diff --git a/Project 4/README.md b/Project 4/README.md
index 4c5a27e8..6ac0339e 100644
--- a/Project 4/README.md
+++ b/Project 4/README.md
@@ -1,47 +1,1239 @@
-**The SPARQL Library of Buffalo**
+This file contains 14 level 7 katas, 11 level 6 katas, 7 level 5 katas, and 1 level 4 kata,
+for a total of 100 points.
+I have privileged low level katas for a number of reasons. First of all, I am myself a beginner in
+SPARQL, and I felt more comfortable in devising easier exercises, solutions and descriptions.
+Secondly, in the perspective of building a set of exercises to kickstart people into using
+SPARQL, I feel that providing a large range of basic exercises to train on is a good place
+to start. Incidentally, I believe this is a potential weakness for some of the languages in
+Codewars.
-[Codewars](https://www.codewars.com/dashboard) is a website designed to facilitate algorithmic training for various programming languages. Users supply problem statements and others provide coding solutions to those problems. For example, you might find a problem for Python such as:
+For the exercises I have written down a set of simplistic "toy" rdf schemas, usually employing
+an example.org URI. In order to make this file more readable, I will now list the schemas
+and will then refer to them in the exercises as the "people schema", "border schema", etc.
+Nevertheless, when we upload them to Codewars, I believe that the rdf schemas should be entirely
+written down for each exercise.
-```
-Define a function that returns the length of a given string.
-```
+Incidentally, OpenAI/ Chatgpt was used to help with a lot of these questions. I believe it
+might be interesting to provide an explanation of how that was done for the purposes of
+explaining the relation between AI and SPARQL. I will write a report on that in the next days.
-With a solution like:
-```
-def length_of_string(s):
- return len(s)
-```
-
-Codewars is not limited to traditional programming languages like Python, but also facilitates training for languages like SQL. As you have learned, SQL and SPARQL are both query languages, but what might surprise you is that there is currently no option for training SPARQL in Codewars. This project will go some way to remedy that.
+Traveler schema:
-For this project, you will be tasked with constructing SPARQL problems for the codewars site.
+ex:travelers a rdfs:Class .
+ex:has_name a rdf:Property;
+ rdfs:domain ex:Traveler ;
+ rdfs:range xsd:string .
+ex:has_country a rdf:Property;
+ rdfs:domain ex:Traveler ;
+ rdfs:range xsd:string .
+ex:has_id a rdf:Property ;
+ rdfs:domain ex:Traveler ;
+ rdfs:range xsd:string .
-```
-Note #1: Completion of this task will not require you to actually have your SPARQL problems successfully posted to codewars. Adding problems to codewars takes more time than we have for this project. Additionally, you are only allowed to add propose problems to codewars if you have a certain amount of experience (specifically, you need 300 of what they call 'honor points', which is acquired by solving problems). At some point, assuming you permit it, I will post your problems to codewars (giving you credit of course).
-Note #2: The potential for this project to directly impact the ontology community is clear. SPARQL can be challenging, and there are few opportunities for drill practice like this.
-Note #3: You will not be required to learn a programming language, though you will likely need to expand your comfort with computer science jargon; if you hit a wall, ask your peers for help; if the wall persists, ask me.
-Note #4: Codewars provides a guidebook - https://docs.codewars.com/authoring/tutorials/create-first-kata/ - for creating problems; I strongly encourage you to read it, since the standard provided there is how I will be evaluating success.
-```
-**Assignment Details**
+Trips schema:
-Problems on Codewars are ranked in terms of difficulty. The lowest "kata" - 8 - indicates a rather easy problem, while the highest kata - 1 - indicates a very challenging problem.
-For our purposes, harder kata will be worth more points than easier kata, and you are required to submit enough kata to acquire 100 points according to the following point system:
+ex2:Trip a rdfs:Class .
- | **kata** | **points** |
- | ------------- | ------------- |
- | 1 | 35 |
- | 2 | 25 |
- | 3 | 20 |
- | 4 | 10 |
- | 5 | 5 |
- | 6 | 3 |
- | 7 | 2 |
- | 8 | 0 |
+ex2:has_traveler a rdf:Property ;
+ rdfs:domain ex2:Trip ;
+ rdfs:range ex:travelers .
-You're probably thinking, "why would I submit a level 8 kata if they're not worth any points?" Great question. Because everyone had to submit at least one level 8 kata. Otherwise, you're permitted to submit kata in any distribution you choose. For example, you might submit 2 problems for kata one (70 points), one for kata 3 (20 points), one for kata 4 (10 points), and one for kata 8 (0 points but required).
+ex2:has_country a rdf:Property ;
+ rdfs:domain ex2:Trip ;
+ rdfs:range xsd:string .
-It is your responsibility and the responsibility of your peers reviewing your submission in PR to determine whether your submission is ranked appropriately. In the event that consensus is reached that your kata is ranked inappropriately, you must work with your peers to revise the submission so that it is either more or less challenging, accordingly. You are not permitted to submit new problems with different strengths after PRs are open, but must instead revise your PRs. So, think hard about how challenging your submission is.
+Products schema:
+@prefix ex: .
-There is one other option for those desiring a different sort of challenge. If you provide alongside your SPARQL submission a translation of the same problem into SQL, complete with documentations, solution, etc. then you may receive half points extra at that kata level (rounded up). For example, if you submit a SPARQL problem that is kata rank 1 and also submit a SQL version of that same problem, you will receive 35+18=53 points.
+ex:Product rdf:type rdfs:Class .
+ ex:id rdf:type rdf:Property ;
+ rdfs:domain ex:Product ;
+ rdfs:range xsd:string .
+
+ex:has_name rdf:type rdf:Property ;
+ rdfs:domain ex:Product ;
+ rdfs:range xsd:string .
+
+ex:has_isbn rdf:type rdf:Property ;
+ rdfs:domain ex:Product ;
+ rdfs:range xsd:string .
+
+ex:has_price rdf:type rdf:Property ;
+ rdfs:domain ex:Product ;
+ rdfs:range xsd:decimal .
+
+ex:belongs_to rdf:type rdf:Property ;
+ rdfs:domain ex:Product ;
+ rdfs:range ex2:Company .
+
+ex:has_company_id rdf:type rdf:Property ;
+ rdfs:domain ex:Product ;
+ rdfs:range xsd:string .
+
+ex:has_company_name rdf:type rdf:Property ;
+ rdfs:domain ex:Product ;
+ rdfs:range xsd:string .
+
+Company schema:
+
+@prefix ex2: .
+
+
+ex2:Company rdf:type rdfs:Class .
+ex2:id rdf:type rdf:Property ;
+ rdfs:domain ex2:Company ;
+ rdfs:range xsd:string .
+
+ex2:has_name rdf:type rdf:Property ;
+ rdfs:domain ex2:Company ;
+ rdfs:range xsd:string .
+
+People schema:
+
+@prefix people: .
+
+people: a rdfs:Class;
+ rdfs:label "Person";
+ rdfs:subClassOf owl:Thing.
+
+people:id a owl:DatatypeProperty;
+ rdfs:comment "The unique identifier of a person.";
+ rdfs:domain people:Person;
+ rdfs:range xsd:integer.
+
+people:name a owl:DatatypeProperty;
+ rdfs:label "Name";
+ rdfs:comment "The name of a person.";
+ rdfs:domain people:Person;
+ rdfs:range xsd:string.
+
+people:age a owl:DatatypeProperty;
+ rdfs:comment "The age of a person.";
+ rdfs:domain people:Person;
+ rdfs:range xsd:integer.
+
+Card store schema:
+
+@prefix ex: .
+ex:Department rdf:type rdfs:Class ;
+ rdfs:label "Department" .
+
+ex:Sale rdf:type rdfs:Class ;
+ rdfs:label "Sale" .
+
+ex:hasDepartment rdf:type rdf:Property ;
+ rdfs:domain ex:Sale ;
+ rdfs:range ex:Department ;
+
+ex:departmentId rdf:type rdf:Property ;
+ rdfs:domain ex:Sale ;
+ rdfs:range xsd:int ;
+
+ex:name rdf:type rdf:Property ;
+ rdfs:domain ex:Department, ex:Sale ;
+ rdfs:range xsd:string ;
+
+ex:price rdf:type rdf:Property ;
+ rdfs:domain ex:Sale ;
+ rdfs:range xsd:float ;
+
+ex:cardName rdf:type rdf:Property ;
+ rdfs:domain ex:Sale ;
+ rdfs:range xsd:string ;
+
+ex:cardNumber rdf:type rdf:Property ;
+ rdfs:domain ex:Sale ;
+ rdfs:range xsd:string ;
+
+ex:transactionDate rdf:type rdf:Property ;
+ rdfs:domain ex:Sale ;
+ rdfs:range xsd:date ;
+
+Modified-dbpedia schema:
+
+@prefix dbpedia:
+@prefix dbpprop:
+dbpedia:continent rdf:type rdfs:Class
+ rdfs:label "A continent";
+ rdfs:subClassOf owl:Thing.
+
+dbpedia:country rdf:type rdfs:Class
+ rdfs:label "A country";
+ rdfs:subClassOf owl:Thing.
+
+dbpprop:has_continent a rdf:Property;
+ rdfs:domain dbpedia:country;
+ rdfs:range dbpedia:continent.
+
+dbpprop:has_capital a rdf:Property;
+ rdfs:domain dbpedia:country;
+ rdfs:range dbpedia:capital.
+
+dbpprop:has_name a rdf:Property;
+ rdfs:domain dbpedia:resource;
+ rdfs:range xsd:string.
+
+Events schema:
+
+@prefix ex: .
+
+ex:Event rdf:type rdfs:Class ;
+ rdfs:label "Event" .
+
+ex:createdAt rdf:type rdf:Property ;
+ rdfs:domain ex:Event ;
+ rdfs:range xsd:dateTime ;
+ rdfs:label "Created At" .
+
+ex:description rdf:type rdf:Property ;
+ rdfs:domain ex:Event ;
+ rdfs:range xsd:string ;
+ rdfs:label "Description" .
+
+Bookshop schema:
+
+@prefix dc:
+@prefix ex:
+
+
+ex:Book a rdfs:Class .
+ex:author a rdf:Property ;
+ rdfs:domain ex:Book ;
+ rdfs:range xsd:string .
+
+ex:copies_sold a rdf:Property ;
+ rdfs:domain ex:Book ;
+ rdfs:range xsd:integer .
+
+dc:title a rdf:Property ;
+ rdfs:domain ex:Book ;
+ rdfs:range xsd:string .
+
+Book review schema:
+
+ex:Review rdf:type rdfs:Class ;
+ rdfs:label "Review" .
+
+ex:genre rdf:type rdf:Property ;
+ rdfs:label "Genre" ;
+ rdfs:range ex:Genre .
+
+ex:publisher rdf:type rdf:Property ;
+ rdfs:label "Publisher" ;
+ rdfs:range ex:Publisher .
+
+ex:reviewer rdf:type rdf:Property ;
+ rdfs:label "Reviewer" ;
+ rdfs:range ex:Person .
+
+ex:rating rdf:type rdf:Property ;
+ rdfs:label "Rating" ;
+ rdfs:range xsd:integer .
+
+ex:Person rdf:type rdfs:class ;
+ rdfs:label "Person”.
+
+Person schema:
+
+@prefix ex: .
+
+ex:Person a rdfs:Class .
