- references : https://teamsparta.notion.site/Pytorch-1-7669d355f573451cbf5ebfeb74c584e7#3f0f21ddd7544decaa01385c0dfb90fb
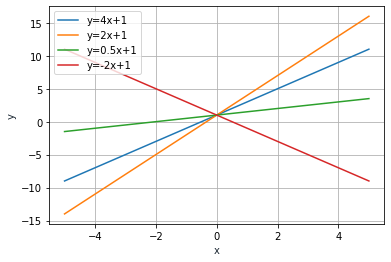
- 일차함수는 a는 기울기, b는 y절편(y축과 만나는 점)으로 구성된다
- a의 값과 그리고 b의 값에 따라서 직선의 위치는 달라집니다.
- 딥러닝에서는 w는 가중치(weight), b는 편항(bias)로 구성된다
- w의 값과 b의 값에 따라서 직선의 위치는 달라진다
- 시그마는 누계를 의미하므로 나눗셈을 추가하여 딥러닝에서는 평균을 수식으로 표현한다
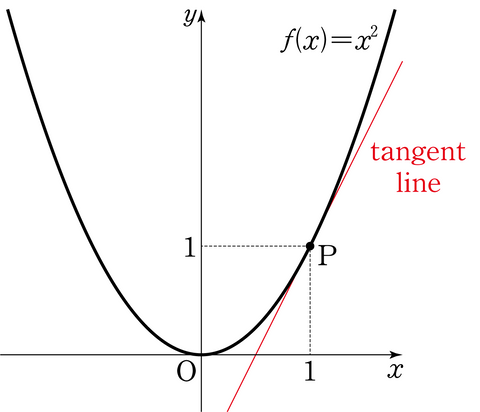
- 접선은 어떤 곡선을 한 점에서 만나며 그 점에서 곡선과 같은 방향, 즉 같은 기울기를 가지는 직선을 의미함
-
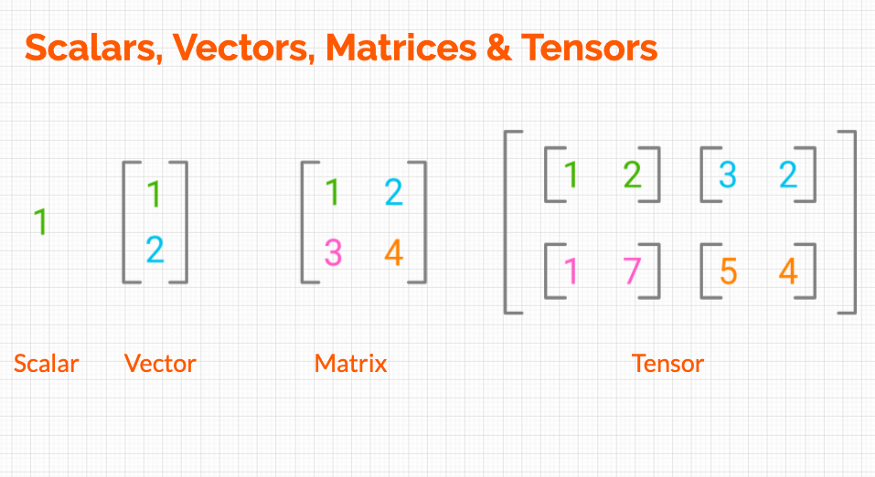
스칼라(Scalar)는 하나의 상수를 의미합니다.
var1 = torch.tensor([1]) -
add, sub, mul, div
torch.add(var1, var2)
-
벡터(Vector)는 상수가 두 개 이상 나열된 자료구조이다.
vector1 = torch.tensor([1, 2, 3]) -
N 차원 벡터라고 부른다면 여기서 N은 벡터 안에 숫자가 몇 개있는지를 의미합니다.
-
내적 연산(dot product)
torch.dot(vector1, vector2) -
a1 x b1 + a2 x b2 + a3 x b3를 우리는 벡터의 내적이라고 합니다.
-
행렬(Matrix)는 2개 이상의 벡터 값을 가지고 만들어진 값으로 행과 열의 개념을 가진 숫자의 나열입니다.
-
matrix1 = torch.tensor([[1, 2], [3, 4]]) -
행렬의 곱셈
torch.matmul(matrix1, matrix2)
-
일반적으로 훈련 데이터의 입력은 x_train, 훈련 데이터의 실제 정답은 y_train으로 표기합니다.
