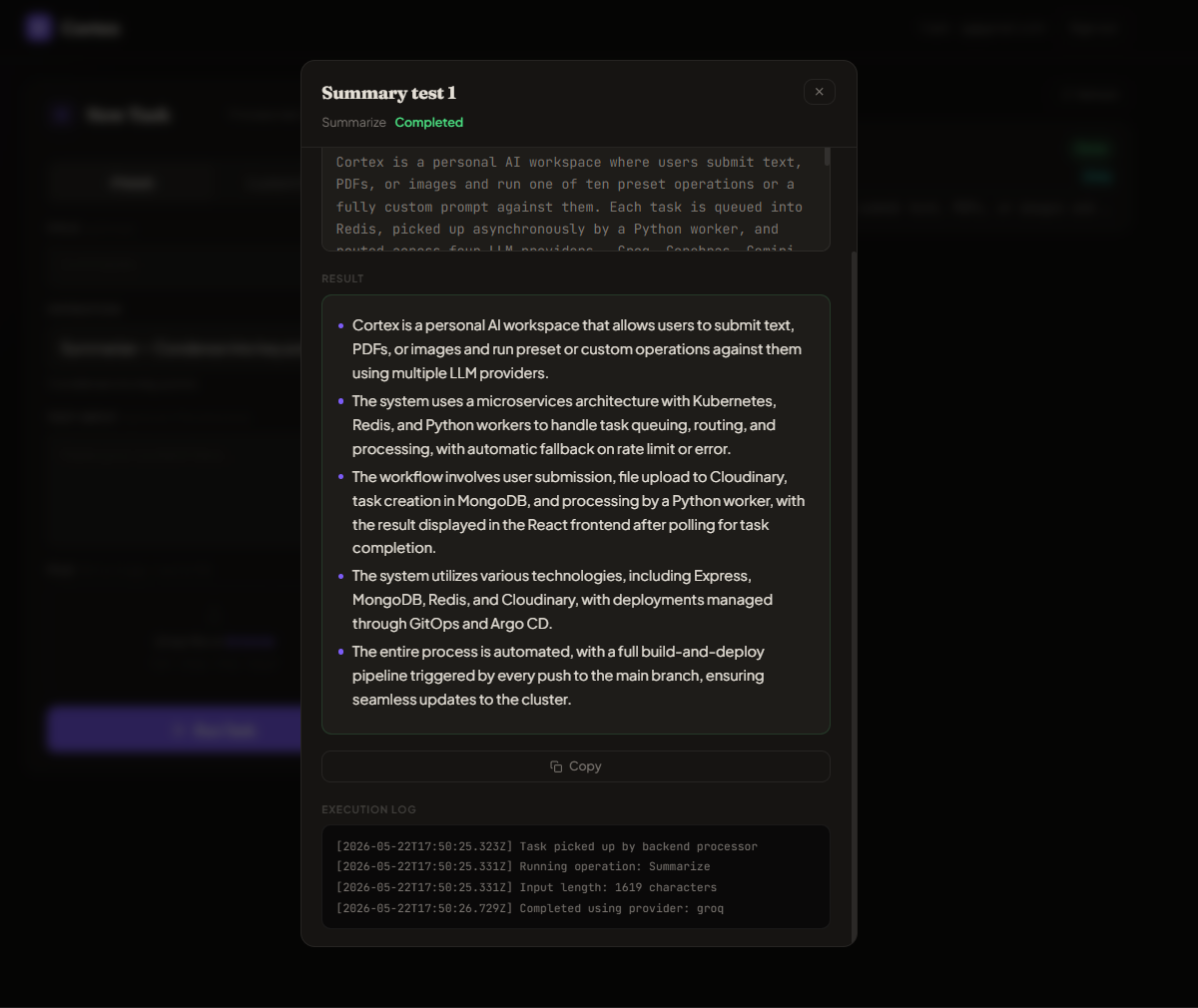
Cortex ships in two configurations. The live demo runs the simplified single-process topology to fit free-tier hosting constraints. The production-grade topology with a Python worker, Redis queue, Kubernetes, and Argo CD is documented in ARCHITECTURE.md and lives on the kubernetes branch.