+
+ex:hasPrefix a rdf:Property ;
+ rdfs:domain ex:Person ;
+ rdfs:range xsd:string .
+ex:hasFirstName a rdf:Property ;
+ rdfs:domain ex:Person ;
+ rdfs:range xsd:string .
+ex:hasLastName a rdf:Property ;
+ rdfs:domain ex:Person ;
+ rdfs:range xsd:string .
+ex:hasSuffix a rdf:Property ;
+ rdfs:domain ex:Person ;
+ rdfs:range xsd:string .
+
+Rental schema:
+
+@prefix xsd:
+@prefix rdf:
+@prefix payment:
+@prefix staff:
+@prefix customer:
+@prefix rental:
+
+payment:Payment rdf:type rdfs:Class.
+
+staff:Staff rdf:type rdfs:Class.
+
+customer:Customer rdf:type rdfs:Class.
+
+rental:Rental rdf:type rdfs:Class.
+
+payment:madeBy rdf:type rdf:Property;
+ rdfs:domain payment:Payment;
+ rdfs:range staff:Staff.
+
+payment:belongsTo rdf:type rdf:Property;
+ rdfs:domain payment:Payment;
+ rdfs:range rental:Rental.
+
+payment:paidBy rdf:type rdf:Property;
+ rdfs:domain payment:Payment;
+ rdfs:range customer:Customer.
+
+staff:id rdf:type rdf:Property;
+ rdfs:domain staff:Staff;
+ rdfs:range xsd:integer.
+
+rental:id rdf:type rdf:Property;
+ rdfs:domain rental:Rental;
+ rdfs:range xsd:integer.
+
+customer:id rdf:type rdf:Property;
+ rdfs:domain customer:Customer;
+ rdfs:range xsd:integer.
+
+payment:amount rdf:type rdf:Property;
+ rdfs:domain payment:Payment;
+ rdfs:range xsd:decimal.
+
+payment:payment_date rdf:type rdf:Property;
+ rdfs:domain payment:Payment;
+ rdfs:range xsd:dateTime.
+
+Sales schema:
+
+@prefix ex: .
+
+ex:Product rdf:type rdfs:Class .
+ex:Sale rdf:type rdfs:Class .
+ex:SalesDetail rdf:type rdfs:Class .
+
+ex:id rdf:type rdf:Property ;
+ rdfs:domain ex:Product, ex:Sale, ex:SalesDetail ;
+ rdfs:range xsd:int .
+
+ex:name rdf:type rdf:Property ;
+ rdfs:domain ex:Product ;
+ rdfs:range xsd:string .
+
+ex:price rdf:type rdf:Property ;
+ rdfs:domain ex:Product ;
+ rdfs:range xsd:decimal .
+
+ex:date rdf:type rdf:Property ;
+ rdfs:domain ex:Sale ;
+ rdfs:range xsd:date .
+
+ex:sale_id rdf:type rdf:Property ;
+ rdfs:domain ex:SalesDetail ;
+ rdfs:range xsd:int .
+
+ex:product_id rdf:type rdf:Property ;
+ rdfs:domain ex:SalesDetail ;
+ rdfs:range xsd:int .
+
+ex:count rdf:type rdf:Property ;
+ rdfs:domain ex:SalesDetail ;
+ rdfs:range xsd:int .
+
+---------------------------------------------------------------------------------------------
+
+Here are the exercies. Apologies in advance for the ones where I may have forgotten to specify
+the schema we are querying.
+
+Description Level 7:
+
+This was originally a level 8 kata, but for our purposes should be at least a level 7:
+
+Taken from “On the Canadian Border (SQL for Beginners #2)”, a SQL exercise on Codewars from https://www.codewars.com/users/MaikelNabil
+
+Description:
+
+You are a border guard sitting on the Canadian border. You were given a list of travelers who have arrived at your gate today. You know that American, Mexican, and Canadian citizens don't need visas, so they can just continue their trips. You don't need to check their passports for visas! You only need to check the passports of citizens of all other countries!
+
+Select names, and countries of origin of all the travelers, excluding anyone from Canada, Mexico, or The US.
+
+Starting info for the traveler graph:
+
+ex:travelers a rdfs:Class .
+ex:has_name a rdf:Property;
+ rdfs:domain ex:Traveler ;
+ rdfs:range xsd:string .
+ex:has_country a rdf:Property;
+ rdfs:domain ex:Traveler ;
+ rdfs:range xsd:string .
+ex:has_id a rdf:Property ;
+ rdfs:domain ex:Traveler ;
+ rdfs:range xsd:string .
+
+
+NOTE: The United States is written as 'USA' in the table.
+
+
+
+Reference solution:
+
+@prefix ex:
+SELECT DISTINCT ?name ?country
+WHERE {
+?traveler ex:has_name ?name ;
+ ex:has_country ?country .
+FILTER (?country != "USA" && ?country != "Mexico" && ?country != "Canada")
+}
+
+
+Level 8 version:
+
+You are a border guard sitting on the Canadian border. You were given a list of travelers who have arrived at your gate today.
+
+Select countries of origin of all the travelers, without repeating them.
+
+Traveler graph
+
+
+Reference solution:
+
+prefix ex:
+SELECT DISTINCT ?country
+WHERE {
+?traveler ex:has_country ?country .
+}
+
+Description level 6:
+
+Take the previous country schema. You are now asked to retrieve the name of the visitor that has gone to most countries, and the number of countries they have visited. Results should be offered in two columns called ?travelername and ?numCountries
+
+Reference solution:
+
+@prefix ex:
+@prefix ex2:
+
+SELECT ?travelerName (COUNT(DISTINCT ?country) AS ?numCountries) WHERE {
+ ?traveler a ex:Traveler ;
+ ex:has_name ?travelerName .
+ ?trip a ex2:Trip ;
+ ex2:has_country ?country ;
+ ex2:has_traveler ?traveler .
+} GROUP BY ?travelerName
+ ORDER BY DESC(?numCountries)
+ LIMIT 1
+
+
+
+Description level 6:
+
+Take now the previous schema and consider another schema called trips, whose purpose is to store information about the trips that people crossing the border have taken.
+
+Notice that ex2:has_country and ex:has_country are different properties, and they mean different things.
+You are now asked to retrieve a list of all the travelers’ names, alongside with a list of how many trips they have taken and to which country. You need to build a result table that has a ?name variable, a ?country variable and a ?numTrips variable that sorts out how many times each traveler went to a country. Also, you want to have a column for ?id
+
+Reference solution:
+ SELECT ?id ?name ?country (COUNT(?trip) AS ?numTrips)
+WHERE {
+ ?trip ex2:has_traveler ?traveler ;
+ ex2:has_country ?country .
+ ?traveler ex:has_id ?id ;
+ ex:has_name ?name .
+}
+GROUP BY ?id ?name ?country
+
+Description level 7
+Take the previous schema, with both ex1 and ex2. You are now asked to retrieve a list of all the traveler names and places they travelled to. The result should be stored in two columns called ?travelerName and ?tripCountry. Also make sure that the result doesn’t have repeated entries.
+
+Reference solution:
+
+@prefix ex:
+@prefix ex2:
+
+SELECT DISTINCT ?travelerName ?tripCountry
+WHERE {
+ ?traveler ex:has_name ?travelerName ;
+ ex:has_country ?travelerCountry .
+ ?trip ex2:has_traveler ?traveler ;
+ ex2:has_country ?tripCountry .
+}
+
+
+Description Level 7
+
+Starting from the traveler schema, you are now asked to retrieve the five countries that
+have had the higher number of visitors, and order them in descending order. The result
+should be stored in two columns, ?country and ?numVisits.
+
+Reference solution:
+
+@prefix ex:
+@prefix ex2:
+
+SELECT ?country (COUNT(?traveler) AS ?numVisits) WHERE {
+ ?trip a ex2:Trip ;
+ ex2:has_country ?country .
+ ?traveler a ex:Traveler ;
+ ex2:has_traveler ?trip .
+} GROUP BY ?country
+ ORDER BY DESC(?numVisits)
+ LIMIT 5
+
+
+Description Level 6
+
+Take the previous schema. You are now tasked with retrieving a list of the people who
+have visited the same country (at least) twice in the same year. You just need to sort your results in a
+single column called ?traveler.
+
+Reference solution:
+
+?SELECT ?traveler
+WHERE {
+ ?trip1 a ex2:Trip ;
+ ex2:has_traveler ?traveler ;
+ ex2:has_country ?country .
+ ex2:has_year ?year .
+ ?trip2 a ex2:Trip ;
+ ex2:has_traveler ?traveler ;
+ ex2:has_country ?country .
+ ex2:has_year ?year .
+ FILTER (?trip1 != ?trip2)
+}
+GROUP BY ?traveler
+
+
+Description Level 7
+
+Level 7 kata called [SQL Basics: Simple JOIN] (https://www.codewars.com/kata/5802e32dd8c944e562000020) from [jhoffner](https://www.codewars.com/users/jhoffner)
+
+For this challenge you need to create a simple SELECT statement that will return all columns from the ex:Product class, and join to the ex2:Company table so that you can return the company name. The result will then need to show the following data:
+
+?id ?name ?isbn ?companyId ?price ?companyName
+
+
+The rdf schema you are querying is the product and the company schema.
+
+
+
+Reference solution:
+
+@prefix ex:
+@prefix ex2:
+SELECT ?id ?name ?isbn ?companyId ?price ?companyName
+WHERE {
+?product ex:id ?id ;
+ ex:has_name ?name ;
+ ex:has_isbn ?isbn ;
+ ex:has_company_id ?companyId ;
+ ex:has_price ?price ;
+ ex:has_company_name ?companyName .
+?company ex2:id ?companyId ;
+ ex2:has_name ?companyName .
+}
+
+
+Description level 7
+
+Against the same rdf graph as before, you are now asked to retrieve the average price of products for each company. The resulting query should then have columns ?companyName and ?averagePrice
+
+Reference solution:
+
+@prefix ex:
+@prefix ex2:
+
+SELECT ?companyName (AVG(?price) AS ?avgPrice)
+WHERE {
+ ?product ex:has_price ?price ;
+ ex:belongs_to ?company .
+ ?company ex2:has_name ?companyName .
+}
+GROUP BY ?companyName
+
+
+Description (Level 5)
+
+Take the products and companies graphs. You are now asked to retrieve the companies that
+sell products that match a certain pattern in their name. In this case, their name must
+start with “Product".You also need to count how many of these
+products are sold by each company, and also retrieve only companies that sell at least 2 of
+compatible matching products. Finally, order the result (which should have a column called
+?companyName and one called ?productCount) by descending order.
+
+Reference solution:
+
+@prefix ex:
+@prefix ex2:
+
+SELECT ?companyName (COUNT(?product) AS ?productCount)
+WHERE {
+ ?product ex:has_price ?price ;
+ ex:belongs_to ?company ;
+ ex:has_name ?productName .
+ ?company ex2:has_name ?companyName .
+ FILTER regex(?productName, "^Product")
+}
+GROUP BY ?companyName
+HAVING (COUNT(?product) > 1)
+ORDER BY DESC(?productCount)
+
+
+Description Level 6:
+
+Starting from the previous schema, you are asked to retrieve the name of all the departments that sell a product that has the ISBN “12345”. You are then asked to calculate the sum of all the revenue made by each company.