-
선형회귀의 가설은 1차 방정식을 통해 직선을 찾는것(데이터를 직선으로 표현할 수 있다)
H(x)=wx+b
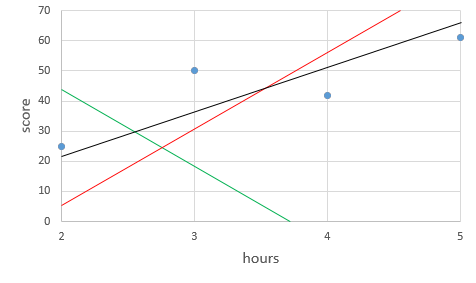
- 찾은 직선에서 떨어진 거리를 오차(error)라고 부르며, 이를 통해 최적의 직선을 찾음
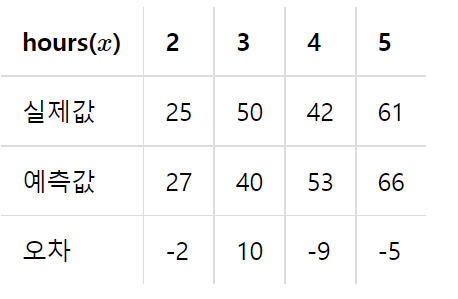
-
평균제곱오차(MSE) : 실제값에서 예측값을 뺀 오차값을 대상으로 제곱을 하여 전부 더하여 평균을 구함
-
MSE가 작을수록 직선이 훈련데이터를 잘 표현한다고 볼 수 있음
-
선형회귀에서는 cost function(loss)로 MSE를 사용함
-
cost function을 최소로 하기 위해 옵티마이저(Optimizer)를 사용함
-
적절한 w와 b를 찾는 과정을 학습(training)이라고 부름
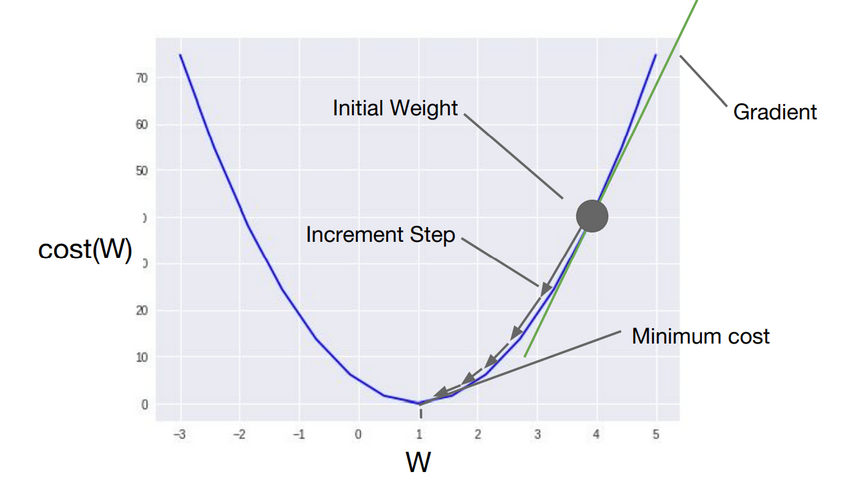
-
경사 하강법(Gradient Descent)은 임의의 초기값 W값을 정한 뒤에, 맨 아래 부분의 W값을 향해 점차 W의 값을 수정해나가는 것임
-
미분을 통해 접선의 기울기를 찾아내는것이 경사 하강법의 핵심 개념(직선은 수평일 때 기울기가 0이 됨)
-
즉, 훈련의 과정은 기울기가 0이 되는 방향으로 지속적으로 미분하여 이동시키는 것이다
-
학습률(learning rate)은 α(alpha)라고 불리기도 하며, 얼만큼의 폭으로 미분을 수행할지를 결정하는 것이다
-
학습률(learning rate)이 너무 크거나 작으면 학습에 문제가 발생한다
- weight와 bias를 0으로 초기화하고 학습을 통해 값이 변경되는 변수임을 명시
W = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)-
평균 구하기 :
torch.mean -
경사 하강법 :
optimizer = optim.SGD([W, b], lr=0.01)
optimizer.zero_grad()
cost.backward() # 미분하여 gradient 계산
optimizer.step() # W와 b를 업데이트-
독립 변수 x가 1개인 경우에는 단순 선형 회귀
-
독립 변수 x가 2개 이상인 경우를 우리는 다중 선형 회귀
-
learning rate : 10의 -5승
1e-5 -
행렬 곱셈 연산(벡터의 내적)
Dot Product를 통해 독립변수의 갯수가 많은 연산 처리
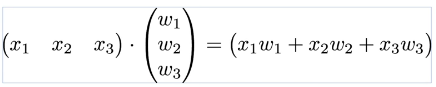
- 5x3 matrix 예시
H(X) = XW + B
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 80],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
# 가중치와 편향 선언
W = torch.zeros((3, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# 행렬 곱셈
hypothesis = x_train.matmul(W) + b
# cost 계산
cost = torch.mean((hypothesis - y_train) ** 2)- Pytorch 기본함수 사용버전 (선형회귀)
nn.Linear()
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])
model = nn.Linear(3,1) # input 1, ouput 1
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5)
prediction = model(x_train)
cost = F.mse_loss(prediction, y_train)