React (Vercel) ──HTTPS──▶ Node + Express (Render free) ──▶ MongoDB Atlas M0
▲ │ │
│ SSE │ └──▶ Cloudinary (files)
│ tokens │
└───────────────┤
└─▶ LLM routing + streaming in-process
Groq · Cerebras · Gemini · OpenRouter
The Node backend hosts the LLM routing layer directly. Tasks are created synchronously, persisted to MongoDB as pending, and processed by an async function in the same process. As the upstream LLM streams tokens, the processor forwards each chunk through a per-task in-memory event bus to any subscribed SSE clients. The frontend renders tokens live via EventSource. Total cost: zero. Total credit cards required: zero.
Production Topology — kubernetes branch + cortex-infra
React (Nginx) ──▶ Node + Express ──┬──▶ MongoDB (StatefulSet, PVC)
│
└──▶ Redis (queue + pub/sub) ─┐
│
Python Worker × N ─────────────┘
│
└─▶ LLM routing + PyMuPDF extraction
Three Deployments (frontend, backend, worker), each behind a Service. Worker runs at 2 replicas by default, scaling out via replica count — brpop on Redis guarantees exactly-once delivery per task. Argo CD watches the infra repo with auto-sync, prune, and selfHeal enabled. GitHub Actions builds and pushes images on every commit to main, then sed-updates the image tags in the infra repo, which Argo CD picks up within minutes. Streaming uses Redis pub/sub on channel task_updates:{taskId} instead of the in-process bus, but the SSE endpoint and frontend EventSource code are unchanged.
The production topology is the one documented in ARCHITECTURE.md. Most architectural depth — worker scaling math, Redis failure recovery, multi-environment promotion — applies to this topology.
| Layer | Technology |
|---|---|
| Frontend | React 19, Vite, Tailwind CSS v4, native EventSource |
| Backend API | Node.js, Express 5, JWT (HS256), bcrypt, Multer, cookie-parser |
| Streaming | Server-Sent Events, per-task EventEmitter bus (main), Redis pub/sub (kubernetes) |
| Worker (K8s topology) | Python 3.11, pymongo, redis-py, PyMuPDF |
| LLM Providers | Groq (Llama 3.3 70B), Cerebras (GPT-OSS 120B), Google Gemini 2.5 Flash, OpenRouter (Llama 3.3 70B free) |
| Eval | js-yaml, custom scorers, GitHub Actions PR comment integration |
| File Storage | Cloudinary |
| Database | MongoDB 7 (Atlas M0 in live demo, self-hosted in K8s topology) |
| Queue (K8s topology) | Redis 7 |
| Containerization | Docker with multi-stage builds and non-root users |
| Orchestration | Kubernetes on Docker Desktop |
| GitOps | Argo CD with auto-sync, prune, and self-heal |
| CI/CD | GitHub Actions |
| Registry | Docker Hub |
| Hosting (live demo) | Vercel (frontend), Render (backend), MongoDB Atlas, Cloudinary |
Ten preset operations plus a fully custom prompt mode. Each preset has a hand-tuned system prompt that runs through the routing chain and streams output live.
| Operation | Description |
|---|---|
| Summarize | Condense input into 3 to 5 key bullet points |
| Extract Action Items | Identify all tasks and follow-ups with owners |
| Rewrite — Formal | Refine text to a professional tone |
| Rewrite — Casual | Make text warm and conversational |
| LinkedIn Post | Craft an engaging post with hook, body, and CTA |
| Draft Email | Write a polished email with subject and sign-off |
| Extract Key Decisions | Surface decisions made and open questions |
| Explain Simply | Simplify complex content for a 16-year-old reader |
| Tweet Thread | Convert ideas to a 5–8 tweet thread |
| Translate to Hindi | Natural Hindi translation in Devanagari |
| Custom Prompt | Provide your own system prompt for full control |
Each operation accepts text input, a PDF or image attachment (up to 10 MB), or both. PDFs are extracted via PyMuPDF and truncated to 80,000 characters before being passed to the LLM. Images are sent as base64 to Gemini's multimodal endpoint.