+
+Reference solution:
+
+@prefix ex:
+@prefix ex2:
+
+SELECT ?companyName (SUM(?price) AS ?revenue)
+WHERE {
+ ?product ex:has_isbn "1234567890" ;
+ ex:belongs_to ?company ;
+ ex:has_price ?price .
+ ?company ex2:has_name ?companyName ;
+ ex2:id ?companyId .
+}
+GROUP BY ?companyName
+
+Description level 7:
+
+Source: Level 8 Simple MAX/MIN from matt c (https://www.codewars.com/kata/581113dce10b531b1d0000bd)
+
+For this challenge you need to create a simple MIN / MAX statement that will return the
+Minimum and Maximum ages out of all the people.
+You are querying the people schema.
+
+Reference solution:
+
+@prefix rdf: .
+@prefix rdfs: .
+@prefix xsd: .
+@prefix people: .
+SELECT (MIN(?age) AS ?age_min) (MAX(?age) AS ?age_max)
+WHERE {
+?person people:age ?age .
+}
+
+
+Description level 7:
+
+Starting from the people schema, you are asked to retrieve a list of all the people who
+are older than 30 years old and whose first name is “John”. Notice that you don’t want to
+accidentally include people whose last name is something like “Johnson”.
+
+Reference solution:
+
+@prefix rdf:
+@prefix rdfs:
+@prefix xsd:
+@prefix people:
+
+SELECT ?person ?name ?age ?address ?city
+WHERE {
+ ?person rdf:type people:Person .
+ ?person people:name ?name .
+ ?person people:age ?age .
+ FILTER (?age > 30)
+ FILTER (strstarts(?name, "John"))
+
+Description Level 7:
+
+Take the people schema, and add a property
+
+people:address a owl:ObjectProperty;
+ rdfs:label "Address";
+ rdfs:domain people:Person;
+ rdfs:range xds:string.
+
+You are now asked to retrieve the list of all the people who do not have a stable address, i.e. people for whom we didn’t store a specific address.
+
+@prefix rdf:
+@prefix rdfs:
+@prefix xsd:
+@prefix people:
+
+SELECT ?person ?name ?age
+WHERE {
+ ?person rdf:type people:Person .
+ ?person people:name ?name .
+ ?person people:age ?age .
+ FILTER NOT EXISTS {
+ ?person people:address ?address .
+ }
+}
+
+Description level 5:
+
+Take the people schema and add a property
+
+
+people:city a owl:DatatypeProperty;
+ rdfs:label "The city where a person lives or has lived in";
+ rdfs:domain people:Person;
+ rdfs:range xsd:string.
+
+You are now asked to retrieve the list of all the people. In addition to that,
+there is a specific kind of people who have lived in at least two cities.
+You are asked to produce a column of strings called ?cities which is a list of all of the
+cities where these people have lived. Remember that the name of a city could appear twice,
+and we do not want to count duplicates.
+Notice that you still should also get names for all the other people too in a column called
+?name, as well as a column called ?age. Finally, notice that we are only interested in
+individuals who are older than 18.
+
+Reference solution:
+
+SELECT ?name ?age (GROUP_CONCAT(DISTINCT ?city; SEPARATOR=",") as ?cities)
+WHERE {
+ ?person rdf:type people:Person ;
+ people:name ?name ;
+ people:age ?age .
+ OPTIONAL {
+ ?person people:address ?address .
+ ?person people:city ?city .
+ }
+ FILTER (?age >= 18)
+}
+GROUP BY ?name ?age
+HAVING (COUNT(DISTINCT ?city) >= 2)
+ORDER BY ?name
+
+Description: I am trying to make a level 5 with some math I don’t know anything about:
+
+You are asked to retrieve from the people schema as before the people whose age equals the
+median of the dataset. You are using the people schema.
+
+Reference solution:
+
+@prefix people:
+SELECT DISTINCT ?person
+WHERE {
+{
+SELECT
+(AVG(?age) AS ?median)
+WHERE {
+?person people:age ?age .
+}
+GROUP BY ?person
+ORDER BY ?median
+LIMIT 2
+OFFSET 1
+}
+?person people:age ?age .
+FILTER (?age = ?median)
+}
+
+(Limit 2 is used to take the two bigger medians, Order By is used to have the bigger
+as second, offset is used to skip the first result)
+
+
+Original source is Level 8 simple DISTINCT from matt c https://www.codewars.com/kata/58111670e10b53be31000108/train/sql
+
+Description (Level 8)
+
+From the previous rdf schema (no need to copy it here, I don’t want to clog the Google Doc), select all the distinct ages recorded in the data.
+
+Reference solution:
+
+SELECT DISTINCT ?age
+WHERE {
+?person people:age ?age .
+}
+
+
+Taken from Level 7 Simple GROUP BY from matt c
+https://www.codewars.com/kata/58111f4ee10b5301a7000175/train/sql
+
+Description (Level 7 version of the previous)
+
+From the people rdf schema, select all the distinct ages recorded in the data, alongside with how many people have them
+
+Reference solution:
+
+SELECT DISTINCT ?age (COUNT(?person) AS ?num_people)
+WHERE {
+?person people:age ?age .
+}
+GROUP BY ?age
+
+
+Description Level 6
+
+Taken from Level 6 simple EXISTS from matt c
+https://www.codewars.com/kata/58113a64e10b53ec36000293/train/sql
+
+For this challenge you need to create a SELECT statement that will contain data about
+departments that had a sale with a price over 98.00 dollars. This SELECT statement will have
+to use an EXISTS to achieve the task.
+
+You are using the card store schema.
+
+Reference solution:
+
+@prefix ex:
+
+SELECT ?name ?id
+WHERE {
+ ?dept a ex:Department ;
+ ex:name ?name ;
+ ex:departmentId ?id .
+ FILTER EXISTS {
+ ?sale a ex:Sale ;
+ ex:hasDepartment ?dept ;
+ ex:price ?price .
+ FILTER (?price >= 98.0)
+ }
+}
+
+
+Level 6 Description:
+
+Source is level 6 kata simple JOIN and RANK from matt.c
+https://www.codewars.com/kata/58094559c47d323ebd000035/solutions
+
+Add to the card store schema the property
+
+
+ex:people_id a owl:ObjectProperty ;
+ rdfs:comment "The ID of the person associated with the sale." ;
+ rdfs:domain ex:Sale ;
+ rdfs:range xsd:integer ;
+
+This property refers to the :people RDF schema we have seen in previous exercise. Again, no need to copy it on the Google Doc. Now, retrieve a list of all the people and rank them on the basis of how much they spend as recorded by the Sale resource. Notice that you need to use the RANK function.
+
+Reference solution
+
+@prefix ex:
+@prefix people: .
+@prefix rdf:
+@prefix xsd:
+SELECT ?id ?name
+(COUNT(?sale) AS ?sale_count)
+(RANK() OVER(ORDER BY DESC(COUNT(?sale))) AS ?sale_rank)
+WHERE {
+?person rdf:type people:Person ;
+ people:id ?id ;
+ people:name ?name .
+?sale rdf:type ex:Sale ;
+ ex:people_id ?id .
+}
+GROUP BY ?id ?name
+ORDER BY DESC(?sale_count)
+
+
+Description level 6:
+
+Start from the card store schema. You are now requested to find where people have been
+shopping, i.e. in which department. List the persons by id.
+
+Reference Solution:
+
+SELECT ?name ?id
+WHERE {
+?person rdf:type people:Person ;
+ people:id ?id ;
+?sale rdf:type ex:Sale ;
+ ex:people_id ?id .
+ ex:departmentID ?dept_id
+?department ex:name ?name
+}
+
+
+Description Level 7:
+
+Taken from level 7 kata Countries capitals for trivia night from MaikeINabil
+https://www.codewars.com/kata/5e5f09dc0a17be0023920f6f
+
+Your friends told you that if you keep coding on your computer, you are going to hurt your
+eyes. They suggested that you go with them to trivia night at the local club.
+
+Once you arrive at the club, you realize the true motive behind your friends' invitation.
+They know that you are a computer nerd, and they want you to query the `countries` RDF schema and get the answers to the trivia questions.
+
+The first question: from the African countries that start with the character E, get the
+names of their capitals ordered alphabetically.
+In order to do so, you go to dbpedia and decide to make SPARQL queries to answer questions.
+
+- You should only give the names of the capitals. Any additional information is just noise
+- If you get more than 3, you will be kicked out, for being too smart
+
+You are querying the modified-dbpedia schema.
+
+
+Reference Solution:
+
+@prefix dbpedia:
+@prefix dbpprop:
+SELECT ?capital
+WHERE {
+?country dbpprop:has_continent dbpedia:Africa> ;
+ dbpprop:capital ?capital.
+ dbprop:has_name ?countryname
+FILTER(STRSTARTS(?countryname, "E"))
+}
+ORDER BY ?capital
+LIMIT 3
+
+
+Level 6 description:
+
+Starting from the modified-dbpedia schema you are now requested to give all the countries in Europe that have a capital whose name starts with “R”.
+
+Reference solution:
+
+@prefix dbpedia:
+@prefix dbpprop:
+SELECT ?country
+WHERE {
+?country dbpprop:has_continent dbpedia:Europe> ;
+ dbpprop:capital ?capital.
+?capital dbprop:has_name ?capitalname
+FILTER(STRSTARTS(?capitalname, "R"))
+}
+
+
+Description level 5:
+Level 5 kata from jhoffner GROUP BY day,
+https://www.codewars.com/kata/5811597e9d278beb04000038/train/sql
+
+There is an `events` RDF graph used to track different key activities taken on a website.
+For this task you need to:
+
+- find the entries whose `name` equals `"trained"`
+- group them by the `day` the activity happened (the date part of the `created_at`
+timestamp) and their `description`'s
+- the 2 aforementioned fields should be returned together with the number of grouped
+entries in a column called `count`
+- the result should also be sorted by `day`
+
+You are querying the events table
+
+Reference solution:
+
+SELECT ?day ?description (COUNT(* ) AS ?count)
+WHERE {
+ ?event rdf:type ex:Event ;
+ ex:createdAt ?created_at ;
+ ex:description ?description .
+ FILTER (CONTAINS(lcase(str(?description)), "trained"))
+ # Extract the day from the date
+ BIND(day(?created_at) AS ?day)
+}
+GROUP BY ?day ?description
+
+Level 7 description:
+Level 7 kata from MaikeINabil Best-selling books
+https://www.codewars.com/kata/591127cbe8b9fb05bd00004b/train/sql
+
+You work at a bookstore. It's the end of the month, and you need to find out the 5 bestselling books at your store. Use a select statement to list names, authors, and number of copies sold of the 5 books which were sold most.
+
+You are using the bookshop schema.
+
+Reference solution:
+
+@prefix rdf:
+@prefix ex:
+@prefix dc:
+
+SELECT ?name ?author ?copies_sold
+WHERE {
+ ?book rdf:type ex:Book ;
+ dc:title ?name ;
+ ex:author ?author ;
+ ex:copies_sold ?copies_sold .
+}
+ORDER BY DESC(?copies_sold)
+LIMIT 5
+
+
+Description Level 7:
+
+Using the same book schema as before, find the five authors that have sold the least copies,
+so that your boss can decide whether they need to stop selling books from these authors.
+
+
+Reference solution:
+
+@prefix rdf:
+@prefix ex:
+@prefix dc:
+
+SELECT ?author (SUM(?copies_sold) AS ?total_copies_sold)
+WHERE {
+ ?book rdf:type ex:Book ;
+ ex:author ?author ;
+ ex:copies_sold ?copies_sold .
