{kind=link}
🔥🔥 [2026] News: We now open-source our private inference code at https://github.com/Tianshi-Xu/SEC-PPDL
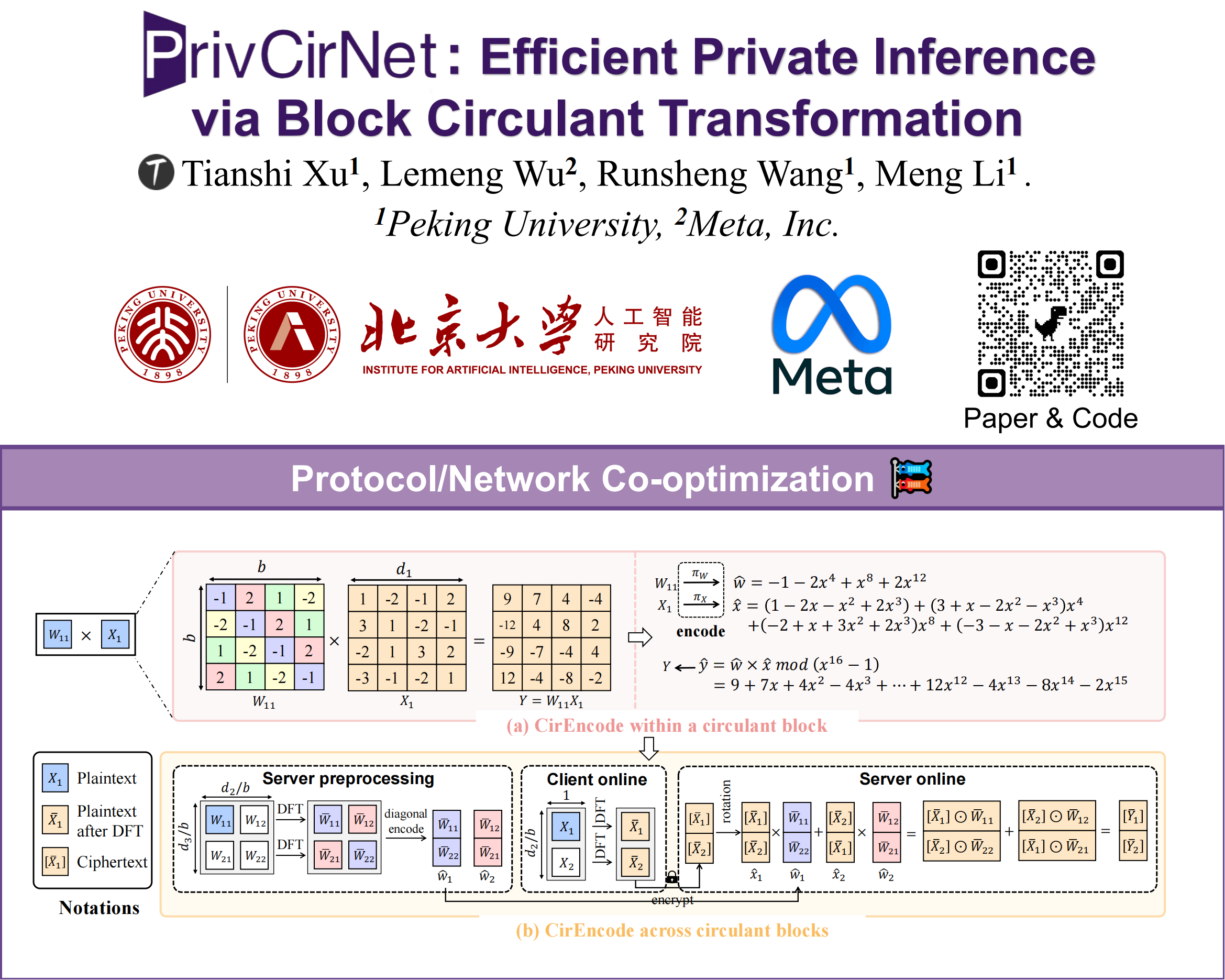
🔥 Introducing a network-protocol co-optimization framework for accelerating homomorphic encrypted network inference.
We provide PrivCirNet models which can be downloaded here.
- Install
torch>=2.0.0,python>=3.10. - Install other pip packages via
pip install -r requirements.txt. - Prepare the dataset including CIFAR-10, CIFAR100, Tiny ImageNet and ImageNet.
In this step, we load the pretrained model and get the layer-wise block sizes configuration. The script is ILP.sh. For example, to configure ViT on CIFAR-10, you can run the following command:
CUDA_VISIBLE_DEVICES=1 python CirILP.py -c configs/datasets/ViT/cifar10_ILP.yml --model vit_7_4_32 PATH_TO_CIFAR10A log file named vit_c10_ILP.log will be created to save the configuration and logs. You will get the layer-wise block sizes configuration in the log file.
There are two parameters in the .yml file you need to specify:
- budget. You can set the budget to
2,4, and8whose latency is less than that of networks with uniform block size2,4, and8. - better_initialization.
Truemeans use the initialization method proposed in PrivCirNet,Falsemeans use the previous initialization method, i.e.,$\min |W'-W|_2^2$ .
In this step, we load the pretrained model and train the circulant models with the layer-wise block sizes configuration obtained from the previous step.
This step is simple which is the same as training the original models. The script is train_cir.sh. For example , to train ViT on CIFAR-10, you can run the following command:
CUDA_VISIBLE_DEVICES=1 python train_cir.py -c configs/datasets/ViT/cifar10_fix.yml --model vit_7_4_32 PATH_TO_CIFAR10A log file named your_log_name.log will be created to save logs. The checkpoints will be saved in the output folder. There are several parameters in the .yml file you need to specify:
fix_blocksize_list. It is the block size configuration you get from the previous step. It must be separated by commas.log_name. The name of the log file.use_kd. Whether to use knowledge distillation. IfTrue, you need to specify theteacher_modelandteacher_checkpointin the.ymlfile.initial_checkpoint. You must load the initial checkpoint from the original model. All initial checkpoints can be downloaded here.
This repository also provides the training scripts for the two baselines:
- Uniform block size circulant networks. The training script is the same as
Train the circulant modelswhere you can setfix_blocksizeto2,4, and8to train uniform block size circulant networks. - SpENCNN (structured pruning). The training script is
train_prune.sh. For example, to train MobileNetV2 on CIFAR-10, you can run the following command:
CUDA_VISIBLE_DEVICES=1 python train_prune.py -c configs/datasets/Prune/cifar10.yml --model c10_prune_mobilenetv2 PATH_TO_CIFAR10- You can set
prune_ratioin the.ymlfile to specify the pruning ratio. - Pruning models can be downloaded here.
This project is licensed under the MIT License - see the LICENSE file for details.
If our work assists your research, feel free to give us a star ⭐ or cite us using:
@inproceedings{NEURIPS2024_ca987391,
author = {Xu, Tianshi and Wu, Lemeng and Wang, Runsheng and Li, Meng},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Globerson and L. Mackey and D. Belgrave and A. Fan and U. Paquet and J. Tomczak and C. Zhang},
pages = {111802--111831},
publisher = {Curran Associates, Inc.},
title = {PrivCirNet: Efficient Private Inference via Block Circulant Transformation},
url = {https://proceedings.neurips.cc/paper_files/paper/2024/file/ca9873918aa72e9033041f76e77b5c15-Paper-Conference.pdf},
volume = {37},
year = {2024}
}