# from backend/
npm install
npm run dev
# from frontend/, in another terminal
npm install
npm run devSet MONGO_URI in backend/.env.local to either a local MongoDB or an Atlas free cluster. Set the four LLM API keys and Cloudinary credentials in the same file. Open http://localhost:5173.
Switch to the kubernetes branch first, then:
# Start MongoDB and Redis
docker compose up mongodb redis -d
# Backend
cd backend && npm install && npm run dev
# Worker (in another terminal)
cd worker && pip install -r requirements.txt && python worker.py
# Frontend (in another terminal)
cd frontend && npm install && npm run devOr run everything in containers:
docker compose up --buildbackend/.env.local (both topologies, but the K8s topology also needs REDIS_URL)
NODE_ENV=development
PORT=5000
APP_ENV=local
MONGO_URI=mongodb://admin:adminpass@localhost:27017/aitaskplatform?authSource=admin
JWT_SECRET=your_secret_here
JWT_EXPIRES_IN=7d
FRONTEND_URL=http://localhost:5173
CLOUDINARY_CLOUD_NAME=your_cloud_name
CLOUDINARY_API_KEY=your_api_key
CLOUDINARY_API_SECRET=your_api_secret
# LLM providers (live demo topology only — in K8s topology these go to the worker)
GROQ_API_KEY=your_groq_key
CEREBRAS_API_KEY=your_cerebras_key
GOOGLE_API_KEY=your_gemini_key
OPENROUTER_API_KEY=your_openrouter_key
NODE_ENV=production must be set on the deployed backend. The session cookie used by the SSE endpoint depends on this to flip secure and sameSite=none for the cross-origin Vercel-to-Render path.
All four LLM provider keys and Cloudinary are free to obtain — sign up at console.groq.com, cloud.cerebras.ai, aistudio.google.com, openrouter.ai, and cloudinary.com.
Manifests live in the companion repository cortex-infra. Apply them in order:
kubectl apply -f k8s/namespace.yaml
kubectl apply -f k8s/mongodb/
kubectl apply -f k8s/redis/
kubectl apply -f k8s/backend/
kubectl apply -f k8s/worker/
kubectl apply -f k8s/frontend/
kubectl apply -f k8s/ingress/See cortex-infra for Argo CD setup.
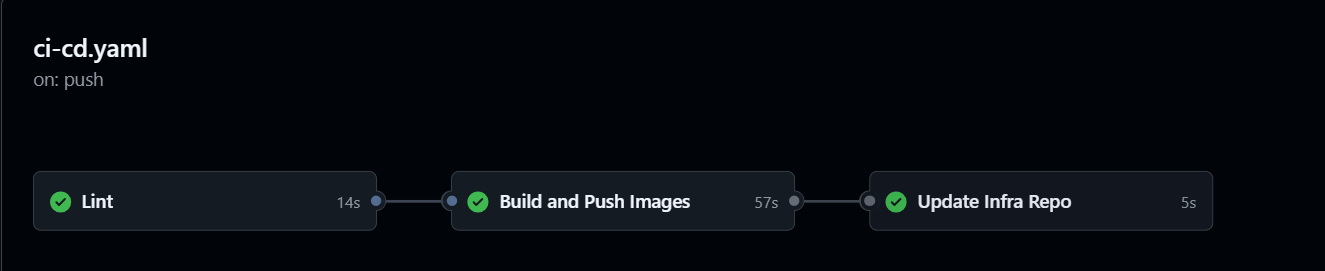
Every push to main triggers a three-stage GitHub Actions pipeline:
- Lint — ESLint runs on backend and frontend source. Failures block all subsequent stages.