+}
+GROUP BY ?author
+ORDER BY ASC(?total_copies_sold)
+LIMIT 5
+
+Level 6 Description:
+
+Let’s now say that to the book schema we add the book review schema.
+Knowing that there is a resource called ex:Mystery that is a genre, and a resource called
+ex:Acme that is a publisher, can you find the books that have received a grade higher than 4,
+of genre Mistery, and published by Acme?
+
+Reference solution:
+
+@prefix rdf:
+@prefix ex:
+@prefix dc:
+@prefix foaf:
+
+SELECT ?book ?title ?author ?publisher ?genre ?person
+WHERE {
+ ?book rdf:type ex:Book ;
+ dc:title ?title ;
+ ex:author ?author ;
+ ex:publisher ?publisher ;
+ ex:genre ?genre .
+
+ ?person rdf:type foaf:Person ;
+
+ ?review rdf:type ex:Review ;
+ ex:book ?book ;
+ ex:reviewer ?person ;
+ ex:rating ?rating .
+
+ FILTER(?rating >= 4 && ?genre = ex:Mystery && ?publisher = ex:Acme)
+}
+
+
+Level 5 Description:
+
+Level 6 kata from matt c, NULL handling,
+https://www.codewars.com/kata/5811315e04adbbdb5000050e/solutions
+
+You are using the card shop schema. For this challenge you need to create a SELECT statement,
+this statement must have NULL handling, using COALESCE and NULLIF.
+
+If name is an empty string, you must replace with '[product name not found]'.
+
+If card_name is an empty string, you must replace with '[card name not found]'.
+
+If no price is specified (i.e. price is NULL), or if the price is 50 or less, you must
+discard the row.
+
+You are asked to retrieve ?id ?name ?price ?card_name ?card_number ?transaction_date and
+consider that name, cardname and cardnumber could be blank.
+
+Reference solution:
+
+SELECT ?id ?name ?price ?card_name ?card_number ?transaction_date
+WHERE {
+ ?s ex:id ?id ;
+ ex:price ?price ;
+ ex:transactionDate ?transaction_date .
+ OPTIONAL { ?s ex:name ?name }
+ OPTIONAL { ?s ex:cardName ?card_name }
+ OPTIONAL { ?s ex:cardNumber ?card_number }
+ FILTER (?price > 50)
+ BIND(COALESCE(NULLIF(?name, ''), '[product name not found]') AS ?name)
+
+
+
+Description Level 5
+
+Take the card shop schema. You are requested to find the department name of the departments
+that have had at least five sale that were worth more than 50. You also want to make sure
+that the department in question has in total sales for less than 500. Finally, you want to
+make sure that the sales are checked for 2022 only.
+
+Reference solution:
+
+@prefix ex:
+
+SELECT ?department_name (COUNT(?s) AS ?num_sales) (SUM(?price) AS ?total_sales)
+WHERE {
+ ?s ex:id ?id ;
+ ex:price ?price ;
+ ex:transaction_date ?transaction_date ;
+ ex:sold_by ?department .
+ OPTIONAL { ?s ex:name ?name }
+ OPTIONAL { ?s ex:card_name ?card_name }
+ OPTIONAL { ?s ex:card_number ?card_number }
+ ?department ex:name ?department_name .
+ FILTER (YEAR(?transaction_date) = 2022 && ?price > 50)
+}
+GROUP BY ?department_name
+HAVING (COUNT(?s) > 5 && SUM(?price) > 500)
+ORDER BY DESC(?total_sales)
+
+
+
+Description level 6:
+
+Take the people and card shop schema.
+
+Add a property
+
+ex:madeBy rdf:type rdf:Property ;
+ rdfs:domain ex:Sale ;
+ rdfs:range ex:Person ;
+ rdfs:label "Indicates that a person customer has bought a certain product" .
+
+You are now asked to write a query that finds dates, name of the buyer and price of
+transactions made after October 10 2022.
+
+Reference Solution:
+
+SELECT ?name ?transaction_date ?price
+WHERE {
+ ?s ex:id ?id ;
+ ex:price ?price ;
+ ex:transactionDate ?transaction_date ;
+ ex:madeBy ?p .
+ ?p people:name ?name ;
+ FILTER (?price > 50 && ?transaction_date > "2022-10-03"^^xsd:date)
+}
+
+
+Description Level 7:
+Taken from level 7 kata from PG1 Concatenating columns https://www.codewars.com/kata/59440034e94fae05b2000073/train/sql
+
+Your task is to use a select statement to return a single string containing the full title of the person, i.e. containing their prefix, first and last name, and suffix.
+
+You are using the person schema (NB person schema is not the people schema).
+
+Reference solution:
+
+@prefix ex:
+SELECT CONCAT(?prefix, ' ', ?first, ' ', ?last, ' ', ?suffix) AS ?title
+WHERE {
+ ?person ex:hasPrefix ?prefix ;
+ ex:hasFirstName ?first ;
+ ex:hasLastName ?last ;
+ ex:hasSuffix ?suffix .
+}
+
+
+Description Level 6
+
+Take now the person schema, as well as the card store schema and the property
+
+ex:madeBy rdf:type rdf:Property ;
+ rdfs:domain ex:Sale ;
+ rdfs:range ex:Person ;
+
+You are now asked to store in a single string the prefix and last name of all the customers who have made a purchase on February 21 2023. Also retrieve the department name, and group the result by it. Call the string column “title”.
+
+Reference solution:
+
+SELECT CONCAT(?prefix, ' ', ?last) AS ?title ?name
+WHERE {
+ ?s ex:name ?name ;
+ ex:transactionDate ?transaction_date ;
+ ex:madeBy ?p .
+ ?p ex:hasPrefix ?prefix;
+ ex:hasLastname ?last .
+ FILTER (?transaction_date = "2022-02-21"^^xsd:date)
+GROUP BY ?name
+}
+
+
+Description level 4:
+Taken from kata level 6 from [pmatseykanets](https://www.codewars.com/users/pmatseykanets) , conditional count, https://www.codewars.com/kata/5816a3ecf54413a113000074/solutions
+
+Start from rental table.
+
+Now, imagine that there are two employees, called Jon and Mike, and that you want to compare the number and total amounts of payments made in Mike's and Jon's stores broken down by months.
+The result needs to use the following columns:
+?month ?total_count ?total_amount ?mike_count ?mikeAmount ?jon_count ?jon_amount
+Where
+month - number of the month (1 - January, 2 - February, etc.)
+total_count - total number of payments
+total_amount - total payment amount
+mike_count - total number of payments accepted by Mike (staff_id = 1)
+mike_amount - total amount of payments accepted by Mike (staff_id = 1)
+jon_count - total number of payments accepted by Jon (staff_id = 2)
+jon_amount - total amount of payments accepted by Jon (staff_id = 2)
+
+There is no need to worry about years, data comes from the same year only.
+
+Reference solution:
+
+@prefix xsd:
+@prefix rdf:
+@prefix payment:
+@prefix staff:
+
+SELECT ?month (COUNT(* ) AS ?total_count) (SUM(?amount) AS ?total_amount)
+ (COUNT(?mike) AS ?mike_count) (SUM(?mikeAmount) AS ?mike_amount)
+ (COUNT(?jon) AS ?jon_count) (SUM(?jonAmount) AS ?jon_amount)
+WHERE {
+ ?payment rdf:type payment:Payment ;
+ payment:payment_date ?date ;
+ payment:amount ?amount ;
+ payment:madeBy ?staff .
+ BIND(MONTH(?date) AS ?month)
+ OPTIONAL {
+ ?staff rdf:type staff:Staff ;
+ staff:id 1 .
+ BIND(IF(BOUND(?staff), ?payment, NULL) AS ?mike)
+ BIND(IF(BOUND(?mike), ?amount, NULL) AS ?mikeAmount)
+ }
+ OPTIONAL {
+ ?staff rdf:type staff:Staff ;
+ staff:id 2 .
+ BIND(IF(BOUND(?staff), ?payment, NULL) AS ?jon)
+ BIND(IF(BOUND(?jon), ?amount, NULL) AS ?jonAmount)
+ }
+}
+GROUP BY ?month
+ORDER BY ?month
+
+
+Description Level 7 6:
+kata level 6 from matt c, simple HAVING, https://www.codewars.com/kata/58164ddf890632ce00000220/train/sql
+
+Take the people schema. You are requested to check for how many people have the same age
+and return the groups with 10 or more people who have that age. You need to return two
+columns, onefor age and one for total_people having that age.
+
+
+@prefix :
+SELECT ?age (COUNT(?id) AS ?total_people)
+WHERE {
+?person people:age ?age ;
+ people:id ?id .
+}
+GROUP BY ?age
+HAVING (COUNT(?id) > 9)
+
+
+Description Level 5:
+Level 6 kata from FArrekkusu, Analyzing the sales by product and date, https://www.codewars.com/kata/5dac87a0abe9f1001f39e36d/solutions
+
+Take the sales schema.
+
+You are asked to calculate the total revenue for each day, month, year, and product.
+
+Notes
+The sales table stores only the dates for which any data has been recorded - the information about individual sales (what was sold, and when) is stored in the sales_details table instead.
+The sales_details table stores totals per product per date.
+Order the result by the product_name, year, month, day columns
+We're interested only in the product-specific data, so you shouldn't return the total revenue from all sales.
+
+Reference solution:
+
+@prefix ex:
+@prefix xsd:
+
+SELECT ?product_name (xsd:int(?year) as ?year) (xsd:int(?month) as ?month) (xsd:int(?day) as ?day) (SUM(?price * ?count) as ?total)
+WHERE {
+ ?sd ex:sale_id ?sale_id ;
+ ex:product_id ?product_id ;
+ ex:price ?price ;
+ ex:count ?count .
+ ?s ex:id ?sale_id ;
+ ex:date ?date .
+ ?p ex:id ?product_id ;
+ ex:name ?product_name .
+ BIND(year(?date) as ?year)
+ BIND(month(?date) as ?month)
+ BIND(day(?date) as ?day)
+}
+GROUP BY ?product_name ROLLUP (?year ?month ?day)
+ORDER BY ?product_name ?year ?month ?day
diff --git a/Project-2/README.md b/Project-2/README.md
index a943bd20..03f24dfe 100644
--- a/Project-2/README.md
+++ b/Project-2/README.md
@@ -5,52 +5,263 @@ Your second project will require you to answer each of the 10 questions below.
```
Tip #1: Carefully study the Baader, et. al. selections assigned on bisimulation; it is deceptively subtle, and quite powerful.
Tip #2: Google is still your friend. So is stackexchange...
-Tip #3: Work together to solve these problems, even for initial submissions and when you do, document this in github.
-Tip #4: Work together as a team.
+Tip #3: Work _together_ to solve these problems, even for initial submissions and when you do, document this in github.
+Tip #4: Work together _as a team_.
```
1. Let V be a vocabulary of ALCI consisting of a role name "P". Interpret part_of as "x is a part of y". Using this role name, define the following formulas in this language:
-```
+```Other symbols:∀∃ ⊔ ⊓ ⊧ ⊭ ⊦ ⊬ ⊏ ⊐ ⊑ ⊒ ≡ ¬ → ∨ ∧ ¯ ⊤ ≥ ≤
+
(a) PP that says that x is a proper part of y
+ PP ≡ P ⊓ ¬P¯
+ This reads something like: a proper part between x and y exists iff
+ x is part of y and it is not the case that the inverse parthood relation ("being a whole of")
+ holds between x and y.
(b) iPP that says that y is a proper part of x
- (c) iP that says that x has y as part
+ iPP ≡ PP¯
+ iPP ≡ ¬P ⊓ P¯
+ (c) iP that says that y has x as part
+ iP ≡ P¯
(d) O that says that x overlaps y
+ O ≡ ∃iP.(∃P.⊤)
(e) D that says that x and y are disjoint
+ D ≡ ¬O
```
2. Use your axioms from question 1 as the basis of an ALCI T-Box. Supplement this T-box with whatever other axioms you like, as well as an A-box, so that you ultimately construct a knowledge base K = (T,A). Provide a _model_ of K. This may be graphical or symbolic or both.
+TBox = {
+PP ⊑ P
+P ⊑ O
+O ⊑ O¯
+}
+
+ABox = {
+Italy : State
+(Italy, Italy) : P
+(Italy, Europe) : P
+(UK, Europe) : ¬ P
+UK : State
+(UK, UK) : P
+(Venice, Italy) : P
+(Venice, Venice) : P
+(Venice, Italy) : O
+(Venice, Europe) : O
+Venice : City
+(UK, UK) : P
+(UK, Italy) : D
+(UK, Venice) : D
+(London, UK) : P
+(London, London) : P
+London : City
+}
+
+ΔI = {Italy, Europe, UK, Venice, London}
+
+Named Individuals:
+EuropeI = E,
+ItalyI = I,
+VeniceI = V,
+UKI = U
+LondonI = L
+
+Concept Assignments:
+State = {U, I}
+City = {V, L}
+Sovranational Union = {E}
+
+
+Role Assignments:
+PI = {(I, E), (V, I), (V, E), (V, V), (E, E), (I, I), (L, L), (L, UK), (UK, UK)}
+PPI = {(I, E), (V, I), (V, E), (L, UK)}
+D = {(L, I), (L, V), (V, UK), (E, UK), (I, UK)}
+
3. Translate the following first-order logic axioms into ALCI:
```
(a) ∀x∃y∀z(R(x,y) ∧ R(x,z) ∧ R(y,z))
+∃R.(∀R.(∀R¯.T))
(b) ∃x∀y∃z(R(x,y) ∧ R(x,z) ∧ R(y,z))
+∃R¯.(∃R.(∃R¯.T))
+Given that DL has an implicit universal quantifier at the beginning, here we decided
+to start from y as subject of the formula, which is universally quantified.
+Our strategy to deal with this problem is to address the universal quantifier by inversing
+the R(x,y) relation. Since we want x and z to be successors of y,
+we have to write the first relation R(x,y) in an inverse format (i.e. R¯).
(c) ∀y(R(x, y) → ∃x(R(y, x) ∧ ∀y(R(x, y) → A(y))))
+∀R.∃R.∀R.A
(d) (∀y)(R(x, y) → A(y)) ∧ (∃y)(R(x, y) ∧ B(y))
+(∀R.A) ⊓ (∃R.B)
```
-4. Provide an interpretation I1 for ALC and an interpretation I2 for ALCN - each distinct from any interpretation covered in class so far - and construct a bisimulation that demonstrates ALCN is more expressive than ALC. Use the [mermaid syntax](https://github.com/mermaid-js/mermaid) of markdown to provide a graphical representation of your work. Feel free to use the [mermaid live editor](https://mermaid.live/) when diagramming.
+4. Provide an interpretation I1 for ALC and an interpretation I2 for ALCN - each distinct from any interpretation covered in class so far - and construct a bisimulation that demonstrates ALCN is more expressive than ALC. Use the [mermaid syntax](https://github.com/mermaid-js/mermaid) of markdown to provide a graphical representation of your work.
+
+
+ΔI1 = {Dr. Beverley, PHI 697, PHI 329, Tuesday Workshop}
+
+Named IndividualsI:
+Dr. BeverleyI = B
+PHI 697I = 697
+PHI 329I = 329
+Tuesday WorkshopI = W
+
+Role Assignments:
+t = {(B, 697), (B, 329), (B, W)}
+
+
+ΔI2 = {Dr. Beverley, PHI 697, PHI 329}
+
+Named IndividualsI:
+Dr. BeverleyI2 = B2
+PHI2 697I = 697-2
+PHI 329I = 329-2
+
+Role Assignments:
+t2 = {(B2, 697-2), (B, 329-2)}
+
+Bisimulation:
+
+ρ = {(B, B2), (697, 697-2), (329, 329-2)}
+
+So B is bisimilar to B2. But we can distinguish them in ALCN by defining the role m as
+≥3 ∃t.⊤
+in I1
+≥2 ∃t2.⊤
+in I2
+
+https://mermaid.ink/img/pako:eNqNkDELgkAYhv_K8S0Z6KBCoUND2NIUJDR0DR_eVyd6npxnIdp_74KGaKje6R2eB17eEQotCFI41_pWSDSW5RlvmEsWHrdaNmxNVzL1cGJBsGKTJSwkdRPbhN5OlotkOf8Pj554HCV_4rGX99QJHNhBm6qTunXiS42-q7PPZb_4t2nggyKjsBTuk_Hpc7CSFHFIXRVoKg68uTsOe6v3Q1NAak1PPvStQEtZiReDCtIz1h3dH3_hcFQ?type=png)](https://mermaid.live/edit#pako:eNqNkDELgkAYhv_K8S0Z6KBCoUND2NIUJDR0DR_eVyd6npxnIdp_74KGaKje6R2eB17eEQotCFI41_pWSDSW5RlvmEsWHrdaNmxNVzL1cGJBsGKTJSwkdRPbhN5OlotkOf8Pj554HCV_4rGX99QJHNhBm6qTunXiS42-q7PPZb_4t2nggyKjsBTuk_Hpc7CSFHFIXRVoKg68uTsOe6v3Q1NAak1PPvStQEtZiReDCtIz1h3dH3_hcFQ
+
+5. Provide an interpretation I1 for ALC and an interpretation I2 for ALCN - each distinct from any interpretation covered in class so far - and construct a bisimulation that _does not_ demonstrate ALCN is more expressive than ALC. Use the [mermaid syntax](https://github.com/mermaid-js/mermaid) of markdown to provide a graphical representation of your work.
-5. Provide an interpretation I1 for ALC and an interpretation I2 for ALCN - each distinct from any interpretation covered in class so far - and construct a bisimulation that _does not_ demonstrate ALCN is more expressive than ALC. Use the [mermaid syntax](https://github.com/mermaid-js/mermaid) of markdown to provide a graphical representation of your work. Feel free to use the [mermaid live editor](https://mermaid.live/) when diagramming.
+ΔI1 = {Dr. Beverley, PHI 697, PHI 329}
+Named IndividualsI:
+Dr. BeverleyI = B
+PHI 697I = 697
+PHI 329I = 329
+
+
+Role Assignments:
+t = {(B, 697), (B, 329)}
+
+
+ΔI2 = {Dr. Beverley, PHI 697, PHI 329}
+
+Named IndividualsI:
+Dr. BeverleyI2 = B2
+PHI2 697I = 697-2
+PHI 329I = 329-2
+
+
+Role Assignments:
+t2 = {(B2, 697-2), (B, 329-2)}
+
+Bisimulation:
+
+ρ = {(B, B2), (697, 697-2), (329, 329-2)}
+
+So B is bisimilar to B2. The ALCN definitions are
+≥2 ∃m.⊤
+in I1
+≥2 ∃m2.⊤
+in I2
+
+https://mermaid.ink/img/pako:eNqNjzELwjAQhf9KuEWFOrSC0g4OUhcnQTfjcCSnKTaJxFQpbf-7KXUQB_VNx_F9PF4DwkqCDE6lfQiFzrN9zg0LyePDxirDVnQnV9ZHNp0uWesJhaJby9bxeKuKebqY_IcnPT5L0gHn5mUl363RZ8sv_q0GItDkNBYy7Gt6n4NXpIlDFk6J7sKBmy5wWHm7q42AzLuKIqiuEj3lBZ4d6uHZPQFU2F5C?type=png)](https://mermaid.live/edit#pako:eNqNjzELwjAQhf9KuEWFOrSC0g4OUhcnQTfjcCSnKTaJxFQpbf-7KXUQB_VNx_F9PF4DwkqCDE6lfQiFzrN9zg0LyePDxirDVnQnV9ZHNp0uWesJhaJby9bxeKuKebqY_IcnPT5L0gHn5mUl363RZ8sv_q0GItDkNBYy7Gt6n4NXpIlDFk6J7sKBmy5wWHm7q42AzLuKIqiuEj3lBZ4d6uHZPQFU2F5C
6. Explain the difference - using natural language - between the description logic expressions:
```
(a) ∃r.C and ∀r.C
+ The first one reads: all x has a r-filler y instantiating C
+ The second one reads: all r-fillers ys of x instantiate C.
(b) ∃r-.C and ∀r-.C
+ The first one reads: there is a thing r-related to all xs, and this thing falls under concept C
+ The second one reads: if there is a thing r-related to all xs, this thing falls under concept C
(c) <=nr and <=nr.C
+ The first one reads: role r connects all the xs to no more than n elements.
+ The second one reads: role r connects all the xs to no more than n elements, and they fall under concept C.
(d) ∃r-.C and ∃r-.{a}
+ The first one reads: for all xs, there is at least a thing y, which is r-reverse related to it, and which falls under concept C.
+ The second one reads: for all xs, there is element a, which is r-reverse related to it.
+
```
7. There is a delightfully helpful subreddit called "ELI5" which stands for something like "explain it like I'm 5" where users post conceptually challenging questions and other users attempt to provide explanations in simple, jargon-free, terms that presumably a 5 year-old could understand. Using this as a model, explain the _finite model property_. Be sure to provide a simple example and explain when the property might be important, and when it is not so important.
+The finite model property means that if you want to prove something in a game or puzzle,
+you don't have to use too many toys or blocks,just a few of them will be enough.
+This makes it easier to solve the game or puzzle and saves time.
+Suppose you have a game with two toy animals, a cat and a dog. The rules of the game are
+that the cat is always hungry, and the dog is always friendly. You want to prove that
+if the cat is hungry, then the dog is not hungry.
+One way to prove this would be to use all the possible combinations of hunger and friendliness
+for the cat and the dog, which would require an infinite number of possibilities.
+But because the game has the finite model property.
+
8. Following up on the preceding , explain the _tree model property_. Be sure to provide a simple example and explain when the property might be important, and when it is not so important.
-9. Open the Protege editor and create object properties for each of the role names that you constructed in question 1. You should have at least 6 object properties. Assert in the editor that P is a sub-property of O, that P is transitive, and that O is symmetric. Next, add individuals - a, b, c - to the file and assert that c is part of a and that c overlaps b. Running the reasoner should reveal - highlighted in yellow if you select the individual c - that c overlaps a. Using the discussion in the selections from chapter 4 of the Baader, et. al. text as a guide, explain how the tableau algorithm is generating this inference. Also, provide a screenshot of the results of your reasoner run with c highlighted.
+Imagine you have a toy with lots of buttons and levers. When you press a button or pull a lever,
+the toy changes in some way. The finite tree model is like a picture of all the different ways
+the toy can change.
+Each picture shows the toy in a different state, with some buttons and levers pressed and
+others not pressed. You can draw lines between pictures. The lines between the pictures show
+how the toy changes when you press a button or pull a lever.