- Build and Push — Docker images are built for all three services using multi-stage Dockerfiles and pushed to Docker Hub tagged with both
latestand the short commit SHA. - Update Infra Repo — The pipeline checks out cortex-infra using a stored secret token, updates the image tags in each deployment manifest via
sed, commits, and pushes. Argo CD detects the change within minutes and applies it to the cluster.
A separate LLM Eval workflow runs on every push and PR that touches the router, prompts, or eval cases. It executes in smoke mode (one case per operation, 10 cases total), posts a sticky PR comment with the per-operation pass rate, and fails the build if any operation drops more than 5 percentage points below baseline.
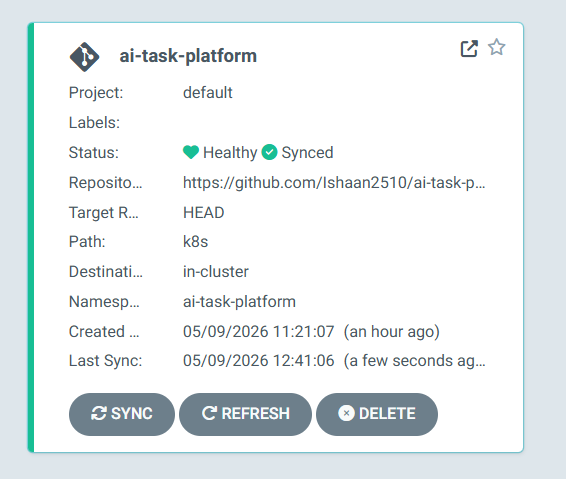
Argo CD runs in the argocd namespace and watches the k8s/ directory of the infra repository. Auto-sync, prune, and self-heal are all enabled. Any drift between the cluster and the declared manifests is automatically corrected.
See ARCHITECTURE.md for the full architecture document — LLM routing internals, real-time streaming layer, file processing pipeline, worker scaling, database indexing, Redis failure recovery, provider failure modes, prompt eval framework, and multi-environment deployment.
cortex/
├── backend/
│ ├── eval/
│ │ ├── cases/ 10 YAML files, 5 cases each
│ │ ├── scorers.js, runner.js, report.js
│ │ └── baseline.json
│ ├── src/
│ │ ├── config/ db.js, cloudinary.js, upload.js
│ │ ├── middleware/ auth.js (Bearer + cookie)
│ │ ├── models/ User.js, Task.js
│ │ ├── routes/ auth.js, tasks.js (incl. /stream SSE endpoint)
│ │ └── services/ llmRouter.js, operations.js, fileProcessor.js,
│ │ taskProcessor.js, eventBus.js
│ ├── Dockerfile
│ └── package.json
├── frontend/
│ ├── src/
│ │ ├── api/ axios.js, tasks.js
│ │ ├── components/ TaskCard.jsx, TaskForm.jsx, TaskModal.jsx (SSE consumer)
│ │ ├── context/ AuthContext.js, AuthProvider.jsx, useAuth.js
│ │ └── pages/ Landing.jsx, Login.jsx, Register.jsx, Dashboard.jsx
│ ├── nginx.conf
│ └── Dockerfile
├── docs/
│ └── dashboard.png, task-detail.png, argocd.png, pipeline.png
├── .github/workflows/
│ ├── lint-main.yaml
│ ├── eval.yaml prompt regression workflow
│ └── ci-cd.yaml kubernetes branch only
├── ARCHITECTURE.md
└── README.md
The kubernetes branch additionally includes worker/ (Python), docker-compose.yml, and the original Redis-backed routing in the Node backend.
Built by Ishaan Goswami — CS undergrad, PDEU + IIT Madras