+By looking at all the pictures together, you can see all the different ways the toy can change,
+and how it changes from one state to another. This can help you understand how the toy works
+and how to use it.
+
+An example:Imagine you're playing a game where you have to guess a number between 1 and 10.
+The game will tell you if your guess is too high or too low, and you have to keep guessing
+until you get the right answer.
+We can represent this game as a finite tree model. The starting point is when you make your
+first guess, which is like the "root" of the tree. Depending on whether your guess is too high
+or too low, the tree branches off into two different paths.
+If your guess is too high, you go down one path where you make a lower guess.
+If your guess is too low, you go down the other path where you make a higher guess.
+This branching continues until you finally guess the right number, which is like reaching
+a "leaf" node in the tree.
+By using the finite tree model to represent the guessing game, we can see all
+the different possible paths that the game can take, and how the game progresses
+from one guess to the next.
+In the same way, the finite tree model helps people understand how programs and processes
+work by showing all the different ways they can change and how they change from one state to
+another.
+
+
+9. Open the Protege editor and create object properties for each of the role names that
+you constructed in question 1. You should have at least 6 object properties.
+Assert in the editor that P is a sub-property of O, that P is transitive,
+and that O is symmetric. Next, add individuals - a, b, c -
+to the file and assert that c is part of a and that c overlaps b.
+Running the reasoner should reveal - highlighted in yellow if you select the individual c -
+that c overlaps a. Using the discussion in the selections from chapter 4 of the Baader,
+et. al. text as a guide, explain how the tableau algorithm is generating this inference.
-10. Following up on your work in question 9, adjust/add/remove/etc. object properties and individuals in your Protege file so that when you run a reasoner in Protege, you return the following consequences:
+The tableau method starts from a Knowledge Base, i.e. the assertions we made through the
+Protege editor about individuals and between classes. We then build a tree.
+Each node in the tree represents a possible interpretation, and the branches represent
+the different ways in which the interpretation can be extended. It then expands the assertions
+by using different rules. For example the disjunction rule to check all the possible cases
+(see Baader from page 71 to 73) and other rules for subsumption, etc. (see Baader pag. 84).
+What we are doing is basically constructing a set of possible interpretations where all the
+possible inferences from T-box are drawn, as well as all the possible concept memberships are
+tried.
+As a result, the reasoner will notice the logical relations between the concepts we asserted
+for individuals through Protege. It will see that c is a part of a, and since parthood is
+subsumed by overlap, it will apply the subsumption rule explained at page 84 in Baader et al.
+This will add a new fact, that c overlaps a.
+
+
+10. Following up on your work in question 9, adjust/add/remove/etc. object properties
+and individuals in your Protege file so that when you run a reasoner in Protege, you return
+the following consequences:
```
- (a) a is a proper part of b and disjoint from e
+ (a) a is a proper part of b DONE and disjoint from e DONE
+
(b) a overlaps c
- (c) a is part of b, b is part of f, and a is part of f
+ DONE
+ (c) a is part of b, b is part of f, and a is part of f DONE
(e) There are no parts between a and g in common
+ Not sure how this differs from being disjoint from, plus being different individuals.
+ I can make the system spit out that a is disjoint from g, but I am not sure how I can make
+ it say that they are different individuals, except from inserting the fact myself.
+
+
```
-Provide a screenshot of your results here.
diff --git a/Project-2/ex 10 1.png b/Project-2/ex 10 1.png
new file mode 100644
index 00000000..49cac6fc
Binary files /dev/null and b/Project-2/ex 10 1.png differ
diff --git a/Project-2/ex 10 2 3.png b/Project-2/ex 10 2 3.png
new file mode 100644
index 00000000..61790eae
Binary files /dev/null and b/Project-2/ex 10 2 3.png differ
diff --git a/Project-2/ex 10 4.png b/Project-2/ex 10 4.png
new file mode 100644
index 00000000..89f5b3ba
Binary files /dev/null and b/Project-2/ex 10 4.png differ
diff --git a/Project-2/ex 9 .png b/Project-2/ex 9 .png
new file mode 100644
index 00000000..1bda759b
Binary files /dev/null and b/Project-2/ex 9 .png differ
diff --git a/Project-3/README.md b/Project-3/README.md
index ab751654..b0277c25 100644
--- a/Project-3/README.md
+++ b/Project-3/README.md
@@ -11,67 +11,466 @@ For any question involving the use of Protege, please be sure to import:
1. In BFO and RO identify at least one object property for each of a-e that _should have the listed property, but which does not_; argue for your case, using examples. Note: It will be easiest to view the object properties in BFO and RO using Protege.
```
(a) Reflexive
+
+ Simultaneous_with
+
+ or,
+
+ The object property, “overlaps”, should have the reflexive characteristic listed.
+ It’s definition states: x overlaps y if and only if there exists some z such that x has part z
+ and z part of y. Reflexivity is the characteristic that expresses the relation that an
+ entity be related to itself. The object property “overlaps” should have reflexive as a listed
+ characteristic since an object shares itself (and parts of itself) with itself.
+
(b) Transitive
+
+ The object property, “existence ends with”, should have the transitive characteristic listed.
+ It’s definition states: “x existence ends with y if and only if the time point at which x
+ ends is equivalent to the time point at which y ends. Formally: x existence ends with y iff
+ ω(x) = ω(y).” That is, if any entity x ends at the equivalent time point of any other entity y,
+ then they share the same object property, “existence ends with”. Thus, any entity x that ends
+ at a shared equivalent time point with entity y, and entity y ends at a shared equivalent
+ point with entity z, then entity x will share an end equivalent time point with entity z.
+ If entity x shares the same object property, i.e. existence ends with, with entity z, then
+ the relation must be transitive. Therefore, the object property “existence ends with”
+ should have transitive as a listed characteristic.
+
(c) Symmetric
+
+ The object property, “partially overlaps”, should have the symmetric characteristic listed.
+ It’s definition states: “x partially overlaps y iff there exists some z such that z is part
+ of x and z is part of y, and it is also the case that neither x is part of y or y is part of
+ x”. A symmetric characteristic is a relation such that given any elements a and b of set G,
+ if a~b, then b~a. Another way to think of symmetry is that the property has itself as an
+ inverse, so if individual a is related to individual b then individual a must also be related
+ to individual y along the same property. In this case, the “partially overlaps” symmetric
+ relation is found in z. z is congruent with z and its inverse is z. Thus, z is a symmetrical
+ relation, although x is neither a part of y, nor is y a part of x. Therefore, the object
+ property “partially overlaps” should have symmetric as a listed characteristic.
+
+
(d) Functional
+
+ The object property, “has target end location”, should have the functional characteristic
+ listed. It’s definition states: “This relationship holds between p and l when p is a
+ transport or localization process in which the outcome is to move some cargo c from a an
+ initial location to some destination l.” The functional property relation means that for any
+ given individual, the property can have at most one value. In other words, there can be at
+ most one out going relationship along the property for that individual. This means that a
+ functional object property has a multiplicity 0..1 attached to it. For example,the
+ functional property hasHusband shows that the person, in a monogamous universe,
+ can have at most one husband. In the case of the object property “has target end location”,
+ there is at most one specified end location in which the outcome is to move some cargo c
+ from a an initial location to some destination l. The end location is univocal, that is,
+ only has one possible meaning. Thus, the object property relation “has target end location”
+ is functional. Therefore, the object property “has target end location” should have
+ functional as a listed characteristic.
+
+ For similar reasons, I believe "ends with" should be functional.
+
(e) Symmetric and Reflexive
+
+ Overlaps, for similar reasons to the one expressed regarding symmetry. In addiction, we need
+ it to be reflexive because everything overlaps itself.
+ Also, The object property, “simultaneous with”, should have the symmetric and reflexive
+ characteristic listed. It’s definition states: t1 simultaneous_with
+ t2 iff:= t1 before_or_simultaneous_with t2 and not (t1 before t2).It’s reflexive,
+ since any time must be simultaneous with itself. And it’s symmetric, since, if t1 is
+ simultaneous with t2, then t2 must be simultaneous with t1. Therefore, the object property
+ “simultaneous with” should have functional as a listed characteristic.
+
+
```
2. In BFO and RO identify at least one object property for each of a-e that _should not have the listed property, but which does_; argue for your case, using examples. Note: It will be easiest to view the object properties in BFO and RO using Protege.
```
(a) Irreflexive
+
+ The object property, “has role in modeling”, should not have the irreflexive property listed.
+ It’s definition states: “A relation between a biological, experimental, or computational
+ artifact and an entity it is used to study, in virtue of its replicating or approximating
+ features of the studied entity.” Imagine a machine that is designed to model aspects of itself.
+ It can be used to study itself, in virtue of its ability to reflect aspects of itself.
+ However, an irreflexive property relation is one such that an entity cannot relate to itself.
+ Thus, although the object property, “has role in modeling”, has the irreflexive property
+ listed, it should not.
+
(b) Transitive
+
+ The object property, “aligned with”, should not have the transitive property listed. Finn:
+ Imagine two lines of blocks that intersect at block B. Call one row 'Vertical' and the other
+ 'Horizontal'. A is a block in Vertical, but not Horizontal. C is a block in Horizontal, but
+ not Vertical. And B is in both Vertical and Horizontal. A is aligned with B, since they're in
+ the same row, and B is aligned with C for the same reason, but A is not aligned with B.
+ For this object property, there is no definition expressed. Instead, there is an editor’s note
+ that states: “May be obsoleted, see https://github.com/oborel/obo-relations/issues/260”.
+ If you follow this link, you will see four collaborators deliberate on whether to make this
+ term obsolete. It was cited that “aligned with” was used to define at least one widely used
+ relation, “fasciculates with”. Upon searching this object property, it is now a subproperty
+ of “overlaps”. Subsequently, on October 15th, 2020, nlharris added the obsolete label to the
+ term. Due to the fact that there lacks a definition and “aligned with” is insufficient to
+ establish that it holds a transitive characteristic, the transitive characteristic should be
+ unlisted. Transitivity means that if individual x is related to individual y, and individual
+ y is related to individual z, then individual x will be related to individual z. In other
+ words, a single “hop” is implied over a chain of two along a given property if that property
+ is transitive. Based on its label, one cannot infer that “aligned with” necessitates a
+ transitive relation between x and z. For example, x may share a border with y, y may share a
+ border with z, but x may not share a border with z. It would be said that x is aligned with y
+ (i.e. shares a border), but x is not aligned with z. Moreover, aligned with could also mean
+ an overlapping relation, rather than sharing a border. This further problematizes the
+ vagueness of the term. Thus, because (1) there is no clear definition, (2) the label,
+ “aligned with”, is ambiguous, and (3) pragmatically speaking, the term has been rendered
+ obsolete, I recommend that the transitive characteristic be unlisted. It is not clear that
+ “aligned with” is transitive. For the reasons cited above with examples, both intransitive
+ bordering relations and overlapping relationships can be inferred by its label and yet, the
+ object property is not clear whether it means to represent both kinds of relations.
+
(c) Asymmetric
+
+ The object property, “has role in modeling”, should not have the asymmetric property listed.
+ It’s definition states: “A relation between a biological, experimental, or computational
+ artifact and an entity it is used to study, in virtue of its replicating or approximating
+ features of the studied entity.” In BFO, an artifact is defined as: “something that is
+ deliberately designed (or, in certain borderline cases, selected) by human beings to address
+ a particular purpose” (3). BS elucidates on this further: “While not all representational
+ artifacts are ontologies, all ontologies are representational artifacts, and thus everything
+ that holds of representational artifacts in general holds also of ontologies” (3).
+ Conceptually, the import of this is that if artifact x has a role in modeling entity y,
+ artifact x’s relation between entity y is subject to the same BFO domain rules as everything
+ else. That is, if the declared characteristic of an artifact x is universally declared to be
+ asymmetric to an entity y, then it follows that there are no such cases where the
+ relationship between artifact x and entity y is symmetric. Its plausible that artifact x’s
+ possible relations to entity y may in some cases be asymmetric (e.g. healthy cell line
+ [artifact] → inducing disease [entity]), in others they may be symmetric (e.g. diseased model
+ organism [artifact] → same diseased model organism over time [entity]), and further still, it
+ might best to remain agnostic in such relations, leaving the characteristics neither
+ asymmetric or symmetric, for garnering preferred inference modeling conditions for
+ particularized ends. In order to have a wide ranging and flexible “has role in modeling”
+ object property to classify possible relations between an artifact x and entity y, I argue
+ that it is more advantageous and preferable to unlist the asymmetric characteristic so that
+ possible symmetry relations and relations where it is best to remain agnostic on
+ symmetry/asymmetry assertions may be represented in artifact to entity modeling relations.
+ This is both an appeal to pragmatic and philosophical reasons. Unless all relations between
+ artifact x and entity y are asymmetric, they should not be listed as such. By doing so, other
+ non-asymmetric modeling relations cannot adequately be represented. Thus, although the
+ “has role in modeling” object property has the asymmetric characteristic listed
+ (likely for pragmatic purposes specific to modeling ontologies with distinct ends),
+ I argue that it would be better to dispense with it if one’s aim is to represent a wider
+ domain of possible symmetric/asymmetric relations between artifacts with specific modeling
+ roles and entities. Moreover, a more robust and comprehensive ontology would be representable
+ as a result of unlisting the asymmetric characteristic.
+
(d) Functional
+
+ The object property, “characteristic of”, should not have the functional property listed.It’s
+ definition states: “a relation between a specifically dependent continuant
+ (the characteristic) and any other entity(the bearer), in which the characteristic depends on
+ the bearer for its existence.” The functional property relation means that for any given
+ individual, the property can have at most one value. In other words, there can be at most one
+ out going relationship along the property for that individual. This means that a functional
+ object property has a multiplicity 0..1 attached to it. For example, it might be said that
+ the continuant red is “characteristic of” Washington Red Delicious Apples. Or put in another
+ way, this red color is a characteristic of this Washington Red Delicious Apple. However, it
+ is not the case that a given characteristic necessarily corresponds with at most one value,
+ univocally. It could very well be the case that the red characteristic of Washington Red
+ Delicious Apples might also have another corresponding value in a red colored car of the same
+ hue. This means that correspondence between a characteristic and a bearer is not necessarily
+ functional, i.e. has a binary value between 0 and 1 at most. A characteristic can have a one
+ to one relationship to a bearer, a one to many relationship, a many to many relationship,
+ or a many to one relationship. What could be the explanation of why this object property was
+ set to having the functional characteristic? Upon further analysis, one can find a note in
+ the ontology: “Note that this relation was previously called "inheres in", but was changed to
+ be called "characteristic of" because BFO2 uses "inheres in" in a more restricted fashion.
+ This relation differs from BFO2:inheres_in in two respects: (1) it does not impose a range
+ constraint, and thus it allows qualities of processes, as well as of information entities,
+ whereas BFO2 restricts inheres_in to only apply to independent continuants (2) it is declared
+ functional, i.e. something can only be a characteristic of one thing.” (2) states: “it is
+ declared, i.e. something can only be a characteristic of one thing.” What one might infer
+ from this declaration is that this was done for pragmatic purposes in order to elicit
+ preferred inference relations without having to deal with the burden of unwanted inferences
+ to irrelevant elements. So for example, by declaring a functional constraint on
+ “characteristic of” the ontologist could make pragmatic use of a delimited ontology that
+ always garners a one to one relation, rather than a one to many, and so on. As a result,
+ if the reasoner is run the functional constraint set will restrict the domain to one to one
+ functional relations only. Thereby granting the conditions for a more specific, restricted
+ ontology. However, I must make a case for unlisting the functional characteristic. If I
+ was an ontologist seeking to construct a knowledge base outside of a delimited domain of
+ one to one functional relationships and wanted to represent the class of all red things,
+ then I ought to unlist the functional characteristic so that the object property relation
+ “characteristic of” could represent and infer a one to many relationship, which is not
+ functional by definition, i.e. 0..1..X. Thus, although the “characteristic of” object
+ property has the functional characteristic listed likely for pragmatic purposes, I argue
+ that it would be better to dispense with it if one’s aim is to represent relations that are
+ one to many, many to one, or many to many.
+
(e) Inverse Functional
+
+ The object property, “has characteristic”, should not have the inverse functional property
+ listed. It’s definition is the inverse of “characteristic of” (from [d]). The
+ “characteristic of” object property’s definition is: “a relation between a specifically
+ dependent continuant (the characteristic) and any other entity(the bearer), in which the
+ characteristic depends on the bearer for its existence.” This answer relies on what was said
+ in (d), but is its inversion. Like the functional characteristic, the inverse functional
+ property relation means that for any given individual, the property can have at most one
+ value. In other words, there can be at most one out going relationship along the property
+ for that individual. This means that an inverse functional object property has a multiplicity
+ 0..1 attached to it. For example, it might be said that apples “has characteristic” color red.
+ Or put in another way, this apple has this characteristic color red. However, it is not the
+ case that a given bearer necessarily corresponds with at most one characteristic value,
+ univocally. It could very well be the case that a car might also have another corresponding
+ value in a color red of the same hue. This means that correspondence between a characteristic
+ and a bearer is not necessarily functional, i.e. has a binary value between 0 and 1 at most.
+ A bearer can have a one to one relationship to a characteristic, a one to many relationship,
+ a many to many relationship, or a many to one relationship.
+ As discussed in (d), it is inferred that as “characteristic of” was declared functional likely
+ for pragmatic purposes, its inverse, “has characteristic”, follows the same constraints for the
+ same reasons. Thus, the reason for which why I would like to make the case that the object
+ property “has characteristic” should be unlisted are based on the same premises argued for in
+ (d). That is, if I was an ontologist seeking to construct a knowledge base outside of a
+ delimited domain of one to one functional relationships and wanted to represent the class of
+ all bearers that have the characteristic color red, then I ought to unlist the inverse
+ functional characteristic so that the object property relation “has characteristic” could
+ represent and infer a many to one relationship or one to many relationship, which is not
+ functional by definition, i.e. X…1 and 0..1..X.
+ Thus, although the “has characteristic” object property has the inverse functional
+ characteristic listed likely for pragmatic purposes, I argue that it would be better to
+ dispense with it if one’s aim is to represent relations that are many to one, one to many,
+ or many to many.
```
3. Model the following natural language expressions using terms from BFO and RO; you are welcome to introduce new terms where needed:
```
- (a) Sally has an arm Tuesday but does not have an arm Wednesday.
+ (In the following example I sometimes use terms like "is" between, e.g. "Sally" and
+ "instance_of. Technically speaking, there is no such a thing (see BS book, pag. 117))
+
+(a) Sally has an arm Tuesday but does not have an arm Wednesday.
+
+Sally instance_of object
+Tuesday instance_of one-dimensional temporal region
+Wednesday instance of one-dimensional temporal region
+Arm instance_of fiat object part
+“Sally participates in having at least one arm on Tuesday” instance of occurrent
+“Sally participates in having no arms on Wednesday” instance of occurrent
+“Sally participates in having at most one arm on Wednesday” instance of occurrent
+
+Due to the vagueness of the statement above, we have narrowed the possible answers to the following two cases:
+
+“"Sally participates in having at least one arm on Tuesday" precedes "Sally participates
+in having no arms on Wednesday"”
+“"Sally participates in having at least one arm on Tuesday" precedes "Sally participates
+in having at most one arm on Wednesday"”
+
(b) Every liver has some cell as part at all times it exists.
+
+ We already have cell in the ontology.
+ Liver is a class in Uberon (UBERON_0002107), which is a subclass of material entity.
+ https://ontobee.org/ontology/UBERON?iri=http://purl.obolibrary.org/obo/UBERON_0002107
+
+ Argument ex auctoritate from BS for the object property has_part_at_all_times:
+ https://youtu.be/fkkWkTIxrNQ
+
+ Liver has_part_at_all_times Cell
+
(c) John was a child, then an adult, then a senior.
+
+ John instance_of object
+ childhood instance_of occurrent.
+ adulthood instance_of occurrent.
+ seniorhood instance_of occurrent.
+
+ “John participates in childhood precedes John participates in adulthood
+ which precedes John participates in seniorhood.”
+
(d) Goofus and Gallant are married at each point in a three year span.
```
+ Goofus instance_of object
+ Gallant instance_of object
+ Marriage instance_of occurent
+ “Three years span 1” instance_of one-dimensional temporal region.
+ Notice that the original phrase doesn’t say anything about Goofus and Gallant being
+ married to each other, and we won’t represent such a fact.
-4. Using the language of First-Order Logic, represent the following natural language expressions; you are welcome to introduce new terms where needed:
+ If zero-dimensional temporal region t1 part_of one-dimensional temporal region
+ “three years span 1”, then Goofus participates in marriage at t1 and Galland participates
+ in marriage at t1.
+
+4. Using the language of First-Order Logic, represent the following natural language expressions;
+you are welcome to introduce new terms where needed:
```
(a) Sally has an arm Tuesday but does not have an arm Wednesday.
+
+ ∃x (Tx ∧ ∃y (Hsy∧Ay)) ∧ ∃x (Wx ∧ ~∃y(Hsy∧Ay))
+ T: Tuesday
+ H: has
+ A: arm
+ W: Wednesday
+ s: Sally
+
(b) Every liver has some cell as part at all times it exists.
+
+ ∀x∃y(Lx→Cy∧Pyx)
+ L: liver
+ C: cell
+ P: part of
+
(c) John was a child, then an adult, then a senior.
- (d) Goofus and Gallant have been married for three years; for each day of that span, it is true to assert they are married.
+
+ j = John
+ E xy = being earlier than
+ C (x, t) = being a child at t
+ A (x, t) = being an adult at t
+ S (x, t) = being a senior at t
+ ∃t1∃t2∃t3 (C (j, t1) ∧ A (J, t2) ∧ S(J, t3) ∧ E (t1, t2) ∧ E (t1, t3))
+
+ (d) Goofus and Gallant have been married for three years; for each day of that span,
+ it is true to assert they are married.
+
+ Again, notice we are not modeling that Goofus and Gallant are married to each other.
+ M(x, t) = being married at t
+ Y(t) = belongs to 3 year span 1
+ g1 = Goofus
+ g2 = Gallant
+ D(t) = t is a day
+ ∀t(D(t) ∧ Y(t)→(M(g1,t) ∧ M(g2,t)))
+
```
-5. Using BFO and RO, model the following scenario: the content of an rdf file is represented in two serializations - one in Turtle, one in XML - which are sent from one computer to two distinct computers on the same network.
+5. Using BFO and RO, model the following scenario: the content of an rdf file is represented
+in two serializations - one in Turtle, one in XML - which are sent from one computer to two
+distinct computers on the same network.
+
+RDF File Content, Turtle and XML are all generically dependent continuants.
+RDF File Content has_model in Turtle and XML. And they are all carried by Computer.
+Computer 1 enables the process of Data Transmission, which ends_with another process,
+Data Reception, which has computers 2 and 3 as participants. So this part is intended to show
+that there is some data (Turtle and XML) which are sent from Computers 1 to Computer 2 and 3.
+Finally, computers 1, 2, and 3 are all parts_of network I,
+which is instance_of Object Aggregate.)
+
+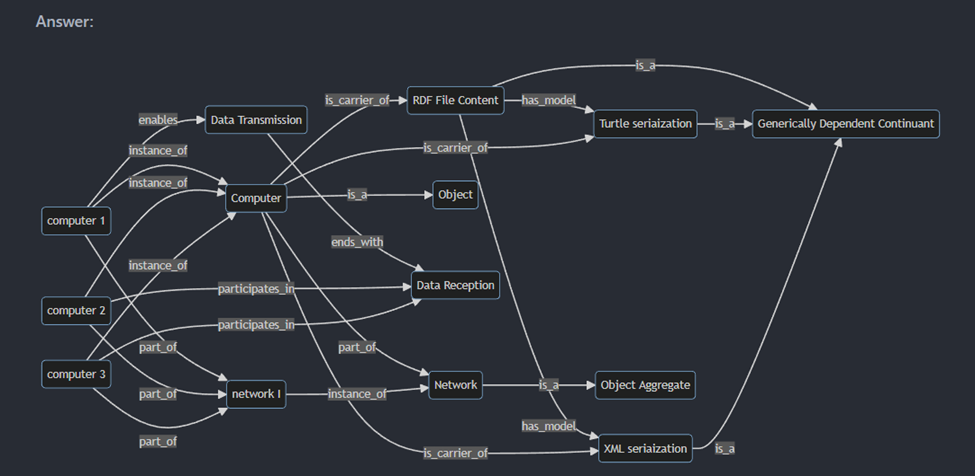
6. Using Protege, place these in the BFO hierarchy where you think they fit best:
```
+ Some of these questions are of course ambigous. In a real-life situation, we would talk with
+ the domain experts/ client who asked us to build the ontology and understand what of the
+ options they are meaning.
+
(a) Bach's Well-Tempered Clavier
+ Generically dependent continuant, or a process (the execution), or even an object (the sheets)
(b) Chair of the UB Philosophy Department
- (c) SARS-CoV-2
+ Role
+ (c) SARS-COV-2
+ Object (apparently we use this term to refer to the virus, not the disease/ disorder)
(d) Mexico City
+ Object aggregate, but could also be a two- or three-dimensional spatial region
+ (the region where the city is located) or a site (the empty space where people roam)
(e) The trunk of a minivan
+ Site (the empty space inside the trunk). Or an object/ object aggregate.
(f) Occupation
+ Role
(g) Ocean
+ Object aggregate, but could also be a two- or three-dimensional spatial region (the region the
+ ocean occupies) or a site (the empty space where water goes).
(h) Lake
-```
+ Object aggregate, but could also be a two- or three-dimensional spatial region (the region the
+ Lake occupies) or a site (the empty space where water goes).
+ ```
7. True or False; explain your answers:
```
(a) An instance of Material Entity can have an instance of Immaterial Entity as part.
+ True (see BS book pag. 108)
(b) An instance of Immaterial Entity can have an instance of Material Entity as part.
+ False by def. and by some properties in the ontology.
(c) An organization may have another organization as part.
+ True. A committee can have a subcommittee as a part.
(d) An organization may have no members as part.
+ If organizations are object aggregates, this is false.
+ If we think about it as a role, or roles borne by e.g. the members, then it seems they
+ can continue to exist, and this is true.
(e) Any site is partially bounded by some instance of Material Entity.
+ False. Part two of the definition of BFO 2020 is vague enough to allow such cases.
(f) A book placed under the leg of a wobbly table has acquired a new function.
+ False. Functions are 1) depending on changes in the physical structure, which has not changed,
+ and 2) depending on the intentions of the maker for artifacts.
+ Being under the leg of a table is not the intended function for which the book
+ was created. Even if this were the case, it would get the function when it came into existence.
(g) A glass vase cushioned with packing material for all time, has the disposition to break.
+ True. A disposition is held even if unlikely to ever be realized.
(h) Spacetime is a class in BFO.
- (i) The continuant fiat boundary class of BFO is closed, meaning, there are no subclasses beyond those identified presently in BFO.
+ False. Spatiotemporal regions are.
+ (i) The continuant fiat boundary class of BFO is closed, meaning, there are no subclasses
+ beyond those identified presently in BFO.
+ False. "Continuant fiat boundary doesn't have a closure axiom because the subclasses
+ don't necessarily exhaust all possibilities. An example would be the mereological sum of
+ two-dimensional continuant fiat boundary and a one dimensional continuant fiat boundary that
+ doesn't overlap it" (from a previous version of the BFO file in Protege)
```
-8. Model the following scenario in BFO, introducing whatever terms are needed to do so: John runs for 3 hours, startin slowly, speeding up during the middle, then ending the run at a slower pace.
+8. Model the following scenario in BFO, introducing whatever terms are needed to do so: John
+runs for 3 hours, startin slowly, speeding up during the middle, then ending the run at a
+slower pace.
+
+John (as an Object) participates_in John’s running (as a process), and John is bearer of
+John’s speed 1, 2, and 3, all of which are instances of qualities.
+John’s running includes 3 temporal parts: John’s beginning stage, John’s middle stage,
+and John’s final stage, each of which is a process. Besides, John’s beginning stage precedes
+John’s middle stage which precedes John’s final stage.
+John’s running occurs_in this 3-hour, which is instance_of one-dimensional temporal region.
+This 3-hour also includes 3 temporal parts: t1, t2, and t3, each of which is also instance_of
+one-dimensional temporal region. Besides, t1 precedes t2, and t2 precedes t3. Moreover, John’s
+beginning stage occurs_in t1, John’s middle stage occurs_in t2, and John’s final stage
+occurs_in t3.
+Change in John’s speed: John's Speed 1 is decreased_in_magnitude_relative_to John's Speed 2
+(that is, speed 1<speed 2), and John's Speed 2 is increased_in_magnitude_relative_to John's
+Speed 3 (that is, speed 2>speed 3).
+
+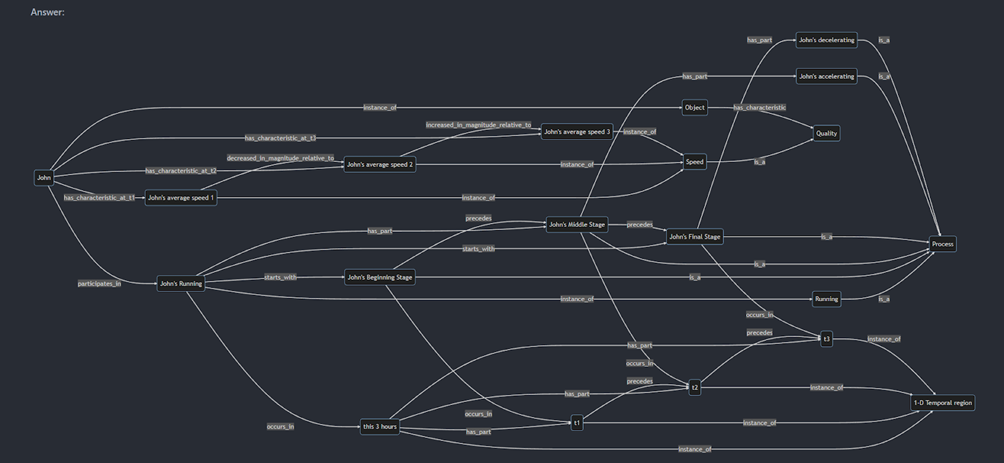
+
+9. The Pellet reasoner in Protege can be used in an incremental reasoning strategy.
+ELI5 when and why one should use Pellet for incremental reasoning.
+
+Imagine you are playing with some building blocks to build a tower. Every time you add a
+block to the tower, you don't need to start building the tower from the beginning.
+You just need to add the new block on top of the tower. n the same way, when we use Pellet
+to reason about an ontology, we don't need to start reasoning from the beginning every time
+we add new information to the ontology. Instead, Pellet remembers what it has already figured
+out and uses that knowledge to figure out what the new information means. This is kind of like
+adding a new block to the tower without starting from the beginning. Thus, Pellet is especially
+important for large, complex ontologies where re-computing all the results every time new
+information is added would take a long time.
+
+(Thanks to OpenAI for providing the basis for this)
+
+10. Protege reasoners will not allow you to combine certain properties, e.g. reflexivity and
+transitivity. If you attempt to assert such pairs of the same object property, then run the
+reasoner, nothing will happen. If you combine such properties while a reasoner is running, then
+ask to synchronize the reasoner, an error will be thrown. Provide a table or series of tables
+illustrating which pairs of properties cannot be combined in Protege, either because nothing
+when the reasoenr is run or because an error is thrown when synchronizing a reasoner after
+making such changes. Review the github docs on [creating tables in markdown]
+https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/organizing-information-with-tables).
+
+ |Functional|InverseFun|Transitive|Symmetric|Asymmetric|Reflexive|Irreflexive|
+|Functional| (empty) | YES | NO | YES | YES | YES | YES |
+|InverseFun| YES | (empty) | NO | YES | YES | YES | YES |
+|Transitive| NO | NO | (empty) | YES | NO | YES | NO |
+|Symmetric | YES | YES | YES | (empty) | NO | YES | YES |
+|Asymmetric| YES | YES | NO | NO | (empty) | NO | YES |
+|Reflexive | YES | YES | YES | YES | NO | (empty) | NO |
+|Irreflex | YES | YES | NO | YES | YES | NO | (empty) |
+
+Note: In the above table, there are 21 different sorts of possibilities in total. We use
+"Yes" to represent a case where a pair of object property characteristics can be combined,
+and "No" to represent a case where a pair of object property characteristics cannot be combined.
+As a result, we find that there are 7 sorts of cases where a pair of object property
+characteristics cannot be combined: (1) The following 3 pairs cannot be combined because of a
+logical contradiction: Asymmetric & Reflexive, Asymmetric & Symmetric, and Reflexive &
+Irreflexive. (2) The following 4 pairs cannot be combined because of a more subtle factor.
+That is, an assertion of transitivity leads to a result that the target object property becomes
+non-simple (see Baader's book: section 8.1, page 211), so it is beyond the capacity limit of
+the reasoner: Transitive & Functional, Transitive & Inverse Functional, Transitive & Asymmetric,
+and Transitive & Irreflexive.
-9. The Pellet reasoner in Protege can be used in an incremental reasoning strategy. ELI5 when and why one should use Pellet for incremental reasoning.
-10. Protege reasoners will not allow you to combine certain properties, e.g. reflexivity and transitivity. If you attempt to assert such pairs of the same object property, then run the reasoner, nothing will happen. If you combine such properties while a reasoner is running, then ask to synchronize the reasoner, an error will be thrown. Provide a table or series of tables illustrating which pairs of properties cannot be combined in Protege, either because nothing happens when the reasoenr is run or because an error is thrown when synchronizing a reasoner after making such changes. Review the github docs on [creating tables in markdown](https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/organizing-information-with-tables).